
MemCache詳細解讀(轉)
參考:https://www.cnblogs.com/xrq730/p/4948707.html
MemCache是什麼
MemCache是一個自由、原始碼開放、高效能、分散式的分散式記憶體物件快取系統,用於動態Web應用以減輕資料庫的負載。它通過在記憶體中快取資料和物件來減少讀取資料庫的次數,從而提高了網站訪問的速度。MemCaChe是一個儲存鍵值對的HashMap,在內
存中對任意的資料(比如字串、物件等)所使用的key-value儲存,資料可以來自資料庫呼叫、API呼叫,或者頁面渲染的結果。MemCache設計理念就是小而強大,它簡單的設計促進了快速部署、易於開發並解決面對大規模的資料快取的許多難題,而所開放的
API使得MemCache能用於Java、C/C++/C#、Perl、Python、PHP、Ruby等大部分流行的程式語言。
另外,說一下MemCache和MemCached的區別:
1、MemCache是專案的名稱
2、MemCached是MemCache伺服器端可以執行檔案的名稱
MemCache的官方網站為http://memcached.org/
MemCache訪問模型
為了加深理解,我模仿著原阿里技術專家李智慧老師《大型網站技術架構 核心原理與案例分析》一書MemCache部分,自己畫了一張圖:

特別澄清一個問題,MemCache雖然被稱為"分散式快取",但是MemCache本身完全不具備分散式的功能
快取資料),所謂的"分散式",完全依賴於客戶端程式的實現,就像上面這張圖的流程一樣。
同時基於這張圖,理一下MemCache一次寫快取的流程:
1、應用程式輸入需要寫快取的資料
2、API將Key輸入路由演算法模組,路由演算法根據Key和MemCache叢集伺服器列表得到一臺伺服器編號
3、由伺服器編號得到MemCache及其的ip地址和埠號
4、API呼叫通訊模組和指定編號的伺服器通訊,將資料寫入該伺服器,完成一次分散式快取的寫操作
讀快取和寫快取一樣,只要使用相同的路由演算法和伺服器列表,只要應用程式查詢的是相同的Key,MemCache客戶端總是訪問相同的客戶端去讀取資料,只要伺服器中還快取著該資料,就能保證快取命中。
這種MemCache叢集的方式也是從分割槽容錯性的方面考慮的,假如Node2宕機了,那麼Node2上面儲存的資料都不可用了,此時由於叢集中Node0和Node1還存在,下一次請求Node2中儲存的Key值的時候,肯定是沒有命中的,這時先從資料庫中拿到要快取的
資料,然後路由演算法模組根據Key值在Node0和Node1中選取一個節點,把對應的資料放進去,這樣下一次就又可以走快取了,這種叢集的做法很好,但是缺點是成本比較大。
一致性Hash演算法
從上面的圖中,可以看出一個很重要的問題,就是對伺服器叢集的管理,路由演算法至關重要,就和負載均衡演算法一樣,路由演算法決定著究竟該訪問叢集中的哪臺伺服器,先看一個簡單的路由演算法。
1、餘數Hash
比方說,字串str對應的HashCode是50、伺服器的數目是3,取餘數得到2,str對應節點Node2,所以路由演算法把str路由到Node2伺服器上。由於HashCode隨機性比較強,所以使用餘數Hash路由演算法就可以保證快取資料在整個MemCache伺服器叢集中有
比較均衡的分佈。
如果不考慮伺服器叢集的伸縮性(什麼是伸縮性,請參見大型網站架構學習筆記),那麼餘數Hash演算法幾乎可以滿足絕大多數的快取路由需求,但是當分散式快取叢集需要擴容的時候,就難辦了。
就假設MemCache伺服器叢集由3臺變為4臺吧,更改伺服器列表,仍然使用餘數Hash,50對4的餘數是2,對應Node2,但是str原來是存在Node1上的,這就導致了快取沒有命中。如果這麼說不夠明白,那麼不妨舉個例子,原來有HashCode為0~19的20個數
據,那麼:

如果我擴容到20+的臺數,只有前三個HashCode對應的Key是命中的,也就是15%。當然這只是個簡單例子,現實情況肯定比這個複雜得多,不過足以說明,使用餘數Hash的路由演算法,在擴容的時候會造成大量的資料無法正確命中(其實不僅僅是無法命中,那
些大量的無法命中的資料還在原快取中在被移除前佔據著記憶體)。這個結果顯然是無法接受的,在網站業務中,大部分的業務資料度操作請求上事實上是通過快取獲取的,只有少量讀操作會訪問資料庫,因此資料庫的負載能力是以有快取為前提而設計的。當大部
分被快取了的資料因為伺服器擴容而不能正確讀取時,這些資料訪問的壓力就落在了資料庫的身上,這將大大超過資料庫的負載能力,嚴重的可能會導致資料庫宕機。
這個問題有解決方案,解決步驟為:
(1)在網站訪問量低谷,通常是深夜,技術團隊加班,擴容、重啟伺服器
(2)通過模擬請求的方式逐漸預熱快取,使快取伺服器中的資料重新分佈
2、一致性Hash演算法
一致性Hash演算法通過一個叫做一致性Hash環的資料結構實現Key到快取伺服器的Hash對映,看一下我自己畫的一張圖:

具體演算法過程為:先構造一個長度為232的整數環(這個環被稱為一致性Hash環),根據節點名稱的Hash值(其分佈為[0, 232-1])將快取伺服器節點放置在這個Hash環上,然後根據需要快取的資料的Key值計算得到其Hash值(其分佈也為[0, 232-1]),然
後在Hash環上順時針查詢距離這個Key值的Hash值最近的伺服器節點,完成Key到伺服器的對映查詢。
就如同圖上所示,三個Node點分別位於Hash環上的三個位置,然後Key值根據其HashCode,在Hash環上有一個固定位置,位置固定下之後,Key就會順時針去尋找離它最近的一個Node,把資料儲存在這個Node的MemCache伺服器中。使用Hash環如果加了
一個節點會怎麼樣,看一下:
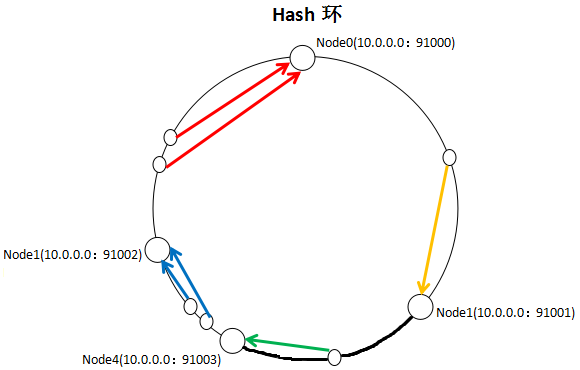
看到我加了一個Node4節點,隻影響到了一個Key值的資料,本來這個Key值應該是在Node1伺服器上的,現在要去Node4了。採用一致性Hash演算法,的確也會影響到整個叢集,但是影響的只是加粗的那一段而已,相比餘數Hash演算法影響了遠超一半的影響率,
這種影響要小得多。更重要的是,叢集中快取伺服器節點越多,增加節點帶來的影響越小,很好理解。換句話說,隨著叢集規模的增大,繼續命中原有快取資料的概率會越來越大,雖然仍然有小部分資料快取在伺服器中不能被讀到,但是這個比例足夠小,即使
訪問資料庫,也不會對資料庫造成致命的負載壓力。
至於具體應用,這個長度為232的一致性Hash環通常使用二叉查詢樹實現,至於二叉查詢樹,就是演算法的問題了,可以自己去查詢相關資料。
MemCache實現原理
首先要說明一點,MemCache的資料存放在記憶體中,存放在記憶體中個人認為意味著幾點:
1、訪問資料的速度比傳統的關係型資料庫要快,因為Oracle、MySQL這些傳統的關係型資料庫為了保持資料的永續性,資料存放在硬碟中,IO操作速度慢
2、MemCache的資料存放在記憶體中同時意味著只要MemCache重啟了,資料就會消失
3、既然MemCache的資料存放在記憶體中,那麼勢必受到機器位數的限制,這個之前的文章寫過很多次了,32位機器最多隻能使用2GB的記憶體空間,64位機器可以認為沒有上限
然後我們來看一下MemCache的原理,MemCache最重要的莫不是記憶體分配的內容了,MemCache採用的記憶體分配方式是固定空間分配,還是自己畫一張圖說明:

這張圖片裡面涉及了slab_class、slab、page、chunk四個概念,它們之間的關係是:
1、MemCache將記憶體空間分為一組slab
2、每個slab下又有若干個page,每個page預設是1M,如果一個slab佔用100M記憶體的話,那麼這個slab下應該有100個page
3、每個page裡面包含一組chunk,chunk是真正存放資料的地方,同一個slab裡面的chunk的大小是固定的
4、有相同大小chunk的slab被組織在一起,稱為slab_class
MemCache記憶體分配的方式稱為allocator,slab的數量是有限的,幾個、十幾個或者幾十個,這個和啟動引數的配置相關。
MemCache中的value過來存放的地方是由value的大小決定的,value總是會被存放到與chunk大小最接近的一個slab中,比如slab[1]的chunk大小為80位元組、slab[2]的chunk大小為100位元組、slab[3]的chunk大小為128位元組(相鄰slab內的chunk基本以
1.25為比例進行增長,MemCache啟動時可以用-f指定這個比例),那麼過來一個88位元組的value,這個value將被放到2號slab中。放slab的時候,首先slab要申請記憶體,申請記憶體是以page為單位的,所以在放入第一個資料的時候,無論大小為多少,都會
有1M大小的page被分配給該slab。申請到page後,slab會將這個page的記憶體按chunk的大小進行切分,這樣就變成了一個chunk陣列,最後從這個chunk陣列中選擇一個用於儲存資料。
如果這個slab中沒有chunk可以分配了怎麼辦,如果MemCache啟動沒有追加-M(禁止LRU,這種情況下記憶體不夠會報Out Of Memory錯誤),那麼MemCache會把這個slab中最近最少使用的chunk中的資料清理掉,然後放上最新的資料。針對MemCache的內
存分配及回收演算法,總結三點:
1、MemCache的記憶體分配chunk裡面會有記憶體浪費,88位元組的value分配在128位元組(緊接著大的用)的chunk中,就損失了30位元組,但是這也避免了管理記憶體碎片的問題
2、MemCache的LRU演算法不是針對全域性的,是針對slab的
3、應該可以理解為什麼MemCache存放的value大小是限制的,因為一個新資料過來,slab會先以page為單位申請一塊記憶體,申請的記憶體最多就只有1M,所以value大小自然不能大於1M了
再總結MemCache的特性和限制
上面已經對於MemCache做了一個比較詳細的解讀,這裡再次總結MemCache的限制和特性:
1、MemCache中可以儲存的item資料量是沒有限制的,只要記憶體足夠
2、MemCache單程序在32位機中最大使用記憶體為2G,這個之前的文章提了多次了,64位機則沒有限制
3、Key最大為250個位元組,超過該長度無法儲存
4、單個item最大資料是1MB,超過1MB的資料不予儲存
5、MemCache服務端是不安全的,比如已知某個MemCache節點,可以直接telnet過去,並通過flush_all讓已經存在的鍵值對立即失效
6、不能夠遍歷MemCache中所有的item,因為這個操作的速度相對緩慢且會阻塞其他的操作
7、MemCache的高效能源自於兩階段雜湊結構:第一階段在客戶端,通過Hash演算法根據Key值算出一個節點;第二階段在服務端,通過一個內部的Hash演算法,查詢真正的item並返回給客戶端。從實現的角度看,MemCache是一個非阻塞的、基於事件的伺服器
程式
8、MemCache設定新增某一個Key值的時候,傳入expiry為0表示這個Key值永久有效,這個Key值也會在30天之後失效,見memcache.c的原始碼:
#define REALTIME_MAXDELTA 60*60*24*30static rel_time_t realtime(const time_t exptime) {if (exptime == 0) return 0;if (exptime > REALTIME_MAXDELTA) {if (exptime <= process_started)return (rel_time_t)1;return (rel_time_t)(exptime - process_started);} else {return (rel_time_t)(exptime + current_time);}}
這個失效的時間是memcache原始碼裡面寫的,開發者沒有辦法改變MemCache的Key值失效時間為30天這個限制。
MemCache指令彙總
上面說過,已知MemCache的某個節點,直接telnet過去,就可以使用各種命令操作MemCache了,下面看下MemCache有哪幾種命令:

stats指令解讀
stats是一個比較重要的指令,用於列出當前MemCache伺服器的狀態,拿一組資料舉個例子:
STAT pid 1023STAT uptime 21069937STAT time 1447235954STAT version 1.4.5STAT pointer_size 64STAT rusage_user 1167.020934STAT rusage_system 3346.933170STAT curr_connections 29STAT total_connections 21STAT connection_structures 49STAT cmd_get 49STAT cmd_set 7458STAT cmd_flush 0STAT get_hits 7401STAT get_misses 57..(delete、incr、decr、cas的hits和misses數,cas還多一個badval)STAT auth_cmds 0STAT auth_errors 0STAT bytes_read 22026555STAT bytes_written 8930466STAT limit_maxbytes 4134304000STAT accepting_conns 1STAT listen_disabled_num 0STAT threads 4STAT bytes 151255336STAT current_items 57146STAT total_items 580656STAT evicitions 0
這些引數反映著MemCache伺服器的基本資訊,它們的意思是:


stats slab指令解讀
如果對上面的MemCache儲存機制比較理解了,那麼我們來看一下各個slab中的資訊,還是拿一組資料舉個例子:
STAT1:chunk_size 96...STAT 2:chunk_size 144STAT 2:chunks_per_page 7281STAT 2:total_pages 7STAT 2:total_chunks 50967STAT 2:used_chunks 45197STAT 2:free_chunks 1STAT 2:free_chunks_end 5769STAT 2:mem_requested 6084638STAT 2:get_hits 48084STAT 2:cmd_set 59588271STAT 2:delete_hits 0STAT 2:incr_hits 0STAT 2:decr_hits 0STAT 2:cas_hits 0STAT 2:cas_badval 0...STAT 3:chunk_size 216...
首先看到,第二個slab的chunk_size(144)/第一個slab的chunk_size(96)=1.5,第三個slab的chunk_size(216)/第二個slab的chunk_size(144)=1.5,可以確定這個MemCache的增長因子是1.5,chunk_size以1.5倍增長。然後解釋下欄位的含
義:

看到這個命令的輸出量很大,所有資訊都很有作用。舉個例子吧,比如第一個slab中使用的chunks很少,第二個slab中使用的chunks很多,這時就可以考慮適當增大MemCache的增長因子了,讓一部分資料落到第一個slab中去,適當平衡兩個slab中的記憶體,避
免空間浪費。