
python爬蟲(四)---scrapy框架之騰訊招聘專案實戰
目的:功能就是翻頁請求
步驟:如下

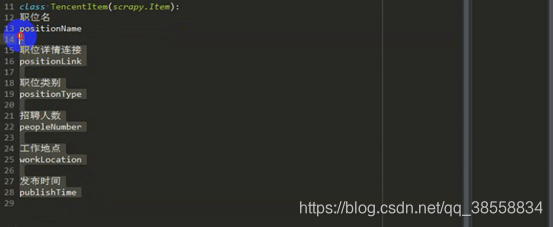
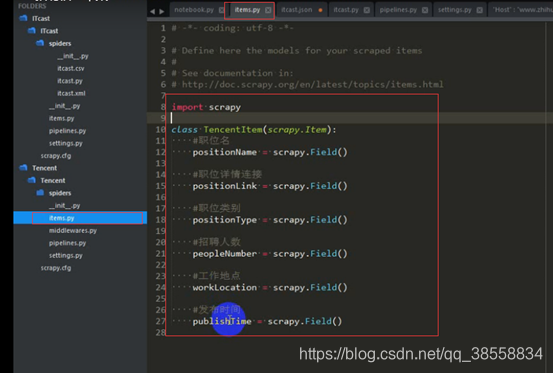
爬取職位名,職位連結等

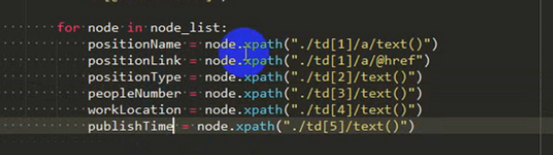
職位名:
職位詳情連結:
職位類別:
人數:
地點:
釋出時間:
下一步驟:寫爬蟲 :tencent.py檔案寫

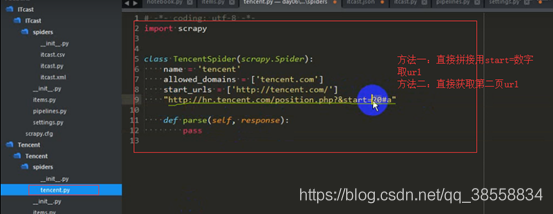
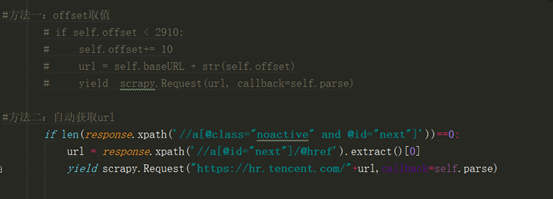
方法一:
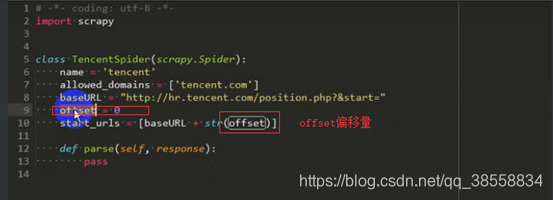

或者這樣寫
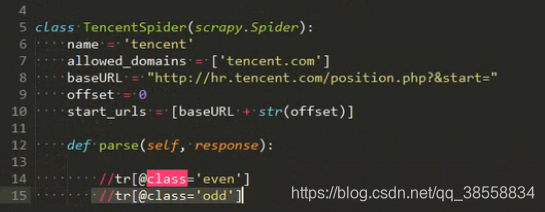

獲取職位名
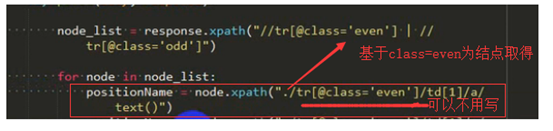
獲取連結
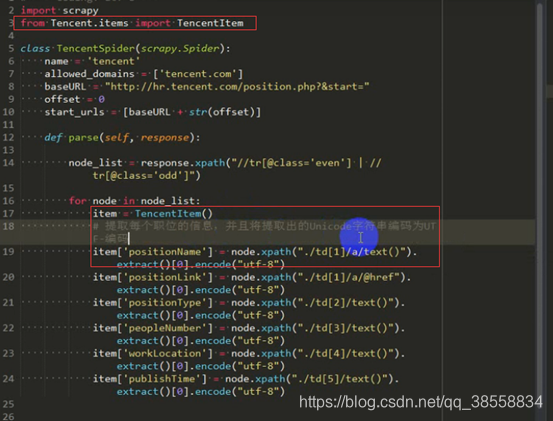

再傳給管道:
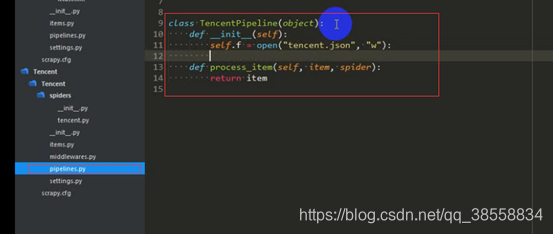
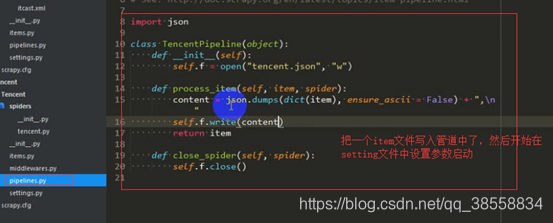
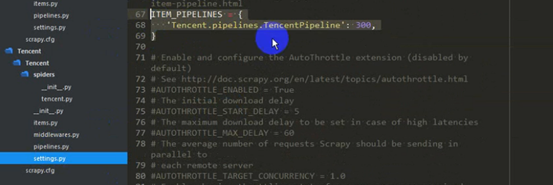
設定settings函式
開始翻頁(提取第二頁的連結)
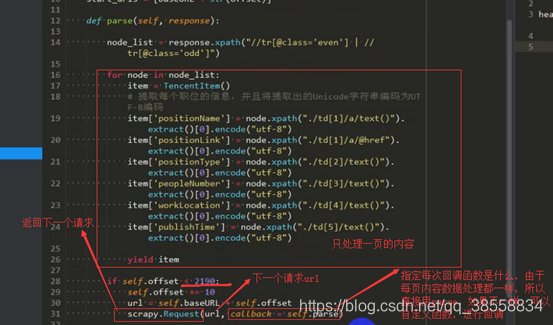
以上只是構建了請求但是沒有發出去請求,因此需要用yield

排錯一:
因為有的沒有類別,所以要判斷:
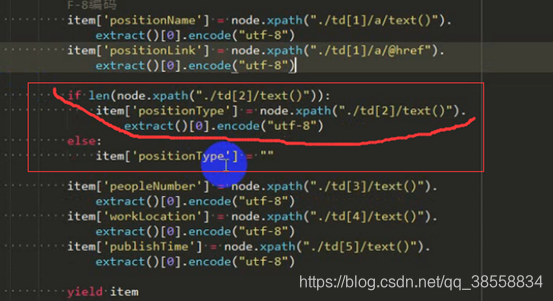
排錯二:

方法二:用scrapy提取連結
總結:一個專案的大致流程

相關推薦
python爬蟲(四)---scrapy框架之騰訊招聘專案實戰
目的:功能就是翻頁請求 步驟:如下 爬取職位名,職位連結等 職位名: 職位詳情連結: 職位類別: 人數: 地點: 釋出時間: 下一步驟:寫爬蟲 :tencent.py檔案寫 方法一: 或者這樣寫
python爬蟲(四):scrapy 【1. 快速上手】
中文文件:http://www.scrapyd.cn/doc/ Scrapy是採用Python開發的一個快速、高層次的螢幕抓取和web抓取框架。 什麼是爬蟲框架? 爬蟲框架是實現爬蟲功能的一個軟體結構和功能元件集合。 爬蟲框架是一個半成品,能夠幫助使用者實現專業網路
python爬蟲(四):scrapy 【2. 其他重要部分】
中文文件:http://www.scrapyd.cn/doc/ 本節包括: 1. resquest 和 response 的屬性方法 2. scrapy提取資訊的強大方法 request 和 response request:
自學python爬蟲(四)Requests+正則表示式爬取貓眼電影
前言 學了requests庫和正則表示式之後我們可以做個簡單的專案來練練手咯!先附上專案GitHub地址,歡迎star和fork,也可以pull request哦~ 地址:https://github.com/zhangyanwei233/Maoyan100.git 正文開始哈哈哈
python 爬蟲(四)抓取Ajax資料
import urllib.request import ssl import json def ajaxCrawler(url): headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKi
Python爬蟲(四) URLError、HTTPError異常處理
1.URLError 首先解釋下URLError可能產生的原因: 網路無連線,即本機無法上網 連線不到特定的伺服器 伺服器不存在 在程式碼中,我們需要用try-except語句來包圍並捕獲相應的異常。下面是一個例子: import urllib.req
python爬蟲基礎(13:Scrapy框架之架構流程與目錄)
框架 對於特別小的爬蟲,一般直接編寫就可以了,但一般面對一個專案級別的爬蟲,都選擇用框架 框架可以理解為一個 等你填坑的程式碼: 1. 為你編寫好那些必須的、重複的程式碼 2. 為你模組化好每一個元件,自動建立元件之間的聯絡,這樣就方便使用者清晰瞭解它的
小白學 Python 爬蟲(36):爬蟲框架 Scrapy 入門基礎(四) Downloader Middleware
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
Python學習之路 (五)爬蟲(四)正則表示式爬去名言網
auth Python標準庫 我們 color 匯總 eight code 比較 school 爬蟲的四個主要步驟 明確目標 (要知道你準備在哪個範圍或者網站去搜索) 爬 (將所有的網站的內容全部爬下來) 取 (去掉對我們沒用處的數據) 處理數據(按照我們想要的
Python爬蟲(二):Scrapy框架的配置安裝
Windows安裝方式 預設支援Python2、Python3,通過pip安裝Csrapy框架: pip install Scrapy Ubuntu(9.10以上版本)安裝方式 預設支援Python2、Python3,通過pip安裝Csrapy框架: sud
python學習(三)scrapy爬蟲框架(三)——爬取桌布儲存並命名
寫在開始之前 按照上一篇介紹過的scrapy爬蟲的建立順序,我們開始爬取桌布的爬蟲的建立。 首先,再過一遍scrapy爬蟲的建立順序: 第一步:確定要在pipelines裡進行處理的資料,寫好items檔案 第二步:建立爬蟲檔案,將所需要的資訊從網站上爬
小白學 Python 爬蟲(33):爬蟲框架 Scrapy 入門基礎(一)
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
小白學 Python 爬蟲(34):爬蟲框架 Scrapy 入門基礎(二)
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
小白學 Python 爬蟲(35):爬蟲框架 Scrapy 入門基礎(三) Selector 選擇器
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
小白學 Python 爬蟲(37):爬蟲框架 Scrapy 入門基礎(五) Spider Middleware
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
小白學 Python 爬蟲(40):爬蟲框架 Scrapy 入門基礎(七)對接 Selenium 實戰
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
小白學 Python 爬蟲(41):爬蟲框架 Scrapy 入門基礎(八)對接 Splash 實戰
人生苦短,我用 Python 前文傳送門: 小白學 Python 爬蟲(1):開篇 小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝 小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門 小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門 小白學 Pyth
Python基礎(四)之tuple
全部測試程式碼 #!usr/bin/env python3 # _*_ codeing: utf-8 -*_ ######################tuple########################## ##tuple元祖與list集合很相似,區別就是list是
Python爬蟲(一):編寫簡單爬蟲之新手入門
最近學習了一下python的基礎知識,大家一般對“爬蟲”這個詞,一聽就比較熟悉,都知道是爬一些網站上的資料,然後做一些操作整理,得到人們想要的資料,但是怎麼寫一個爬蟲程式程式碼呢?相信很多人是不會的,今天寫一個針對新手入門想要學習爬蟲的文章,希望對想要學習的你能有所幫助~~廢話不多說,進入正文!
邊學邊敲邊記之爬蟲系列(四):Scrapy框架搭建
一、前言 今天給大家分享的是,Python裡的爬蟲框架Scrapy學習,包含python虛擬環境的搭建、虛擬環境的使用、Scrapy安裝方法詳解、Scrapy基本使用、Scrapy專案目錄及內容基本介紹,let’s go! 二、Python爬蟲框架Scrapy簡介 推薦