
python爬蟲之xpath的基本使用 python爬蟲之xpath的基本使用
python爬蟲之xpath的基本使用
一、簡介
XPath 是一門在 XML 文件中查詢資訊的語言。XPath 可用來在 XML 文件中對元素和屬性進行遍歷。XPath 是 W3C XSLT 標準的主要元素,並且 XQuery 和 XPointer 都構建於 XPath 表達之上。
二、安裝
| 1 |
pip3 install lxml |
三、使用
1、匯入
| 1 |
from
lxml
import
etree
|
2、基本使用
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from
lxml
import
etree
wb_data
=
"""
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html
=
etree.HTML(wb_data)
print
(html)
result
=
etree.tostring(html)
print
(result.decode(
"utf-8"
))
|
從下面的結果來看,我們印表機html其實就是一個python物件,etree.tostring(html)則是不全裡html的基本寫法,補全了缺胳膊少腿的標籤。
| 1 2 3 4 5 6 7 8 9 10 11 |
<Element html at
0x39e58f0
>
<html><body><div>
<ul>
<li
class
=
"item-0"
><a href
=
"link1.html"
>first item<
/
a><
/
li>
<li
class
=
"item-1"
><a href
=
"link2.html"
>second item<
/
a><
/
li>
<li
class
=
"item-inactive"
><a href
=
"link3.html"
>third item<
/
a><
/
li>
<li
class
=
"item-1"
><a href
=
"link4.html"
>fourth item<
/
a><
/
li>
<li
class
=
"item-0"
><a href
=
"link5.html"
>fifth item<
/
a>
<
/
li><
/
ul>
<
/
div>
<
/
body><
/
html>
|
3、獲取某個標籤的內容(基本使用),注意,獲取a標籤的所有內容,a後面就不用再加正斜槓,否則報錯。
寫法一
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'/html/body/div/ul/li/a'
)
print
(html)
for
i
in
html_data:
print
(i.text)
<Element html at
0x12fe4b8
>
first item
second item
third item
fourth item
fifth item
|
寫法二(直接在需要查詢內容的標籤後面加一個/text()就行)
| 1 2 3 4 5 6 7 8 9 10 11 12 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'/html/body/div/ul/li/a/text()'
)
print
(html)
for
i
in
html_data:
print
(i)
<Element html at
0x138e4b8
>
first item
second item
third item
fourth item
fifth item
|
4、開啟讀取html檔案
| 1 2 3 4 5 6 |
#使用parse開啟html的檔案
html
=
etree.parse(
'test.html'
)
html_data
=
html.xpath(
'//*'
)<br>
#列印是一個列表,需要遍歷
print
(html_data)
for
i
in
html_data:
print
(i.text)
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
html
=
etree.parse(
'test.html'
)
html_data
=
etree.tostring(html,pretty_print
=
True
)
res
=
html_data.decode(
'utf-8'
)
print
(res)
列印:
<div>
<ul>
<li
class
=
"item-0"
><a href
=
"link1.html"
>first item<
/
a><
/
li>
<li
class
=
"item-1"
><a href
=
"link2.html"
>second item<
/
a><
/
li>
<li
class
=
"item-inactive"
><a href
=
"link3.html"
>third item<
/
a><
/
li>
<li
class
=
"item-1"
><a href
=
"link4.html"
>fourth item<
/
a><
/
li>
<li
class
=
"item-0"
><a href
=
"link5.html"
>fifth item<
/
a><
/
li>
<
/
ul>
<
/
div>
|
5、列印指定路徑下a標籤的屬性(可以通過遍歷拿到某個屬性的值,查詢標籤的內容)
| 1 2 3 4 5 6 7 8 9 10 11 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'/html/body/div/ul/li/a/@href'
)
for
i
in
html_data:
print
(i)
列印:
link1.html
link2.html
link3.html
link4.html
link5.html
|
6、我們知道我們使用xpath拿到得都是一個個的ElementTree物件,所以如果需要查詢內容的話,還需要遍歷拿到資料的列表。
查到絕對路徑下a標籤屬性等於link2.html的內容。
| 1 2 3 4 5 6 7 8 9 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'/html/body/div/ul/li/a[@href="link2.html"]/text()'
)
print
(html_data)
for
i
in
html_data:
print
(i)
列印:
[
'second item'
]
second item
|
7、上面我們找到全部都是絕對路徑(每一個都是從根開始查詢),下面我們查詢相對路徑,例如,查詢所有li標籤下的a標籤內容。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'//li/a/text()'
)
print
(html_data)
for
i
in
html_data:
print
(i)
列印:
[
'first item'
,
'second item'
,
'third item'
,
'fourth item'
,
'fifth item'
]
first item
second item
third item
fourth item
fifth item
|
8、上面我們使用絕對路徑,查找了所有a標籤的屬性等於href屬性值,利用的是/---絕對路徑,下面我們使用相對路徑,查詢一下l相對路徑下li標籤下的a標籤下的href屬性的值,注意,a標籤後面需要雙//。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'//li/a//@href'
)
print
(html_data)
for
i
in
html_data:
print
(i)
列印:
[
'link1.html'
,
'link2.html'
,
'link3.html'
,
'link4.html'
,
'link5.html'
]
link1.html
link2.html
link3.html
link4.html
link5.html
|
9、相對路徑下跟絕對路徑下查特定屬性的方法類似,也可以說相同。
| 1 2 3 4 5 6 7 8 9 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'//li/a[@href="link2.html"]'
)
print
(html_data)
for
i
in
html_data:
print
(i.text)
列印:
[<Element a at
0x216e468
>]
second item
|
10、查詢最後一個li標籤裡的a標籤的href屬性
| 1 2 3 4 5 6 7 8 9 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'//li[last()]/a/text()'
)
print
(html_data)
for
i
in
html_data:
print
(i)
列印:
[
'fifth item'
]
fifth item
|
11、查詢倒數第二個li標籤裡的a標籤的href屬性
| 1 2 3 4 5 6 7 8 9 |
html
=
etree.HTML(wb_data)
html_data
=
html.xpath(
'//li[last()-1]/a/text()'
)
print
(html_data)
for
i
in
html_data:
print
(i)
列印:
[
'fourth item'
]
fourth item
|
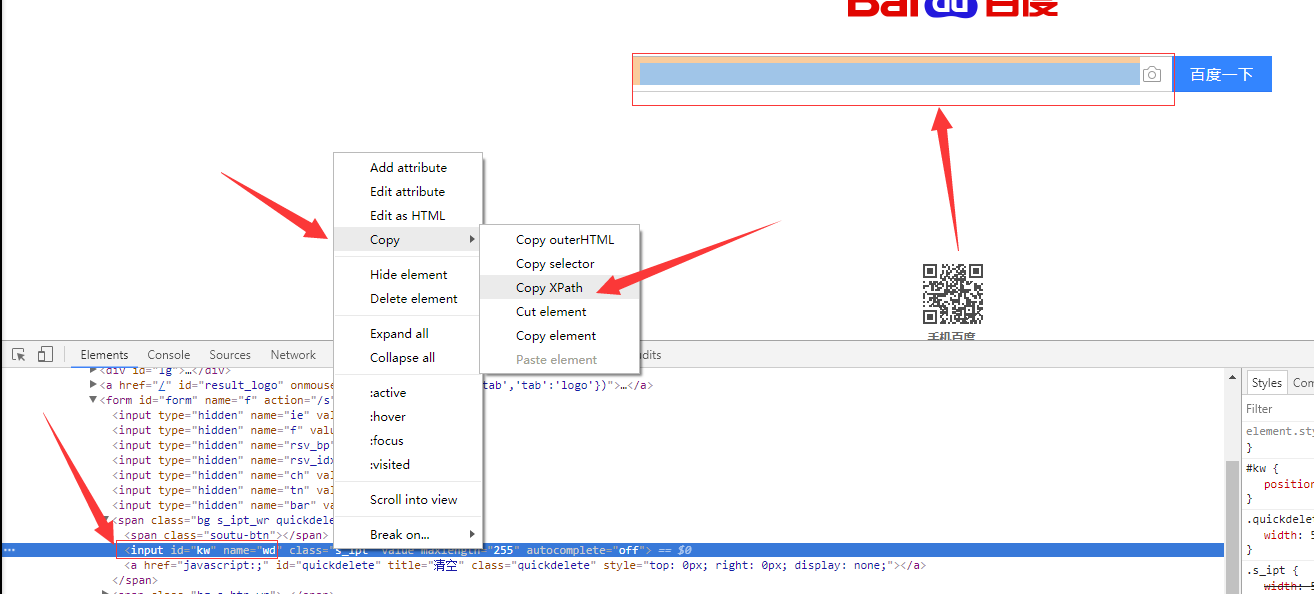
12、如果在提取某個頁面的某個標籤的xpath路徑的話,可以如下圖:
//*[@id="kw"]
解釋:使用相對路徑查詢所有的標籤,屬性id等於kw的標籤。
 常用
常用
一、簡介
XPath 是一門在 XML 文件中查詢資訊的語言。XPath 可用來在 XML 文件中對元素和屬性進行遍歷。XPath 是 W3C XSLT 標準的主要元素,並且 XQuery 和 XPointer 都構建於 XPath 表達之上。
二、安裝
| 1 |
pip3 install lxml
|
三、使用
1、匯入
| 1 |
from
lxml
import
etree
|
2、基本使用
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from
lxml
import
etree
wb_data
=
"""
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
&n
|