scrapy抓取拉勾網職位資訊(一)——scrapy初識及lagou爬蟲專案建立
本次以scrapy抓取拉勾網職位資訊作為scrapy學習的一個實戰演練
python版本:3.7.1
框架:scrapy(pip直接安裝可能會報錯,如果是vc++環境不滿足,建議直接安裝一個visual studio一勞永逸,如果報錯缺少前置依賴,就先安裝依賴)
本篇主要對scrapy生成爬蟲專案做一個基本的介紹
tips:在任意目錄開啟cmd的方式可以使用下面這兩種方式
- shift + 右鍵開啟cmd(window10的powershell你可以簡單理解為cmd升級版)
- 在路徑框直接輸入cmd,回車
1、建立一個scrapy專案
在cmd視窗中輸入:scrapy startproject lagou,這樣就建立了一個專案資料夾,資料夾的名字是lagou

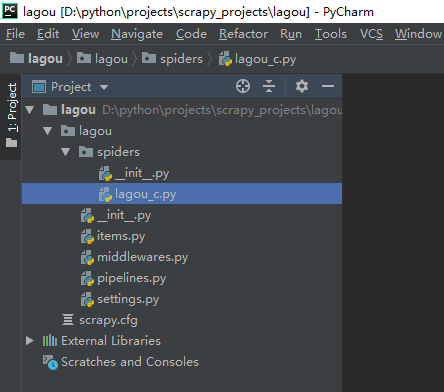
新生成一個scrapy專案,但是目前裡面還沒有一個爬蟲,用pycharm開啟外層lagou資料夾看看

從結構可以看出生成的lagou專案資料夾裡面生成了一些新的資料夾和檔案,
__init__.py:兩個檔案內容都是空的,存在的唯一目的就是讓它所在的資料夾成為一個python包。
items.py:主要是用來定義要提取的欄位的,比如我們要提取招聘職位的名稱,薪酬,都需要對欄位進行定義
middlewares.py:中介軟體,包括spider middleware和downloader middleware,前者可以對請求進行修改(比如加入代理,設定UA都可以在這裡進行),後者可以對下載的頁面進行修改
pipelines.py:主要是用來進行資料清洗,儲存的
settings.py:爬蟲專案的全域性配置,比如全域性的UA,是否開啟middlewares中間鍵,設定延遲等
2、生成一個爬蟲(注意:一個專案資料夾下面可以有多個爬蟲)
首先進入到外層的lagou資料夾下
cd lagou
檢視有哪些爬蟲模板命令:scrapy genspider -l

一般用的比較多是basic和crawl兩種,basic適合主頁比較簡單,url基本一致的情況,crawl適合有多種標籤類別的網站
針對拉勾網,這裡我們選用crawl模板生成爬蟲,爬蟲名稱是lagou_c,爬取的首頁url是lagou.com
scrapy genspider -t crawl lagou_c lagou.com (-t crawl代表以crawl模板生成爬蟲,如果不加這個引數以basic模板生成的爬蟲scrapy genspider lagou_c lagou.com)
注意:爬蟲名稱一般設定為要爬取的url名稱,如lagou.com,設定為lagou為爬蟲名,但爬蟲名和專案名不能重複,我這裡修改爬蟲名為lagou_c

這樣我們就建立了一個名稱為lagou_c的爬蟲專案,再次用pycharm開啟可以看到多了一個lagou_c.py檔案,這個檔案就是爬蟲的入口,它主要是用來產生新的請求和對返回的response進行解析。