
Rethinking ImageNet Pre-training 重新審視Imagenet預訓練
Rethinking ImageNet Pre-training 2018年ECCV
論文地址:https://arxiv.org/pdf/1811.08883.pdf
本論文是何凱明大神的一篇論文,主要是討論了Imagenet預訓練和隨機初始化引數之間的區別。
論文摘要:
作者在COCO資料集上進行例項分割和檢測測試,發現預訓練+微調的效果和隨機初始化的效果接近。並且隨機初始化的網路訓練有很強的的魯邦性特別是在:1.使用10%的訓練集 2.更深更復雜的網路結構中 3.使用多個任務和指標 這三種情況下。只是隨機初始化需要更多的迭代次數。
論文引言:
深度卷積神經網路方法為計算機視覺領域帶來了新的活力,換言之,是因為發現使用預訓練任務中學到的特徵表示,能夠將其中有用的資訊傳遞給另一目標任務。近年來,一個通用的方法(模式)是使用大規模資料(例如 ImageNet )對模型進行預訓練,然後在具有較少訓練資料的目標任務上對模型進行微調。預訓練模型已經在許多工上實現了最先進(state of the art)的結果,包括物體檢測,影象分割和動作識別等任務。但這種方法(預訓練加微調)真的能解決計算機視覺領域的問題嗎?我們提出了質疑。因此,通過實驗展示了在 COCO 資料集上,我們使用隨機初始化方法訓練取得了和使用 ImageNet 預訓練方法相媲美的結果,而且我們還發現僅使用 10% 的COCO 資料也能訓練到差不多的結果。
作者通過實驗得到下面的三條結論:
1. Imagenet預訓練在訓練初期可以加速訓練。但是預訓練+微調的訓練時間等同於隨機初始化訓練時間。
2. 預訓練並不會提供更好的正則化效果。但訓練資料集較小時,必須選擇新的超引數來避免過擬合。
3. 基於分類的,類似 ImageNet 圖片集的預訓練任務和對區域性敏感的目標任務,三者之間的差異可能會限制預訓練方法發揮其功能。
論文實驗設定:
正則化:
Batch Normalization(BN):在隨機初始化的網路中的作用不大。BN 策略的引入雖然可以減少批量大小記憶體,但是小批量的輸入會嚴重降低模型的準確性。 論文中引入的兩種正則化方法,緩解小批量輸入問題:
1. Group Normalization (GN):GN 方法的計算與輸入的批量維度無關,因此引用該正則化方法時,模型準確性對輸入的批量大小並不敏感。
2.Synchronized Batch Normalization (SyncBN): 可以統計多個裝置的批量大小。當使用多個GPU 時,該正則化方法能夠增加BN 的有效批量大小,從而避免小批量輸入的問題。
實驗表明 GN和SyncBN正則化策略是有效的。VGG再不需要GN和SycnBN的情況下效果也很好。
收斂性:

圖中分別是圖片,例項和畫素三種情況下的對比。紫色的是隨機初始化。淺綠色和綠色表示的是預訓練+微調。圖中可以看出來紫色的是綠色的三倍左右。但是預訓練+微調都大於隨機初始化。
實驗結果:
實驗設定:採用 Mask R-CNN,ResNet 或 ResNeXt,並採用特徵金字塔網路(FPN)作為我們模型的主體結構,並採用端到端的方式(end-to-end)來訓練 RPN 和 Mask R-CNN。此外,GN/SyncBN 代替所有 frozen BN 層(逐通道的仿射變換)。為了公平比較,在研究過程中我們對預訓練模型同樣採用 GN 或 SyncBN 正則化策略進行微調。
在 8 個 GPU 上,採用 synchronized SGD,每個 GPU 上 mini-batch 大小為 2,來訓練所有模型。


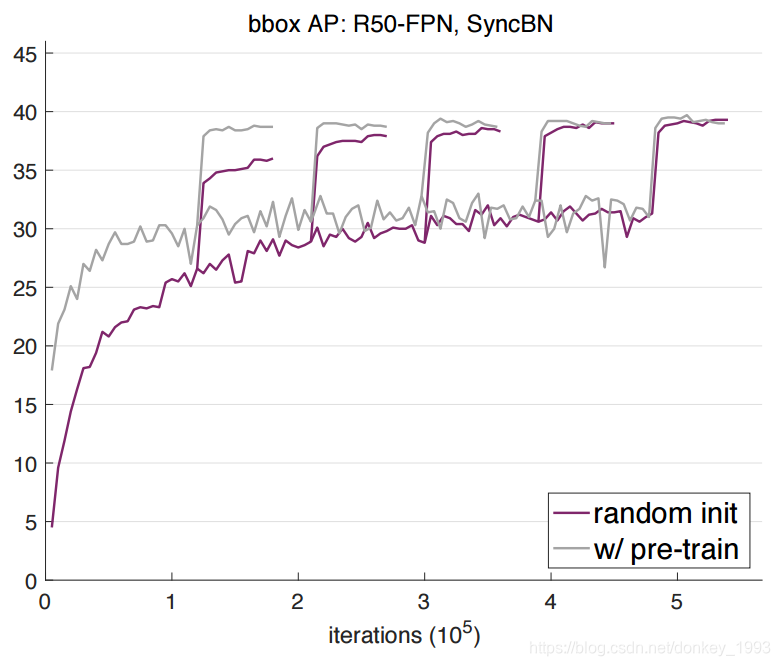
從結果可以看出來隨著訓練次數的迭代,預訓練+微調的最終效果和隨機初始化引數的效果基本接近。
作者還在文章的最後給大家做了一個總結:
ImageNet 預訓練是否有必要?事實並非如此,如果我們有足夠的目標資料和計算資源的話,也許我們可以不依賴 ImageNet 的預訓練。我們的實驗結果表明,ImageNet 預訓練可以幫助模型加速收斂過程,但是並不一定能提高最終的準確性,除非資料集特別小(例如,<10k COCO images)。這表明,在未來的研究中,收集目標資料的標註資訊(而不是預訓練資料)對於改善目標任務的表現是更有幫助的。
ImageNet有用嗎?確實是有用的。ImageNet 預訓練一直以來是計算機視覺領域許多工效能輔助工具。它能夠減少了訓練的週期,更容易獲得有前途的結果,經預訓練的模型能夠多次使用,訓練成本很低。此外,經預訓練的模型能夠有更快的收斂速度。我們相信 ImageNet 預訓練仍然有助於計算機視覺研究。
我們需要大資料嗎?的確需要。但如果我們考慮資料收集和清理的成本的話,一個通用的大規模分類的資料集並不是理想的選擇。因為收集諸如 ImageNet 這樣大資料集的成本被忽略掉了,而在資料集上進行預訓練步驟的成本也是龐大的。如果在大規模的分類資料集上預訓練的收益呈指數型下降減少,那麼在目標域上收集資料將會是更有效的做法。
我們應該追求通用的模型效能嗎?毫無疑問,我們的目標是模型能夠學習到通用的特徵表徵。我們所取得的結果也沒有偏離這一目標。其實,我們的研究表明在計算機視覺領域,我們應該更加註意評估預訓練的特徵(例如對於自監督過程的特徵學習),就像現在我們學到的那樣,即使是隨機初始化過程也能得到出色的結果表現。