
Redis 之深入江湖-複製原理
一.前言
上一篇文章Redis 之複製-初入江湖中,講了關於Redis複製配置,如:如何建立配置、如何斷開復制、關於連結的安全性等等,那麼本篇文章將深入的去說一下關於Redis複製原理,如下:
- 複製過程
- 資料同步
- 全量複製
- 部分複製
- 心跳
- 非同步複製
二.複製過程
在從節點執行slaveof命令後,複製過程便開始運作,下面將會詳細的講解建立複製的完整流程,如下圖所示:
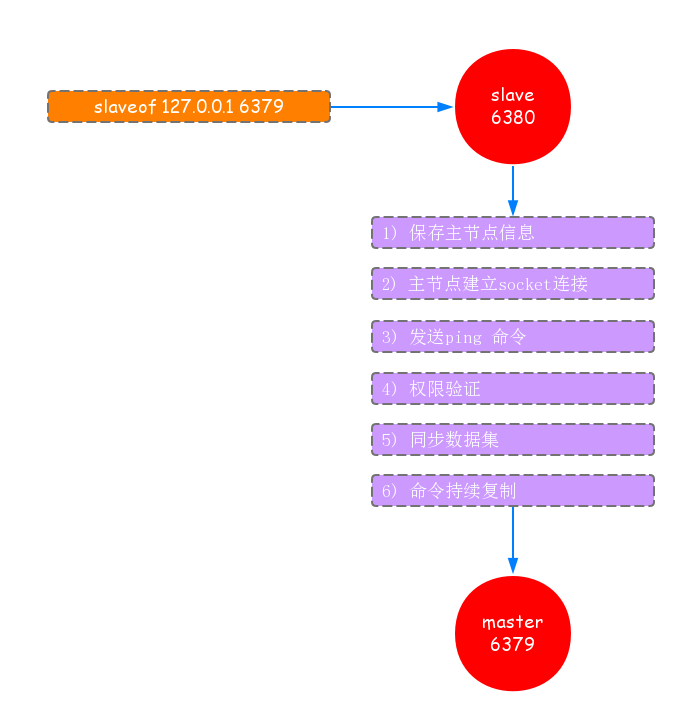
從上圖中,可以看出複製的一個大致流程:
- 儲存master(主節點)資訊:從節點執行slaveof後只儲存主節點的地址資訊後便直接返回,這時建立複製的流程還沒開始.
- slave(從節點)內部通過每秒執行的定時任務維護複製相關邏輯,當定時任務發現存在新的主節點後,從節點會建立一個socket連線主節點.如果從節點無法建立連線,定時任務會無限重試直到連線成功,或者執行slaveof no one取消複製.
- 傳送ping命令,如果傳送ping命令後(目的:1)檢測主從之間網路套節字持否可用;2)檢測主節點當前是否可接受處理命令),從節點沒有收到主節點的pong回覆或者連線超時,比如網路超時或者主節點阻塞無法響應,從節點會斷開復制連線,下次定時任務會繼續發起重連.
- 許可權驗證.如果主節點設定了requirepass引數,那麼就需要密碼進行許可權驗證;如果驗證失敗,複製將終止.從節點會重新發起復制流程.
- 同步資料集.許可權驗證通過後,進行資料同步,對於首次建立複製的場景,主節點會把持有的資料全部發給從節點,這個操作耗時最長.(在Redis2.8版本之後,同步操作分兩種情況:全量和部分,下面將會說到)
- 命令持續複製.當主節點把當前所有資料同步給從節點後,便完成了複製的整個流程,後面主節點將持續把寫命令發給從節點,以保持資料的一致性.
三.資料同步
在上面的複製整個流程中,有一個步驟是“同步資料集”,這個通過過程分為:全量複製和部分複製.
全量複製:一般用於初次複製場景,Redis早期支援的複製功能便只有全量複製,它會把主節點的所有資料一次性發給從節點,當資料量較大時,這會給主從節點之間的各個方面帶來很大的開銷.
部分複製:用於處理在主從複製中因網路閃斷等原因造成資料丟失的場景,當從節點再次連上主節點後,如果條件允許,主節點會補發之前丟失的資料給從節點.因為補發的資料遠遠小於全量資料,可以有效的避免複製過程中的過高開銷.
Redis的同步有2個命令,分別是:sync 和 psync,前者是 redis 2.8 之前的同步命令,後者是 redis 2.8 為了優化 sync 新設計的命令.我們會重點關注 2.8版本以後的 psync 命令.psync 命令的執行需要三個元件支援:(1)主從節點各自複製偏移量;(2)主節點複製積壓緩衝區;(3)主節點執行id.
1).主從節點的複製偏移量
1.參與複製的主從節點都會維護自身複製偏移量.統計資訊在使用info replication命令檢視中的master_repl_offset指標中.
2.從節點(slave)每秒鐘上報自身複製偏移量給主節點,因此主節點也會儲存從節點的偏移量.
3.從節點在接收到主節點發送的命令後,也會累加自身的偏移量.
4.通過對比主從節點的複製偏移量,可以判斷主從節點資料是否一致,如下圖所示.
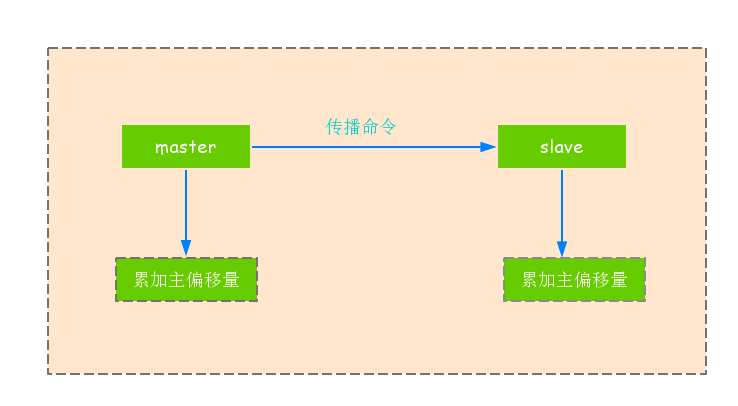
注:可以通過主節點的統計資訊,計算出master_repl_offset-slave_offset位元組量,判斷主從節點複製相差的資料量,根據這個產值判定當前複製的健康度.如果主從之間複製偏移量相差較大,則可能是網路延遲或命令阻塞等原因引起的.
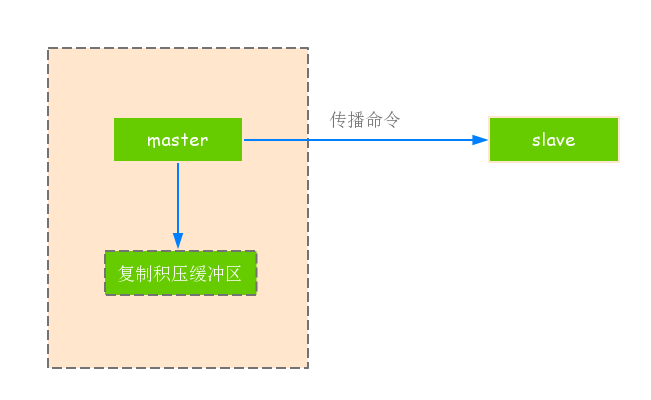
2).複製積壓緩衝區
(1)複製積壓緩衝區是儲存在主節點上的一個固定長度的佇列,預設大小為1MB.當主節點有連線的從節點(slave)被建立時,這時主節點(master)響應寫命令時,不但會把命令傳送給從節點,還會寫入複製積壓緩衝區,如下圖所示.
(2)由於緩衝區本質上是先進先出的定長佇列,所以能實現儲存最近已複製資料的功能,用於部分複製和複製命令丟失的資料補救,可以通過 info replication 檢視相關資訊.
3).主節點執行ID
(1)每個Redis節點啟動後都會動態分配一個40位的十六進位制字串作為執行ID.
(2)執行ID的主要作用是用來唯一識別的Redis節點,比如從節點儲存主節點執行ID識別自己正在複製的是哪個主節點.如果只是使用ip+port的方式識別主節點,那麼主節點重啟變更了整體資料集(如替換RDB/AOF檔案),從節點再基於偏移量複製資料將是不安全的,因此當執行ID變化後從節點將做全量複製.
(3)上面提到的是主節點重啟變更,那麼重啟不改變執行ID呢?這時可以使用 debug reload 命令重新載入RDB並保持執行ID不變,從而有效避免不必要的全量複製.
注:debug reload命令會阻塞當前Redis節點主執行緒,阻塞期間會生成本地RDB快照並清空資料之後再載入RDB檔案.因此對於大量資料的主節點和無法容忍阻塞的應用場景,是要謹慎使用的.
4).psync命令
從節點使用psync命令完成部分複製和全量複製功能.命令格式:psync {runId} {offset},其引數含義如下:
- runId:從節點所複製主節點的執行ID
- offset:當前從節點已複製的資料偏移量
psync的執行流程如下:

流程說明:
- slave(從節點)傳送sync命令給主節點,引數runId是當前從節點儲存的主節點執行ID,如果沒有則預設為-1.offset 是從節點儲存的複製偏移量,如果是第一次複製則為 -1.
- master(主節點)根據sync引數和自身資料的情況決定響應結果:
- 如果回覆+FULLRESYNC {runId} {offset} ,那麼從節點將觸發全量複製流程。
- 如果回覆 +CONTINUE,從節點將觸發部分複製.
- 如果回覆 +ERR,說明主節點不支援 2.8 的 psync 命令,將使用 sync 執行全量複製.
四.全量複製
全量複製是Redis最早支援的複製方式,也是主從第一次建立複製是必須要走的流程.觸發全量複製的命令是 sync 和 psync.前面已經說過,redis 2.8 之前使用 sync 只能執行全量不同, 之後同時支援全量同步和部分同步.
流程如圖:
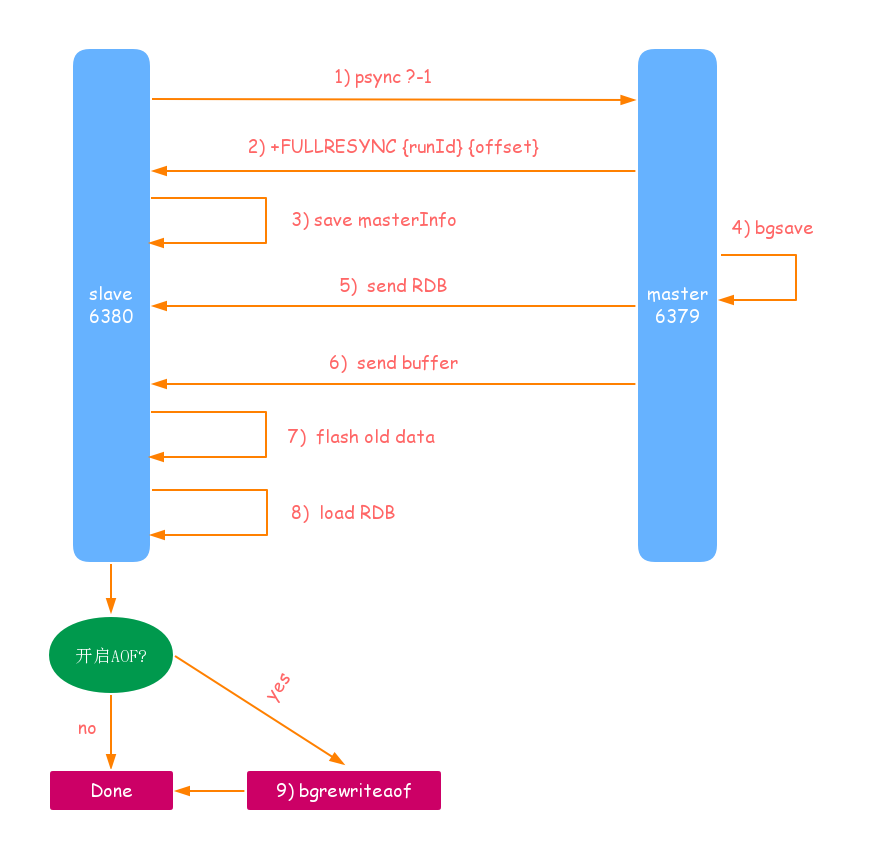
流程說明:
- 傳送psync命令進行同步資料,由於是第一次進行復制,從節點還沒有複製偏移量和主節點執行ID,所以傳送:psysc ?-1.
- 主節點根據psysc ?-1 當前為全域性複製,回覆 +FULLRESYNC 響應.
- 從節點接受主節點的響應並儲存執行ID和offset.
- 主節點執行 bgsave 並儲存 RDB 到本地.
- 主節點發送RDB檔案到從節點,從節點把所接收的RDB檔案儲存到本地,並將其作為從節點的資料檔案.
- 對於從節點接受RDB檔案快照到完成期間,主節點依然響應讀寫命令,因此主節點會把這段時間內的資料儲存到複製客戶端緩衝區內,當從節點載入完RDB檔案後,主節點會再把緩衝區內的資料發給從節點,保證主從之間資料一致性.
- 從節點接受完主節點傳來的全部資料後,會清空自身舊資料.
- 從節點清空資料後開始載入RDB檔案,對於較大的RDB檔案,這一步還是非常耗時的.
- 從節點成功載入完 RBD 後,如果當前節點開啟了 AOF,會立刻做 bgrewriteaof操作.
以上加粗的部分是整個全量同步耗時的地方.
注:
- 如果線上RDB 檔案資料量在 6G左右的主節點,並且是千兆網絡卡,Redis 的預設超時機制(60 秒),會導致全量複製失敗.可以通過調大 repl-timeout 引數來解決此問題.
- Redis 雖然支援無盤複製,生成的RDB檔案不儲存到本地,而是直接通過網路傳送給從節點,不過無盤複製還處於試驗階段,所以生產環境一定慎用。
五.部分複製
部分複製主要是Redis針對全量複製的過高開銷,所做的一些優化.在slave(從節點)正在向master(主節點)時,如果出現網路閃斷或者命令丟失等異常情況發生時,從節點會向主節點要求補發丟失的命令資料,如果主節點的複製積壓緩衝區記憶體在這部分,則直接打給從節點,這樣便可以保持主從節點複製的一致性.補發的這部分資料遠遠小於全量資料,所以開銷很小.部分複製流程圖如下:
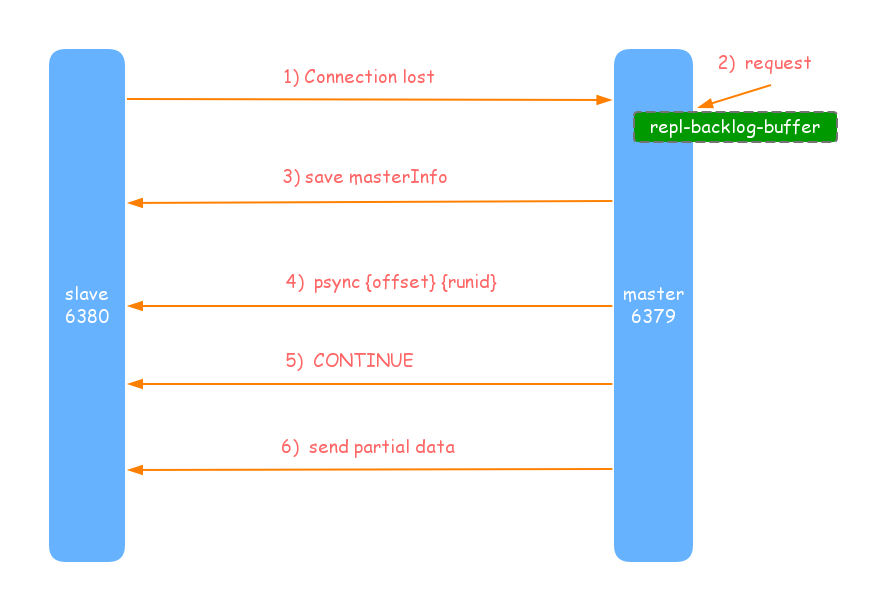
- 當主從節點之間網路出現中斷時,如果超過repl-timeout時間,主節點會認為從節點故障並中斷複製連線.
- 主節點連線中斷期間,主節點依然響應命令,但因複製連線中斷命令無法傳送給從節點,不過主節點內部存在複製積壓緩衝區,依然可儲存最近一段時間的資料,預設為1MB.
- 當從節點網路恢復後,從節點會在此連上主節點.
- 當主從連線恢復後,因為之前從節點儲存了自身已複製的offset和執行ID,所以會把把其當作psync引數發給主節點.
- 主節點連線到psync命令後,首先核對引數runId是否一致,如果一致說明之前複製的是當前主節點,然後根據offset引數在自身複製積壓緩衝區中進行查詢,如果偏移量之後的資料存在緩衝區中,則想從節點發送 +CONTINUE 響應,表示進行部分複製.
- 主節點根據偏移量吧複製積壓緩衝區裡資料發給從節點,以保證主從複製進入正常狀態.
六.心跳
主從節點在建立複製後,他們之間維護著長連線,並且彼此傳送心跳.如圖:
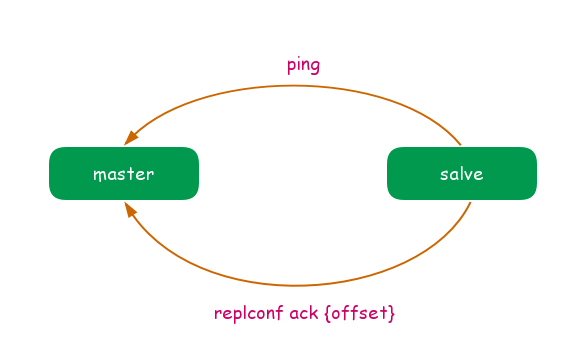
主從心跳判斷機制:
- 主從節點彼此都有心跳檢測機制,各自模擬成對方的客戶端急性通訊,通過 client list 命令檢視複製相關客戶端資訊,主節點的連線狀態為 flags = M,從節點的連線狀態是 flags = S.
- 主節點預設每隔10秒對從節點發送ping命令,判斷從節點的存活狀態和連線狀態,可通過修改配置 repl-ping-slave-period 控制傳送頻率.
- 從節點在主執行緒每隔1秒傳送 replconf ack{offset} 命令,給主節點上報自身當前的複製偏移量.
- 主節點收到 replconf 資訊後,判斷從節點超時時間,如果超過 repl-timeout 設定的值(預設值為60 秒),則判斷從節點下線,並斷開復制客戶端連線.
replconf的作用:
- 實時監測主從節點的網路狀態
- 上報自身的偏移量,檢查複製資料是否丟失
- 實現保證從節點的數量和延遲功能,通過min-slaves-to-write,min-slaves-max-lag引數配置定義
注意:為了降低主從延遲,一般把 Redis 主從節點部署在相同的機房/同城機房,避免網路延遲帶來的網路分割槽造成的心跳中斷等情況.
七.非同步複製
主節點不但負責資料讀寫,還負責把寫命令同步給從節點.寫命令的傳送過程是非同步完成的,也就是說主節點自身處理完寫命令後直接返回給客戶端,並不等待從節點複製完成,如下圖所示:
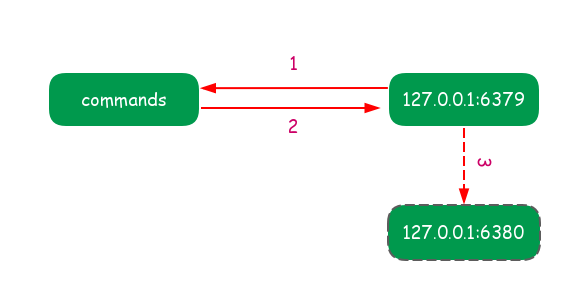
非同步複製的流程如下:
- 主節點接受處理命令
- 命令處理完之後返回響應結果
- 對於修改命令非同步傳送給從節點,從節點在主執行緒中執行復制的命令.
八.回顧
本篇文章,大略分析了下複製過程、資料同步、全量複製、部分複製、心跳、非同步複製等方面的原理.
參考:《Redis開發與運維》
版權宣告:尊重博主原創文章,轉載請註明出處 https://www.cnblogs.com/hsdy