
linux xshell jdk hadoop(環境搭建) 虛擬機器 安裝(大資料搭建環境)
【hadoop是2.6.5版本 xshell是6版本 jdk是1.8.0.131 虛擬機器是CentOS-6.9-x86_64-bin-DVD1.iso vmware10】
1.建立虛擬機器
第一步:在VMware中建立一臺新的虛擬機器。如圖2.2所示。
 圖2.2
圖2.2
第二步:選擇“自定義安裝”,然後單擊“下一步”按鈕,如圖2.3所示。
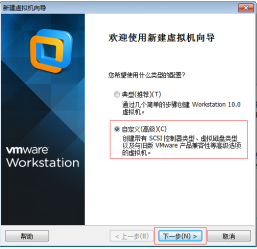 圖2.3
圖2.3
第三步:單擊“下一步” 按鈕,如圖2.4所示。
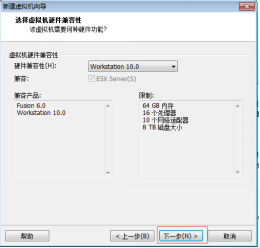 圖2.4
圖2.4
第四步:選擇“稍後安裝作業系統”,然後單擊“下一步” 按鈕,如圖2.5所示。
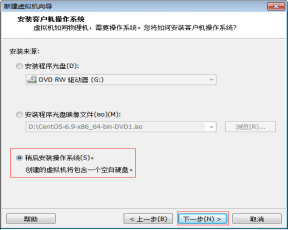 圖2.5
圖2.5
第五步:客戶機作業系統選擇
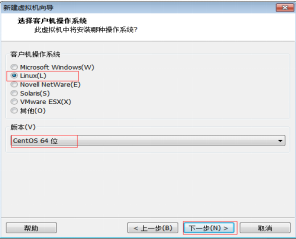 圖2.6
圖2.6
第六步:在這裡可以選擇“修改虛擬機器名稱”和“虛擬機器儲存的實體地址”,如圖2.7所示。
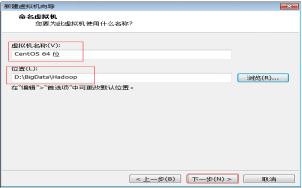 圖2.7
圖2.7
第七步:根據本機電腦情況給Linux虛擬機器分配“處理器個數”和每個處理器的“核心數量”。注意不能超過自己電腦的核數,推薦處理數量為1,每個處理器的核心數量為1,如圖2.8所示。
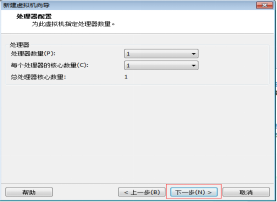 圖2.8
圖2.8
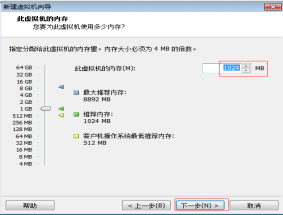
第八步:給Linux虛擬機器分配記憶體。分配的記憶體大小不能超過自己本機的記憶體大小,多臺執行的虛擬機器的記憶體總合不能超過自己本機的記憶體大小,如圖2.9所示。
第九步:使用NAT方式為客戶機作業系統提供主機IP地址訪問主機撥號或外部乙太網網路連線,如圖2.10所示。
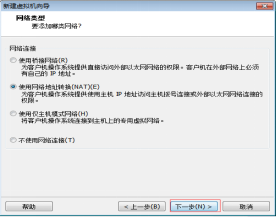 圖2.10
圖2.10
第十步:選擇“SCSI控制器為LSI Logic(L)”,然後單擊“下一步” 按鈕,如圖2.11所示。
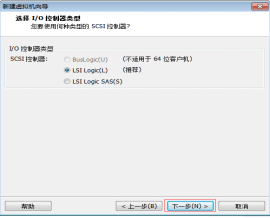 圖2.11
圖2.11
第十一步:選擇“虛擬磁碟型別為SCSI(S)”,然後單擊“下一步” 按鈕,如圖2.12所示。
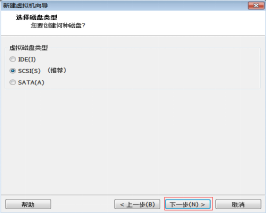 圖2.12
圖2.12
第十二步:選擇“建立新虛擬磁碟”,然後單擊“下一步” 按鈕,如圖2.13所示。
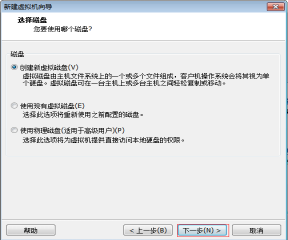 圖2.13
圖2.13
第十三步:根據本機的磁碟大小給Linux虛擬機器分配磁碟,並選擇“將虛擬機器磁碟拆分為多個檔案”,然後單擊
 圖2.14
圖2.14
第十四步:根據需要修改儲存磁碟檔案的位置。如果不更改,預設儲存在Linux虛擬機器安裝檔案目錄,如圖2.15所示。
 圖2.15
圖2.15
第十五步:單擊“完成”按鈕,完成新虛擬機器嚮導,如圖2.16所示。
 圖2.16
圖2.16
第十六步:在虛擬機器名字上單擊滑鼠右鍵,選擇“設定”來設定安裝的ISO檔案。選擇“CD/DVD à 使用ISO映象檔案”,選擇自己的映象檔案,然後單擊“確定”按鈕,如圖2.17所示。
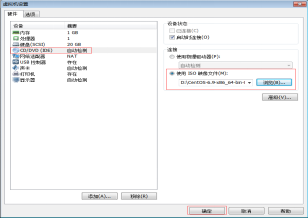 圖2.17
圖2.17
第十七步:開啟設定好的虛擬機器,進行Linux虛擬機器安裝,如圖2.18所示。
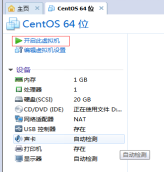 圖2.18
圖2.18
第十八步:選擇“不再顯示此訊息”,然後單擊“取消” 按鈕。
第十九步:進入到VMware虛擬機器選擇“Instell or upgrade an existing system”單擊“回車” 鍵進行安裝。或者不作任何操作,它將倒計時90秒後自動安裝。進入到VMware後可以用“Ctrl+Alt”組合鍵退出VMware,如圖2.19所示。
 圖2.19
圖2.19
第二十步:進入到安裝前測試頁面,通過方向鍵選擇“Skip”按鈕跳過測試,如圖2.20所示。
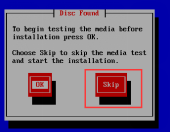 圖2.20
圖2.20
第二十一步:用滑鼠單擊“Next” 按鈕進行下一步操作,如圖2.21所示。
 圖2.21
圖2.21
第二十二步:用滑鼠選擇“中文簡體”,然後單擊“下一步”按鈕,如圖2.22所示。
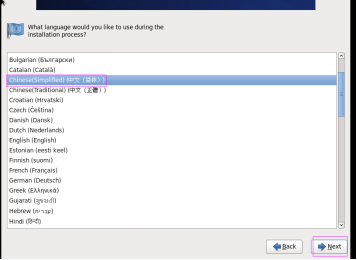
圖2.22
第二十三步:鍵盤選擇“美國英語式”,然後單擊“下一步” 按鈕,如圖2.23所示。
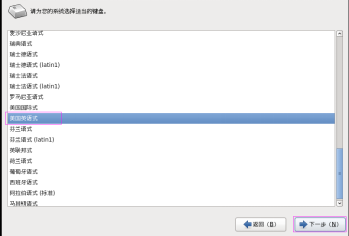
圖2.23
第二十四步:選擇“基本儲存裝置”,然後單擊“下一步” 按鈕,如圖2.24所示。
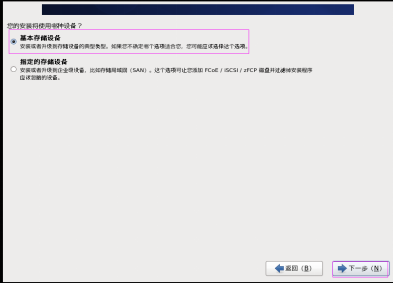
圖2.24
第二十五步:單擊“忽略所有資料” 按鈕,如圖2.25所示。
 圖2.25
圖2.25
第二十六步:設定Linux虛擬機器的“主本名”,然後單擊“下一步” 按鈕,如圖2.26所示。
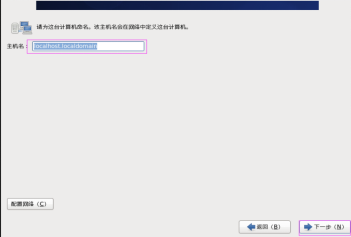 圖2.26
圖2.26
第二十七步:設定時間區域,勾選系統使用UTC時間,然後單擊“下一步”按鈕,如圖2.27所示。
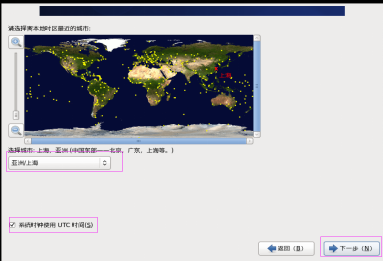 圖2.27
圖2.27
第二十八步:設定管理員使用者root的密碼,如圖2.28所示。(統一使用123456)
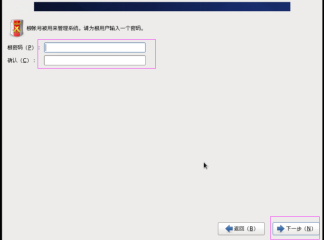 圖2.28
圖2.28
第二十九步:選擇“使用所有空間”,然後單擊“下一步”按鈕,如圖2.29所示。
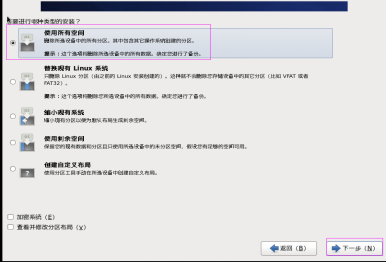 圖2.29
圖2.29
第三十步:單擊“將修改寫入磁碟”按鈕,如圖2.30所示。
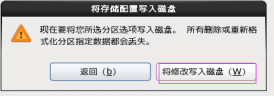 圖2.30
圖2.30
第三十一步:選擇Minimal,然後單擊“下一步” 按鈕。這裡安裝的是純命令列版,也可以安裝桌面版,可以選擇Desktop或者Minimal Desktop,如圖2.31所示。
 圖2.31
圖2.31
第三十二步:進行安裝介面,這裡一共需要安裝332個軟體包,如圖2.32所示。
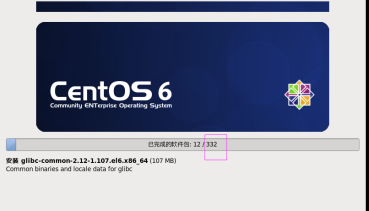 圖2.32
圖2.32
第三十三步:單擊“重新引導” 按鈕,完成安裝,如圖2.33所示。
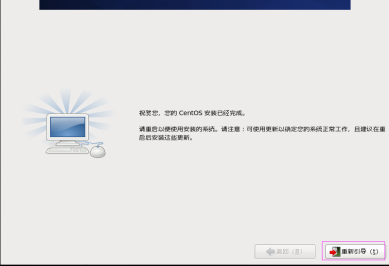
圖2.33
第三十四步:測試安裝是否成功。輸入使用者root和使用者密碼,如果能進入到如下介面,說明安裝成功,如圖2.34所示。
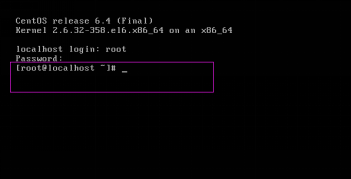 圖2.34
圖2.34
[[email protected] ~]#
root:是登入到Linux系統的使用者名稱。
localhost:是Linux系統的主機名。
~:是root使用者所在的位置。“~”是表示root的家目錄,root家目錄實際路徑是/home/root。
2.linux虛擬機器 安裝JDK和Hadoop
為在生產環境中hadoop大資料叢集是由多臺伺服器組成的叢集,為了方便學習這裡採用在VMware平臺中搭建虛擬機器的方式模擬hadoop大資料叢集。若要想實現hadoop大資料叢集環境,至少需要4臺虛擬機器,其中1臺Master節點,3臺Slave節點,每臺節點配置環境。為了實現hadoop叢集須有一臺Master節點和多臺Slave節點(其中IP地址第三段“153”需要跟自己的VMware工具平臺網段一致,可以通過在VMware工作平臺中單擊“編輯-->虛擬網路編輯器-->VMware8-->子網”來檢視)。

具體配置如表5.1所示。
表5.1 叢集節點資訊
| 主機名 |
IP地址 |
| Master001 |
192.168.153.200 |
| Slave001 |
192.168.153.201 |
| Slave002 |
192.168.153.202 |
| Slave003 |
192.168.153.203 |
1. 基礎資訊配置。
首先在一臺虛擬機器中設定基礎資訊,假設這臺虛擬機器為Master001。在基礎資訊中需要設定主機名、IP地址和名稱解析等配置,這些配置檔案只有root使用者才有改寫許可權,所以需要使用root使用者登入來編寫這些配置檔案。
1)修改主機名
通過編輯network檔案,將HOSTNAME值修改為新的主機名,具體操作如下。
[[email protected] ~]# vi /etc/sysconfig/network
改寫:
HOSTNAME=Master001
2)設定靜態IP
通過編輯ifcfg-eth0檔案來設定IP地址,具體操作如下。
[[email protected] ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
改寫:
ONBOOT=yes
BOOTPROTO=static
插入:
IPADDR=192.168.153.200
NETMASK=255.255.255.0
GATEWAY=192.168.153.2
DNS1=192.168.153.2
3)設定hosts
hosts檔案是Linux系統中負責IP地址與域名快速解析的檔案,需要配置其它的幾個節點的主機名和IP來快速訪問叢集中的其它節點。
具體操作如下:
[[email protected] ~]# vi /etc/hosts
插入:
192.168.153.200 Master001
192.168.153.201 Slave001
192.168.153.202 Slave002
192.168.153.203 Slave003
4)使設定生效
只是修改IP地址可以重啟網路服務即可以生效,操作如下:
[[email protected] ~]# service network restart
如果修改了主機名,必須重啟虛擬機器才能生效,操作如下:
[[email protected] ~]# reboot
5)驗證設定是否成功
啟動成功後資訊欄從“[[email protected] ~]#”變成了“[[email protected] ~]#”,這時主機名修改成功。
驗證IP地址設定是否成功可以通過ifconfig命令檢視IP地址,如果出現“eth0”網路名稱和IP地址,說明靜態IP設定成功,這時可以使用ping命令進一步驗證是否能聯通內網。,具體操作如下:
[[email protected] ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:45:78:7B
inet addr:192.168.153.101 Bcast:192.168.153.255 Mask:255.255.255.0
......
RX bytes:8610 (8.4 KiB) TX bytes:9849 (9.6 KiB)
lo Link encap:Local Loopback
net addr:127.0.0.1 Mask:255.0.0.0
......
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
[[email protected] ~]# ping 192.168.153.1 (此處的153 應改為你們 NAT 模式下子網的第三段)
PING 192.168.153.1 (192.168.153.1) 56(84) bytes of data.
64 bytes from 192.168.153.1: icmp_seq=1 ttl=128 time=0.450 ms
......
64 bytes from 192.168.153.1: icmp_seq=4 ttl=128 time=0.522 ms
^C
--- 192.168.153.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 4019ms
rtt min/avg/max/mdev = 0.450/0.501/0.572/0.055 ms
驗證外網是否聯通。VMware平臺中的虛擬是通過與虛擬機器共享主機的IP地址來訪問外網,虛擬機器要連線網路必須保證宿主機能夠正常訪問網路,虛擬機器是否能訪問外網可以通過“ping www.baidu.com”命令來驗證,如果能ping通百度說明外網訪問成功。
[[email protected] ~]# ping www.baidu.com
PING www.baidu.com (180.97.33.107) 56(84) bytes of data.
64 bytes from 180.97.33.107: icmp_seq=1 ttl=128 time=36.2 ms
......
64 bytes from 180.97.33.107: icmp_seq=6 ttl=128 time=41.2 ms
^C
--- www.baidu.com ping statistics ---
6 packets transmitted, 6 received, 0% packet loss, time 5729ms
rtt min/avg/max/mdev = 36.278/38.147/41.229/1.858 ms
6)建立普通使用者
計算機的操作難免會有失誤,如果關於核心的操作不當,就會對系統造成重大破壞,如一些工具不能使用,系統無法啟動等等。為了減少誤操作對系統造成的傷害,出於安全性需要建立普通使用者。
(1)建立使用者名稱叫hadoop的使用者。
[[email protected] ~]# adduser hadoop
(2)給hadoop使用者指定密碼(密碼:123456)。
[[email protected] ~]# passwd hadoop
更改使用者 hadoop 的密碼。
新的 密碼:
無效的密碼: 過於簡單化/系統化
無效的密碼: 過於簡單
重新輸入新的 密碼:
passwd: 所有的身份驗證令牌已經成功更新。
(3)驗證使用者是否建立成功,如果能成功切換表示使用者建立成功。
[[email protected] ~]# su hadoop
[[email protected] ~]#
7)安裝Xshell
XShell是系統的使用者介面,提供了使用者與核心進行互動操作的一種介面,它接收使用者輸入的命令並把它送入核心去執行。可以把XShell理解為一個客戶端,可以通過這個客戶端來遠端操作Linux系統,就像用Navicat去連線MySQL伺服器一樣,可以遠端操作MySQL資料庫。
3. 安裝XShell上傳檔案
1.安裝
(1)在安裝檔案目錄中找到Xme4.exe檔案,並雙擊安裝Xme4.exe。
(2)勾選同意,單擊“下一步”按鈕,如圖2.35所示。
 圖2.35
圖2.35
(3)輸入名字、公司和金鑰,單擊“下一步”按鈕,如圖2.36所示。
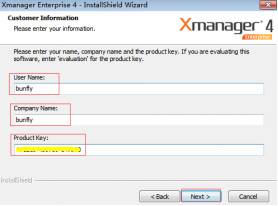
Product Key:101210-450789-147200
圖2.36
(4)修改安裝地址,單擊“下一步”按鈕,如圖2.37所示。
 圖2.37
圖2.37
(5)選擇經典安裝模式,單擊“下一步”按鈕,如圖2.38所示。
 圖2.38
圖2.38
(6)以後操作均為預設選項,當出現“安裝成功”後單擊“完成”按鈕即可。
3. 連線XSHell
(1)雙擊XShell圖示,單擊“新建連線”按鈕,開啟XShell終端,如圖2.39所示。
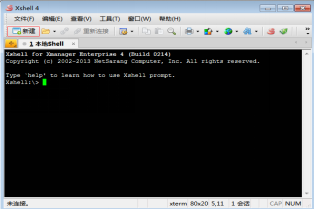 圖2.39
圖2.39
(2)配置需要連線的虛擬機器IP地址、使用者名稱和密碼。
這裡使用hadoop使用者登入,連線成功後將進入到hadoop使用者家目錄,如果是root使用者登入連線成功將進入root使用者家目錄,如圖2.40、2.41所示。
(主機號應為你所配置的虛擬機器IP(即IPADDR 後所寫網段) 可在虛擬機器中使用 ifconfig命令檢視)

 圖2.40
圖2.40
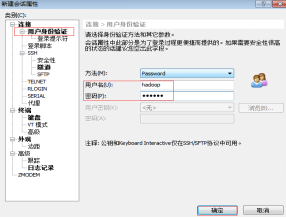 圖2.41
圖2.41
(3)選擇連線XShell,如果資訊欄出現“[[email protected] ~]$”表示連線成功。
(4)切換到家裡目錄,在家目錄下建立一個名字叫software的資料夾,用於管理安裝檔案。
[[email protected] ~]$ cd ~
[[email protected] ~]$ mkdir software
(5)進入到softeware目錄。
[[email protected] ~]$ cd software
[[email protected] software]$
4. 利用Xftp工具上傳檔案
1)XShell工具中自帶Xftp工具快捷鍵,可以利用Xftp快捷鍵進入到Xftp工具中,Xftp工具可以從XShell工作介面,單擊“Xftp快捷鍵”按鈕登入,登入的使用者與XShell登入的使用者為同一使用者。如圖2.42所示。也可以單獨通過雙擊Xftp工具輸入IP地址、使用者名稱和密碼單獨登入。
如果使用XShell快捷方式登入,使用者登入上傳的哪個檔案許可權將屬於該使用者也是經常失誤的地方。
 圖2.42
圖2.42
2)圖5.11中,左邊介面是宿主機中的介面,右邊介面是虛擬機器中的介面,下面介面是傳輸資料的進度條介面。可以在宿主機中找到要上傳的檔案,通過雙擊或者拖拽的方式將檔案上傳到虛擬機器中;也可以在虛擬機器中拖拽檔案到宿主機中下載檔案,通過XShell快捷方式登入到Xftp工具。虛擬機器介面中目錄位置是登入之前的位置,如果這個位置不是想要的位置,可在Xftp中通過選擇欄進行選擇。
將hadoop-2.6.5.tar.gz和jdk-8u131-linux-x64.tar.gz安裝包檔案上傳到虛擬機器software資料夾中,如圖2.43所示。
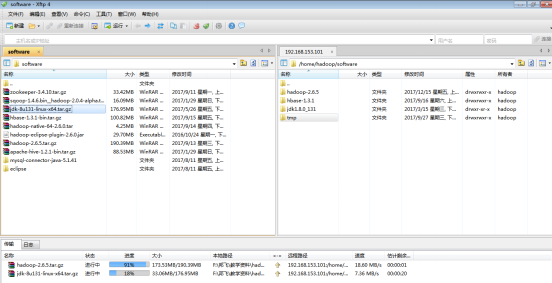 圖2.43
圖2.43
4. 安裝JDK
1)在XShell中輸入ls命令可以檢視Xftp上傳的檔案內容,通過tar命令解壓jdk-8u131-linux-x64.tar.gz壓縮檔案,操作如下:
[[email protected] software]$ ls
jdk-8u131-linux-x64.tar.gz
hadoop-2.6.5.tar.gz
[[email protected] software]$ tar -zxf jdk-8u131-linux-x64.tar.gz
[[email protected] software]$ ls
jdk-8u131-linux-x64.tar.gz
hadoop-2.6.5.tar.gz
jdk1.8.0_131
2)複製JDK安裝目錄
進入到jdk1.8.0_131目錄,使用pwd命令列印jdk安裝路徑,利用滑鼠選擇複製路徑。
[[email protected] software]$ cd jdk1.8.0_131/
[[email protected] jdk1.8.0_131]$ pwd
/home/hadoop/software/jdk1.8.0_131
3)配置環境變數
Linux系統中環境變數分為兩種:全域性變數和區域性變數。profile檔案是全域性變數配置檔案,只有管理員使用者對profile檔案才有寫入許可權,所以要編寫profile檔案需要切換到root使用者,因為在全域性變數中配置的環境變數對所有使用者都有效。.bashrc檔案是區域性變數配置檔案,在.bashrc檔案配置的環境變數只對當前使用者有效。
本文是配置的全域性環境變數。操作如下:
[[email protected] jdk1.8.0_131]$ su root
密碼:
[[email protected] ~]# vi /etc/profile
插入(在最下面):
#java
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_131
export PATH=$PATH:$JAVA_HOME/bin
4)使用環境變數生效
[[email protected] ~]# source /etc/profile
5)驗證JDK是否安裝成功
輸入java或者java -version,如果出現java命令的詳細說明或者出現JDK版本號,表示安裝成功,如果出現“-bash: dddd: command not found”表示安裝失敗。
6. 安裝hadoop
1)切換到hadoop使用者,並進入到software目錄,使用ls命令可以檢視Xftp上傳的檔案內容,通過tar命令解壓hadoop-2.6.5.tar.gz壓縮檔案。操作如下:
[[email protected] ~]# su hadoop
[[email protected] ~]$ cd software/
[[email protected] software]$ ls
jdk-8u131-linux-x64.tar.gz jdk1.8.0_131
hadoop-2.6.5.tar.gz
[[email protected] software]$ tar -zxf hadoop-2.6.5.tar.gz
[[email protected] software]$ ls
jdk-8u131-linux-x64.tar.gz jdk1.8.0_131
hadoop-2.6.5.tar.gz hadoop-2.6.5
2)進入hadoop安裝目錄
進入到hadoop-2.6.5目錄,使用pwd命令列印hadoop安裝路徑,利用滑鼠選擇複製路徑。
[[email protected] software]$ cd hadoop-2.6.5
[[email protected] hadoop-2.6.5]$ pwd
/home/hadoop/software/hadoop-2.6.5
3)配置hadoop環境變數
切換到root使用者,編輯profile檔案,並插入hadoop配置檔案。操作如下:
[[email protected] hadoop-2.6.5]$ su root
密碼:
[[email protected] ~]# vi /etc/profile
插入:
#hadoop
export HADOOP_HOME=/home/hadoop/software/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
4)使環境變數生效
[[email protected] ~]# source /etc/profile
5)驗證hadoop安裝是否成功
輸入hadoop命令,如果出現hadoop命令相關的詳細資訊,表示安裝成功;如果出現“-bash: dddd: command not found”,表示安裝失敗。
6)配置core-site.xml檔案
關於Hadoop配置檔案的講解視訊可掃描二維碼觀看。【配置Hadoop檔案】
切換到hadoop使用者,進入到hadoop-2.6.5/etc/hadoop/目錄,編輯core-site.xml檔案。
[[email protected] ~]# su hadoop
[[email protected] ~]$ cd software/hadoop-2.6.5/etc/hadoop/
[[email protected] hadoop]$ ls
core-site.xml mapred-site.xml salves
hadoop-env.cmd hdfs-site.xml yarn-site.xml
......
[[email protected] hadoop]$ vi core-site.xml
插入:
<configuration>
<!--指定HDFS儲存入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master001:9000</value>
</property>
<!--指定hadoop臨時目錄-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadoop-2.6.5/tmp</value>
</property>
</configuration>
7)配置hadoop-env.sh檔案
編輯hadoop-env.sh檔案,修改java_home地址,java_home地址是解壓的jdk地址,配置java_home是為了使用java的現實。
修改:
# The java implementation to use.
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_131
8)配置hdfs-site.xml檔案
hdfs-site.xml檔案是hadoop2.0以後版本的必備配置檔案之一,可以在hdfs-site.xml配置叢集名字空間、訪問埠、URL地址、故障轉移等配置。
[[email protected] hadoop]# vi hdfs-site.xml
插入:
<configuration>
<!--配置資料備份數-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--設定secondaryNamenode執行的節點-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Slave002:50070</value>
</property>
</configuration>
9)配置mapred-site.xml檔案
在hadoop包裡是沒有mapred-site.xml檔案,需要通過mapred-site.xml.template模版檔案複製出mapred-site.xml檔案。操作如下:
[[email protected] hadoop]# cp mapred-site.xml.template mapred-site.xml
[[email protected] hadoop]# vi mapred-site.xml
插入:
<configuration>
<!--設定jar程式啟動Runner類的main方法執行在yarn叢集中-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
10)配置slaves檔案
hadoop叢集中所有的datanode節點都需要寫入到slaves檔案中,因為它是用來指定儲存資料的節點檔案,Master會讀取salves檔案來獲取儲存資訊,根據slaves檔案來做資源平衡。
注意:
(1)slaves檔名全部是小寫,有很多初學者使用vi Slaves來編輯slaves檔案,它將會在hadoop目錄中重新建立一個首字母為大寫的slaves檔案,這樣是錯誤的;
(2)slaves檔案開啟后里面有一個“localhost”,這個localhost需要把刪除,如果沒有刪除叢集會把Master也當做DataNode節點,這樣會造成Master節點負載過重。
[[email protected] hadoop]# vi slaves
刪除:
localhost
插入:
Slave001
Slave002
Slave003
11)配置yarn-site.xml
yarn-site.xml檔案是ResourceManager程序相關配置引數。
[[email protected] hadoop]# vi yarn-site.xml
插入:
<configuration>
<!--設定對外暴露的訪問地址為Master001-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master001</value>
</property>
<!--NodeManager上執行的附屬服務。需配置成mapreduce_shuffle,才可執行MapReduce程式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6. 安裝ssh
ssh是一種遠端傳輸通訊協,用於兩臺或多臺節點之間資料傳輸。通過yum方式線上安裝ssh,yum是線上安裝工具,因此使用yum安裝時必須連線網路。yum是一個Shell前端軟體包管理器,它能夠從yum伺服器自動下載rpm包然後安裝,一次安裝完成所有需要的軟體包,不必一次次的下載,非常的簡單方便。
1)yum工具屬於root使用者工具,所以需要切換到root使用者進行線上安裝。
[[email protected] hadoop]$ su root
密碼:
[[email protected] ~]#
2)在安裝ssh之前需要先查詢yum庫有哪些ssh軟體的rpm包。
[[email protected] ~]# yum list | grep ssh
openssh.x86_64 5.3p1-84.1.el6 updates
openssh-server.x86_64 5.3p1-123.el6_9 updates
openssh-clients.x86_64 5.3p1-123.el6_9 updates
......
3)使用yum工具線上安裝server和clients軟體。
[[email protected] ~]# yum install -y openssh-clients.x86_64
[[email protected] ~]# yum install -y openssh-server.x86_64
安裝過程如圖2.44所示。
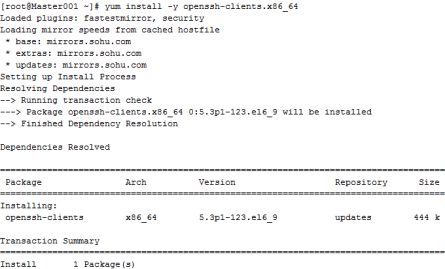 圖2.44
圖2.44
4)驗證ssh是否安裝成功
驗證方法一:輸入ssh命令,如果出現ssh命令的詳細資訊表示安裝成功,如果出現" -bash: dddd: command not found"則表示安裝失敗。
[[email protected] ~]# ssh
usage: ssh [-1246AaCfgKkMNnqsTtVvXxYy] [-b bind_address] [-c cipher_spec]
[-D [bind_address:]port] [-e escape_char] [-F configfile]
[-I pkcs11] [-i identity_file]
[-L [bind_address:]port:host:hostport]
[-l login_name] [-m mac_spec] [-O ctl_cmd] [-o option] [-p port]
[-R [bind_address:]port:host:hostport] [-S ctl_path]
[-W host:port] [-w local_tun[:remote_tun]]
[[email protected]]hostname [command]
驗證方法二:使用rpm工具驗證。輸入rpm -qa | grep ssh命令查詢已經安裝的ssh相關程式,如果出現server和clients表示安裝成功。
[[email protected] ~]# rpm -qa | grep ssh
openssh-server-5.3p1-123.el6_9.x86_64
openssh-clients-5.3p1-123.el6_9.x86_64
libssh2-1.4.2-1.el6.x86_64
openssh-5.3p1-123.el6_9.x86_64
7 複製虛擬機器
現在已經安裝好一臺節點虛擬機器的配置,其它四臺節點虛擬機器可以通過複製的方式來安裝,但在複製虛擬機器之前需要先把虛擬機器關機。
1. 關閉虛擬機器(halt命令需要root許可權)
[[email protected] ~]# halt
2. 複製虛擬機器
複製出另它四臺虛擬機器,並把複製的資料夾重新命名為Master001、Slave001、Slave002、Slave003方便管理,如圖2.45所示。
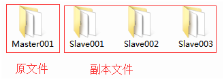 圖2.45
圖2.45
3. 開啟虛擬機器
1)通過“檔案-->開啟”選擇複製的虛擬機器來開啟虛擬機器。為了方便管理需將虛擬名字修改為資料夾名稱,如圖2.46所示。
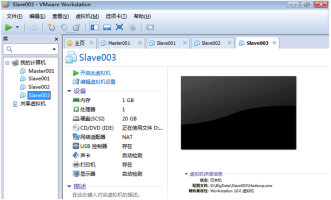 圖2.46
圖2.46
2)啟動虛擬機器
單擊左邊虛擬機器名稱,待右邊出現對應的介面後,單擊“開啟此虛擬機器”按鈕開啟虛擬機器,如圖2.47所示。
 圖2.47
圖2.47
3)選擇“我已複製該虛擬機器”
每一臺計算機都有一個唯一的MAC地址,虛擬機器也是一樣。雖然它是虛擬狀態的,但它同樣有記憶體、處理器、硬碟和MAC地址等。虛擬機器是通過複製出另一臺一模一樣的虛擬機器,包括MAC地址,所以需要在啟動副本虛擬機器時選擇“我已複製該虛擬機器”按鈕來告訴VMware平臺“我這臺虛擬機器需要重新生成一個新的MAC地址”。如果選擇“我已移動該虛擬機器”按鈕,VMware平臺將不會為新虛擬機器生成新的MAC地址,如圖2.48所示。
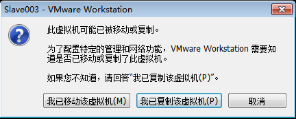 圖2.48
圖2.48
4. 修改虛擬配置
1)檢視MAC地址
修改MAC地址之前需要到70-persistent-net.reles檔案去檢視最新的MAC地址,最後的一條為最新的MAC地址,並記住ATTR和NAME的值,如圖2.49所示。
[[email protected] ~]# cat /etc/udev/rules.d/70-persistent-net.rules
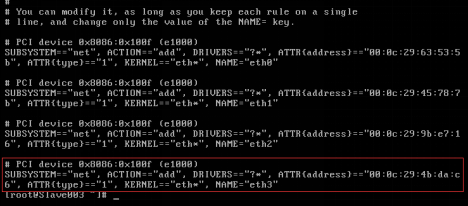 圖2.49
圖2.49
2)修改MAC地址和IP地址
需要到profile檔案中修改最新的MAC地址和網路名稱,按之前約定的配置規則來修改IP地址,如圖2.50所示。
[[email protected] ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
改寫:
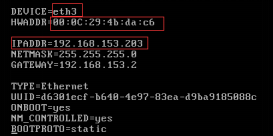 圖2.50
圖2.50
3)修改主機名
按之前約定的配置規則來修改主機名。
[[email protected] ~]# vi /etc/sysconfig/network
改寫:
HOSTNAME=Slave003
4)使修改生效
如果只是修改profile檔案,可以重啟網路服務即可使修改生效。如果修改主機名,需要重啟虛擬機器才能生效。
[[email protected] ~]# reboot
5)驗證修改是否成功
如果登入主機名變成修改的主機名錶示主機名修改成功,如圖2.51所示。
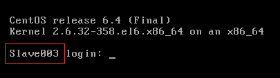 圖2.51
圖2.51
輸入使用者名稱和密碼登入後,輸入ifconfig命令,如果出現修改後的網路名稱和IP地址表示靜態IP修改成功,如圖2.52所示。
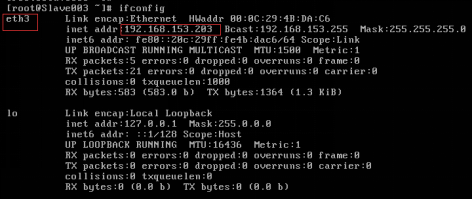 圖2.52
圖2.52
5. 修改其它虛擬機器
依次操作“5.2.3.2小節、複製虛擬機器”修改其它幾臺虛擬機器,當所有虛擬機器都修改完成後可以互相ping IP地址或主機名來驗證內網是否聯通。
[[email protected] ~]$ ping 192.168.153.101
PING 192.168.153.101 (192.168.153.101) 56(84) bytes of data.
64 bytes from 192.168.153.101: icmp_seq=1 ttl=64 time=0.797 ms
64 bytes from 192.168.153.101: icmp_seq=2 ttl=64 time=0.774 ms
^C
--- 192.168.153.101 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1876ms
rtt min/avg/max/mdev = 0.774/0.785/0.797/0.030 ms
[[email protected] ~]$ ping Master001
PING Master001 (192.168.153.101) 56(84) bytes of data.
64 bytes from Master001 (192.168.153.101): icmp_seq=1 ttl=64 time=1.69 ms
64 bytes from Master001 (192.168.153.101): icmp_seq=2 ttl=64 time=0.703 ms
^C
--- Master001 ping statistics ---
2 packets transmitted, 3 received, 0% packet loss, time 2391ms
rtt min/avg/max/mdev = 0.703/1.061/1.697/0.452 ms
2.5 設定SSH免密
安裝Hadoop之前,由於叢集中大量主機進行分散式計算需要相互進行資料通訊,伺服器之間的連線需要通過ssh來進行,所以要安裝ssh服務。預設情況下通過ssh登入伺服器需要輸入使用者名稱和密碼進行連線,如果不配置免密碼登入,每次啟動hadoop都要輸入密碼用來訪問每臺機器的DataNode,因為Hadoop叢集都有上百或者上千臺機器,靠人力輸入密碼工程耗大,所以一般都會配置ssh的免密碼登入。在hadoop叢集中Master節點需要對所有節點進行訪問,瞭解每個節點的健康狀態,所以只需要對Master做免密設定,該叢集是高可用叢集,有兩個Master。這兩個Master都需要生成自己的私密,然後對所有節點(包括自己)傳輸金鑰,以Master001為例,Master002只需要執行Master001相同操作即可。具體操作如下。
1. 生成金鑰
金鑰就像是進入一扇門的鑰匙,生成金鑰就是生成這把鑰匙。由於要對hadoop使用者進行免密設定,所以需要切換到hadoop使用者,並回到該使用者的家目錄。
執行ssh-keygen -t rsa -P '' 命令後將在/home/hadoop/.ssh/目錄下以rsa方式生成id_rsa的金鑰。
[[email protected] ~]$ cd ~
[[email protected] ~]$ ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): (出現此段後按enter繼續)
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
2c:a9:91:36:4b:18:e6:09:60:f9:1a:22:23:3b:d6:af [email protected]
The key's randomart image is:
+-------[ RSA 2048]-----+
|... |
|o. |
|. + |
|== = . o |
|+oB * o S |
|oo + = . |
|.. + |
| . |
| E. |
+-----------------------+
2. 對所有節點進行免密
將金鑰分發給叢集中所有節點(包括自己),就免去輸入密碼去訪問其它虛擬機器。執行ssh-copy-id命令後,會將id_rsa中的金鑰傳輸到目標虛擬機器的/home/hadoop/.ssh/authorized_keys檔案中。
[[email protected] ~]$ ssh-copy-id Master001
[email protected]'s password:(輸入Master001密碼)
Now try logging into the machine, with "ssh 'Master001'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[[email protected] ~]$ ssh-copy-id Slave001
[email protected]'s password: (輸入Slave001密碼)
Now try logging into the machine, with "ssh 'Slave001'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[[email protected] ~]$ ssh-copy-id Slave002
[email protected]'s password: (輸入Slave002密碼)
Now try logging into the machine, with "ssh 'Slave002'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[[email protected] ~]$ ssh-copy-id Slave003
[email protected]'s password: (輸入Slave003密碼)
Now try logging into the machine, with "ssh 'Slave003'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
3. 驗證免密設定是否成功
驗證免密是免密設定最關鍵的一步,如果不輸入密碼就能訪問到目標虛擬機器,表示免密設定成功。
[[email protected] ~]$ ssh Master001
Last login: Tue Dec 19 14:44:02 2017 from 192.168.153.1
[[email protected] ~]$ exit
logout
Connection to Master001 closed.
[[email protected] ~]$ ssh Slave001
Last login: Fri Dec 15 08:38:54 2017 from 192.168.153.1
[[email protected] ~]$ exit
logout
Connection to Slave001 closed.
[[email protected] ~]$ ssh Slave002
Last login: Fri Dec 15 08:38:56 2017 from 192.168.153.1
[[email protected] ~]$ exit
logout
Connection to Slave002 closed.
[[email protected] ~]$ ssh Slave003
Last login: Tue Dec 19 14:44:05 2017 from 192.168.153.1
[[email protected] ~]$ exit
logout
Connection to Slave003 closed.
[[email protected] ~]$
2.6 啟動Hadoop叢集
1. 在Master001中格式化namenode
在Master001中格式化namenode會生成~/software/hadoop-2.6.5/tmp目錄,該目錄中存放版本號和元資料等相關資訊。
[[email protected] ~]$ hdfs namenode -format
2. 傳送tmp檔案到其它節點
[[email protected] ~]$ cd ~/software/hadoop-2.6.5/
[[email protected] hadoop-2.6.5]$ ls
bin etc ... sbin share tmp
[[email protected] hadoop-2.6.5]$ scp -r tmp/ Slave001:~/software/hadoop-2.6.5/
[[email protected] hadoop-2.6.5]$ scp -r tmp/ Slave002:~/software/hadoop-2.6.5/
[[email protected] hadoop-2.6.5]$ scp -r tmp/ Slave003:~/software/hadoop-2.6.5/
3. 啟動hdfs
啟動hdfs只需要在Master001中執行start-dfs.sh 即可。它分別會在Master001啟動namenode程序,在Slave001、Slave002和Slave003中啟動datanode程序。
[[email protected] ~]$ start-dfs.sh
Starting namenodes on [Master001]
Master001: starting namenode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-namenode-Master001.out
Slave002: starting datanode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-datanode-Slave002.out
Slave003: starting datanode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-datanode-Slave003.out
Slave001: starting datanode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-datanode-Slave001.out
Starting journal nodes [Slave001 Slave002 Slave003]
Slave003: starting journalnode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-Slave003.out
Slave001: starting journalnode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-Slave001.out
Slave002: starting journalnode, logging to /home/hadoop/software/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-Slave002.out
4. 啟動MapReduce
啟動MapReduce只需要在Master001中執行start-yarn.sh 即可。它分別會在Master001啟動resourcemanager程序,在Slave001、Slave002和Slave003中啟動nodemanager程序。
[[email protected] ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-resourcemanager-Master001.out
Slave003: starting nodemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-Slave003.out
Slave001: starting nodemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-Slave001.out
Slave002: starting nodemanager, logging to /home/hadoop/software/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-Slave002.out
4. 驗證叢集是否成功啟動
當叢集啟動成功後每個節點中都有一些必須存在的程序。具體程序如下:
[[email protected] ~]$ jps
3766 Jps
3510 ResourceManager
3118 NameNode