
入門知識——Linux入門
1.Linux系統簡介:
作業系統linux=系統呼叫和核心
linux本身只是作業系統的核心,核心是使其他程式執行的基礎,它實現了多工和硬體管理,使用者和系統管理員互動執行的所有程式都執行在核心之上;
shell(命令列直譯器),用於使用者互動和編寫shell指令碼
linux作業系統發行版,Ubuntu,CentOS,Fedora,OpenSUSE,Debian,Mint
2.基本概念和操作
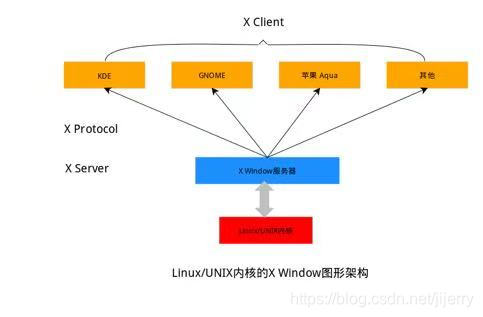
linux上圖形介面,是執行在linux上的一套軟體,xorg:是通過x視窗系統實現的,x本身是工具包和協議架構,xorg是x架構的實現體,也就是說它是實現了x協議規範的一個提供圖形介面服務的伺服器,當然還需要一個客戶端,稱為x client,比較熟知的桌面環境就是:KDE,GNOME,XFCE,LXDE
終端模擬器:Terminal,xterm
終端本質是對應linux上的/dev/tty裝置,多使用者登入是通過不同的/tty裝置完成的,linux預設提供6個純命令介面terminal讓使用者登入,物理機上通過ctrl+alt+F1-F6切換
shell,提供給使用者的軟體,它是互動介面,也是控制系統的指令碼語言
linux上比較流行的shell是bash,zsh,ksh,csh
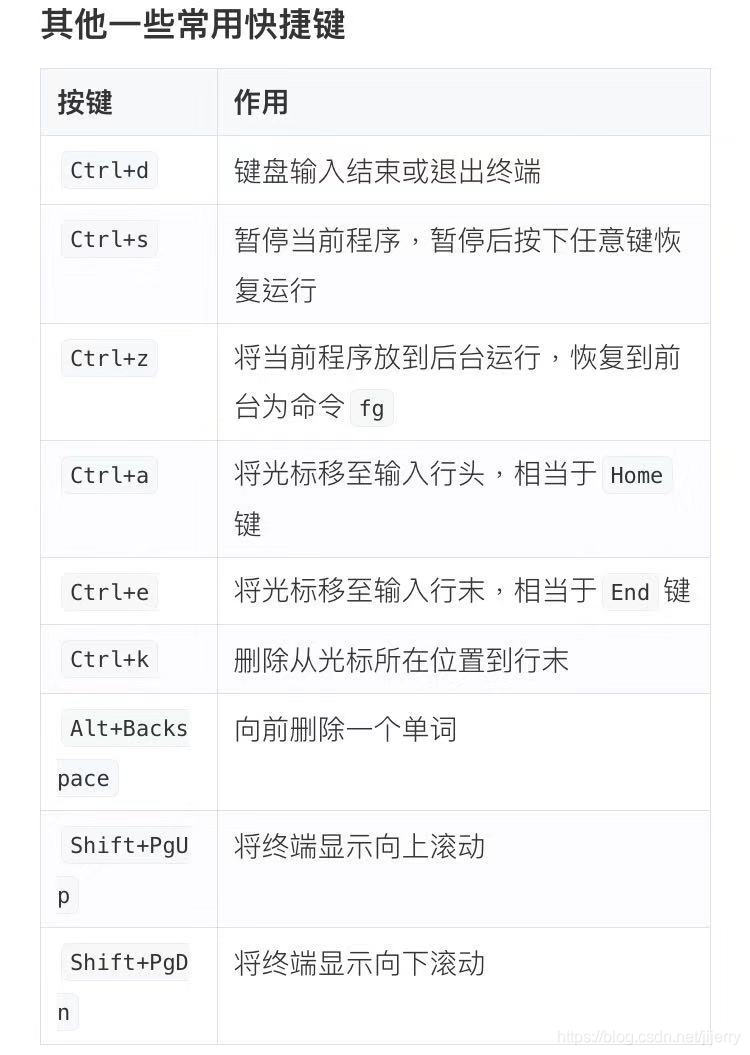
Tab:補全命令,目錄,命令引數
Ctrl+c;強行終止當前程式
*、?:對字串迷糊匹配(檔名,引數名),輸入的萬用字元是由shell處理的,它只會出現在命令的引數裡,命令可以用tab補全,shell在引數值中找到萬用字元時候,將其當做路徑或者檔名磁碟中查詢匹配,找到了進行替換,否則將其作為一個普通字元傳給命令,再由命令進行處理,總之:
萬用字元只是一種shell實現路徑擴充套件功能,萬用字元被處理以後,shell先完成命令的重組,然後繼續處理重組後的命令,直到執行命令(ls *.txt)

建立多個檔案:touch {1..10}_jerry.txt
$man(manual pages):man <command_name>(ls --help)


3.使用者和檔案許可權操作
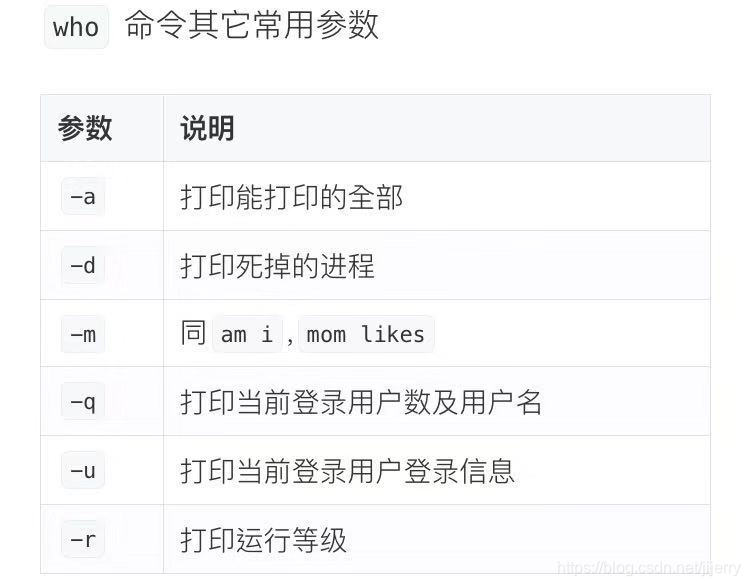
$who am i:使用者名稱 偽終端,開啟時間
root許可權,系統許可權的一種,與system許可權可以理解成一個,是超級管理員使用者賬戶,擁有系統至高無上的權利,要建立使用者需要root許可權;sudo:需要知道當前使用者的密碼,同時當前使用者屬於sudo使用者組
su,su-,sudo:
su <user>切換使用者,執行需要輸入使用者密碼,sudo <cmd>可以特權命令執行cmd命令,需要當前使用者屬於sudo使用者組,且需要輸入當前使用者密碼,su - <user>,命令切換使用者,同時環境變數改成目標使用者的環境變數;
$sudo adduser jerry:新建使用者jerry,新增使用者到系統,同時預設為使用者建立了home目錄(ls /home)
$su -l jerry:切換登陸
$exit+d/exit:退出當前使用者,退出終端;
linux中每個使用者都屬於使用者組,使用者組簡單理解就是一組使用者的集合,共享一些資源和許可權,同時擁有私有資源,一個使用者可以屬於多個使用者組
$groups jerry&cat /etc/group:檢視使用者屬於哪些使用者組,冒號之前表示使用者,後面表示使用者屬於的使用者組,每次建立使用者不指定使用者組,預設會建立一個和使用者名稱相同的使用者組,預設情況下,sudo使用者組裡可以使用sudo命令獲得root許可權
$cat /etc/group |sort:cat 命令使用者讀取指定檔案內容然後列印到終端輸出,sort將讀取的文字進行字典排序在輸出
etc/group 檔案格式說明
/etc/group 的內容包括使用者組(Group)、使用者組口令、GID 及該使用者組所包含的使用者(User),每個使用者組一條記錄。格式如下:
group_name:password:GID:user_list
你看到上面的 password 欄位為一個 x 並不是說密碼就是它,只是表示密碼不可見而已
將其它使用者加入 sudo 使用者組
預設情況下新建立的使用者是不具有 root 許可權的,也不在 sudo 使用者組,可以讓其加入 sudo 使用者組從而獲取 root 許可權:
$ su -l lilei
$ sudo ls
會提示 lilei 不在 sudoers 檔案中,意思就是 lilei 不在 sudo 使用者組中,至於 sudoers 檔案(/etc/sudoers)你現在最好不要動它,操作不慎會導致比較麻煩的後果。
usemod:使用 usermod 命令可以為使用者新增使用者組,同樣使用該命令你必需有 root 許可權,你可以直接使用 root 使用者為其它使用者新增使用者組,或者用其它已經在 sudo 使用者組的使用者使用 sudo 命令獲取許可權來執行該命令
這裡我用 shiyanlou 使用者執行 sudo 命令將 lilei 新增到 sudo 使用者組,讓它也可以使用 sudo 命令獲得 root 許可權:
$ su jerry # 此處需要輸入jerry使用者密碼
$ groups lilei
$ sudo usermod -G sudo lilei
$ groups lilei 然後你再切換回 lilei 使用者,現在就可以使用 sudo 獲取 root 許可權
ls -l:

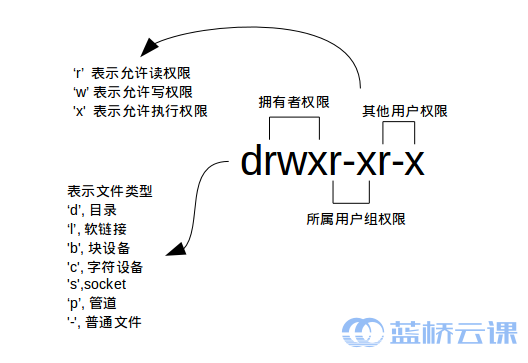
檔案型別
Linux 裡面一切皆檔案,正因為這一點才有了裝置檔案( /dev 目錄下有各種裝置檔案,大都跟具體的硬體裝置相關)
socket:網路套接字。pipe 管道,軟連結檔案:連結檔案是分為兩種的,另一種當然是“硬連結”(硬連結不常用,而軟連結等同於 Windows 上的快捷方式,你記住這一點就夠了)。
檔案許可權
讀許可權,表示你可以使用 $cat <file name> 之類的命令來讀取某個檔案的內容;
寫許可權,表示你可以編輯和修改某個檔案;
執行許可權,通常指可以執行的二進位制程式檔案或者指令碼檔案,如同 Windows 上的 exe 字尾的檔案,不過 Linux 上不是通過檔案字尾名來區分檔案的型別。需要注意的一點是,一個目錄同時具有讀許可權和執行許可權才可以開啟並檢視內部檔案,而一個目錄要有寫許可權才允許在其中建立其它檔案,這是因為目錄檔案實際儲存著該目錄裡面的檔案的列表等資訊。
所有者許可權,這一點相信你應該明白了,至於所屬使用者組許可權,是指你所在的使用者組中的所有其它使用者對於該檔案的許可權
連結數
連結到該檔案所在的 inode 結點的檔名數目
檔案大小
以 inode 結點大小為單位來表示的檔案大小,你可以給 ls 加上 -lh 引數來更直觀的檢視檔案的大小。
$ls -A/-Al:顯示除了 .(當前目錄)和 ..(上一級目錄)之外的所有檔案,包括隱藏檔案(Linux 下以 . 開頭的檔案為隱藏檔案)
$ls -dl <目錄名>:檢視某一個目錄的完整屬性,而不是顯示目錄裡面的檔案屬性
$ ls -AsSh:顯示所有檔案大小,並以普通人類能看懂的方式呈現,其中小 s 為顯示檔案大小,大 S 為按檔案大小排序,若需要知道如何按其它方式排序,請使用“man”命令查詢。
sudo chown shiyanlou iphone6:變更檔案所有者
修改檔案許可權:
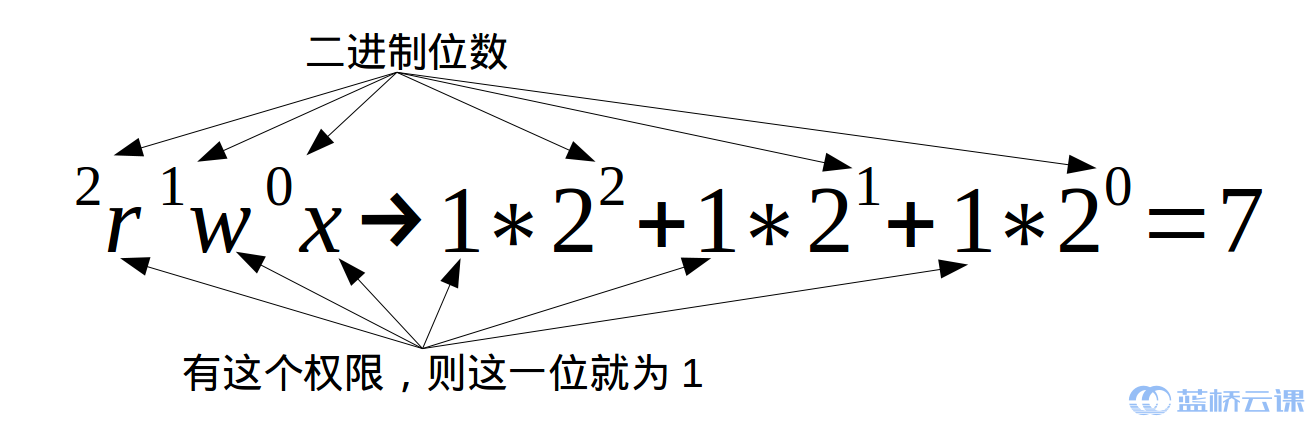
每個檔案的三組許可權(擁有者,所屬使用者組,其他使用者,記住這個順序是一定的)對應一個 " rwx ",也就是一個 “ 7 ” ,所以如果我要將檔案“ iphone6 ”的許可權改為只有我自己可以用那麼就這樣:
$chmod 600 iphone6
加減賦值許可權:
$ chmod go-rw iphone6,g、o 還有 u 分別表示 group、others 和 user,+ 和 - 分別表示增加和去掉相應的許可權
useradd 只建立使用者,建立完了用 passwd lilei 去設定新使用者的密碼。adduser 會建立使用者,建立目錄,建立密碼(提示你設定),做這一系列的操作。其實 useradd、userdel 這類操作更像是一種命令,執行完了就返回。而 adduser 更像是一種程式,需要你輸入、確定等一系列操作
4.Linux目錄和檔案基本操作:
Linux 是以樹形目錄結構的形式來構建整個系統的,可以理解為樹形目錄是一個使用者可作業系統的骨架,
雖然本質上無論是目錄結構還是作業系統核心都是儲存在磁碟上的,但從邏輯上來說 Linux 的磁碟是“掛在”(掛載在)目錄上的,每一個目錄不僅能使用本地磁碟分割槽的檔案系統,也可以使用網路上的檔案系統
FHS 定義了兩層規範,第一層是, / 下面的各個目錄應該要放什麼檔案資料,例如 /etc 應該放置設定檔案,/bin 與 /sbin 則應該放置可執行檔案等等
第二層則是針對 /usr 及 /var 這兩個目錄的子目錄來定義。例如 /var/log 放置系統日誌檔案,/usr/share 放置共享資料等等
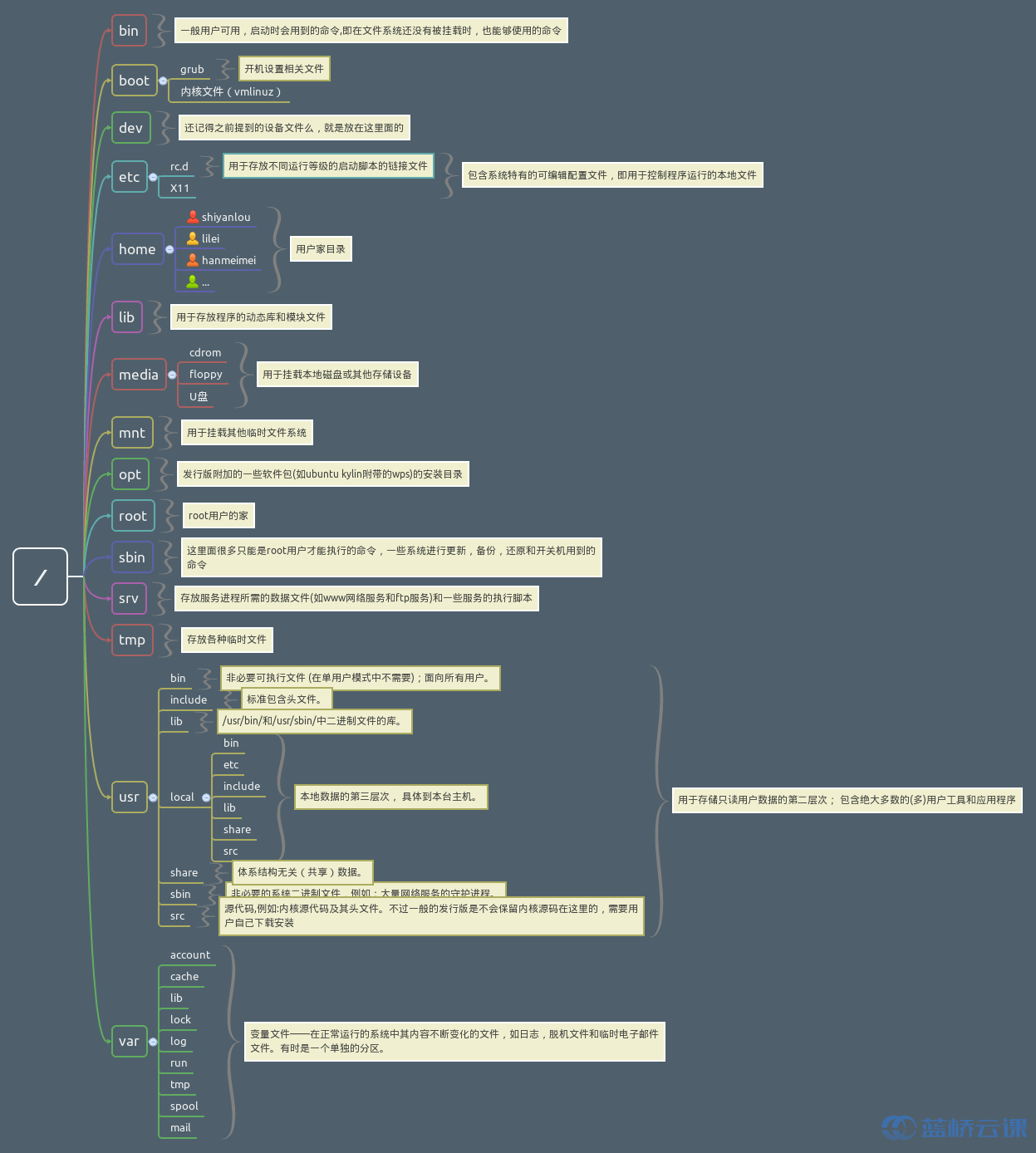
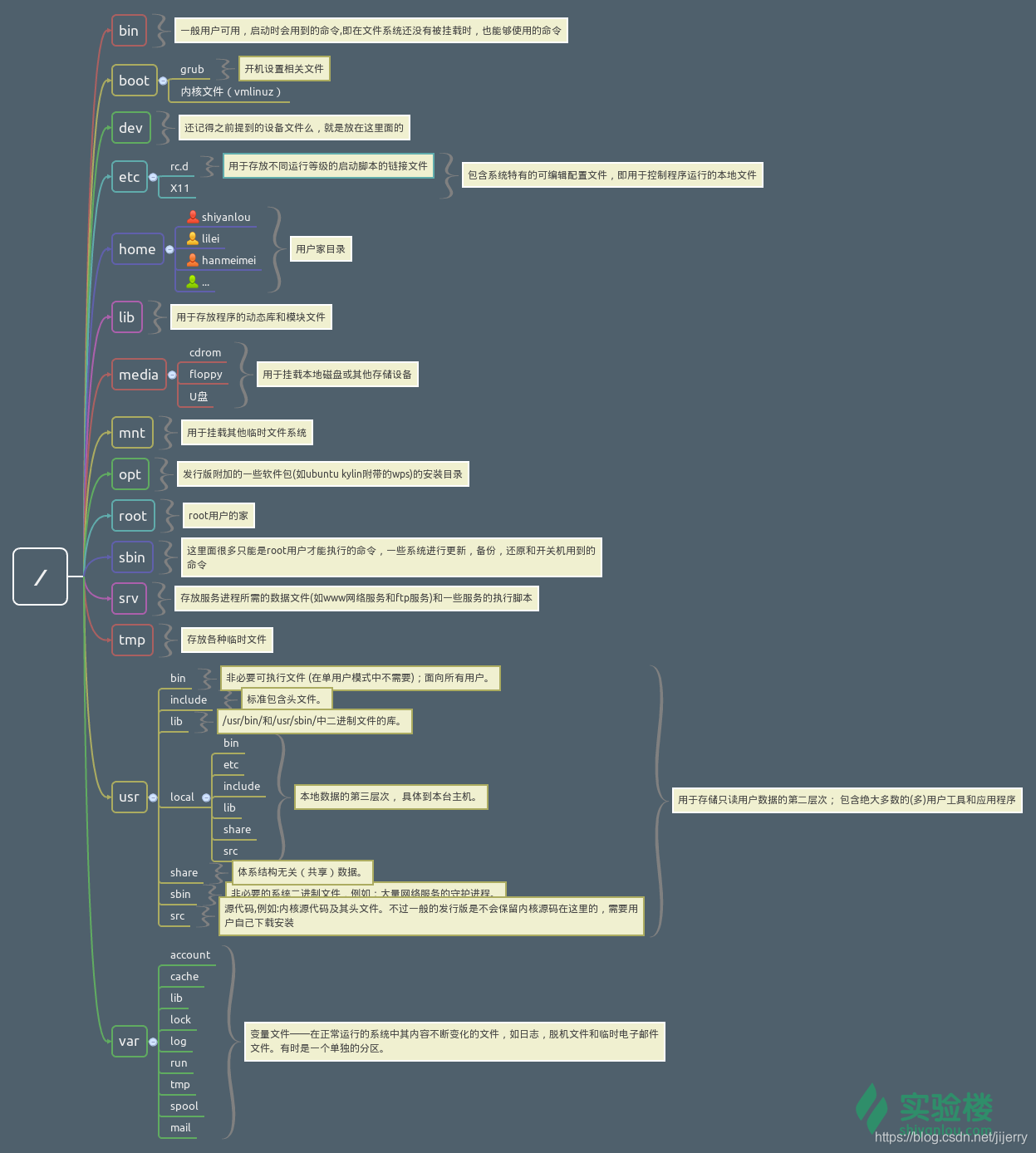
$ tree /
使用 cd 命令可以切換目錄,在 Linux 裡面使用 . 表示當前目錄,.. 表示上一級目錄(注意,我們上一節介紹過的,以 . 開頭的檔案都是隱藏檔案,所以這兩個目錄必然也是隱藏的,你可以使用 ls -a 命令檢視隱藏檔案), - 表示上一次所在目錄,~ 通常表示當前使用者的 home 目錄。使用 pwd 命令可以獲取當前所在路徑(絕對路徑)
進入上一級目錄:
$ cd ..
進入你的 home 目錄:
$ cd ~
# 或者 cd /home/<你的使用者名稱>
使用 pwd 獲取當前路徑:
$ pwd
提示:在進行目錄切換的過程中請多使用 Tab 鍵自動補全,可避免輸入錯誤,連續按兩次 Tab 可以顯示全部候選結果
$touch:新建空白檔案,只指定一個檔名,則可以建立一個指定檔名的空白檔案(不會覆蓋已有同名檔案)
$mkdir:mkdir(make directories)命令可以建立一個空目錄,也可同時指定建立目錄的許可權屬性
$ mkdir -p father/son/grandson:使用 -p 引數,同時建立父目錄(如果不存在該父目錄),如下我們同時建立一個多級目錄(這在安裝軟體、配置安裝路徑時非常有用)
$cp:使用 cp(copy)命令複製一個檔案到指定目錄,要成功複製目錄需要加上 -r 或者 -R 引數,表示遞迴複製,就是說有點“株連九族”的意思($ cp test father/son/grandson)
$rm:使用 rm(remove files or directories)命令刪除一個檔案,許可權不足,你如果想忽略這提示,直接刪除檔案,可以使用 -f 引數強制刪除,跟複製目錄一樣,要刪除一個目錄,也需要加上 -r 或 -R 引數
$mv(mv 源目錄檔案 目的目錄):使用 mv(move or rename files)命令移動檔案(剪下)。將檔案“ file1 ”移動到 Documents 目錄($ mv file1 Documents)
$mv(mv 舊的檔名 新的檔名)
rename 命令可以批量重新命名
$ cd /home/shiyanlou/
# 使用萬用字元批量建立 5 個檔案:
$ touch file{1..5}.txt
# 批量將這 5 個字尾為 .txt 的文字檔案重新命名為以 .c 為字尾的檔案:
$ rename 's/\.txt/\.c/' *.txt
# 批量將這 5 個檔案,檔名和字尾改為大寫:
$ rename 'y/a-z/A-Z/' *.c
簡單解釋一下上面的命令,rename 是先使用第二個引數的萬用字元匹配所有後綴為 .txt 的檔案,然後使用第一個引數提供的正則表示式將匹配的這些檔案的 .txt 字尾替換為 .c
cat,tac 和 nl 命令檢視檔案:前兩個命令都是用來列印檔案內容到標準輸出(終端),其中 cat 為正序顯示,tac 為倒序顯示
標準輸入輸出:當我們執行一個 shell 命令列時通常會自動開啟三個標準檔案,即標準輸入檔案(stdin),預設對應終端的鍵盤、標準輸出檔案(stdout)和標準錯誤輸出檔案(stderr),後兩個檔案都對應被重定向到終端的螢幕,以便我們能直接看到輸出內容。程序將從標準輸入檔案中得到輸入資料,將正常輸出資料輸出到標準輸出檔案,而將錯誤資訊送到標準錯誤檔案中。
$ cat -n passwd:可以加上 -n 引數顯示行號,
$nl 命令,新增行號並列印,這是個比 cat -n 更專業的行號列印命令
-b : 指定新增行號的方式,主要有兩種:
-b a:表示無論是否為空行,同樣列出行號("cat -n"就是這種方式)
-b t:只列出非空行的編號並列出(預設為這種方式)
-n : 設定行號的樣式,主要有三種:
-n ln:在行號欄位最左端顯示
-n rn:在行號欄位最右邊顯示,且不加 0
-n rz:在行號欄位最右邊顯示,且加 0
-w : 行號欄位佔用的位數(預設為 6 位)
使用 more 和 less 命令分頁檢視檔案:其中 more 命令比較簡單,只能向一個方向滾動,而 less 為基於 more 和 vi
可以使用 Enter 鍵向下滾動一行,使用 Space 鍵向下滾動一屏,按下 h 顯示幫助,q 退出
$tail:
甚至更直接的只看一行, 加上 -n 引數,後面緊跟行數:
引數 -f,這個引數可以實現不停地讀取某個檔案的內容並顯示。這可以讓我們動態檢視日誌,達到實時監視的目的
$file:file 命令檢視檔案的型別
5.環境變數與檔案查詢
使用 declare 命令建立一個變數名為 tmp 的變數:
$ declare tmp
使用 = 號賦值運算子,將變數 tmp 賦值為 jerry:
$ tmp=jerry
讀取變數的值,使用 echo 命令和 $ 符號($ 符號用於表示引用一個變數的值,初學者經常忘記輸入):
$ echo $tmp
Shell 的環境變數作用於自身和它的子程序。在所有的 UNIX 和類 UNIX 系統中,每個程序都有其各自的環境變數設定,且預設情況下,當一個程序被建立時,除了建立過程中明確指定的話,它將繼承其父程序的絕大部分環境設定。Shell 程式也作為一個程序執行在作業系統之上,而我們在 Shell 中執行的大部分命令都將以 Shell 的子程序的方式執行
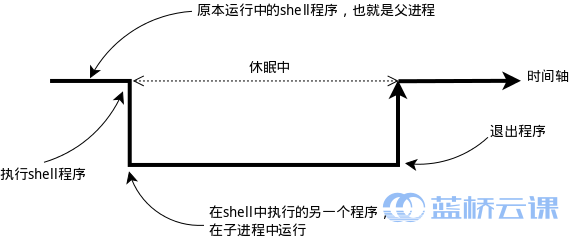
通常我們會涉及到的變數型別有三種:
當前 Shell 程序私有使用者自定義變數,如上面我們建立的 tmp 變數,只在當前 Shell 中有效。
Shell 本身內建的變數。
從自定義變數匯出的環境變數。
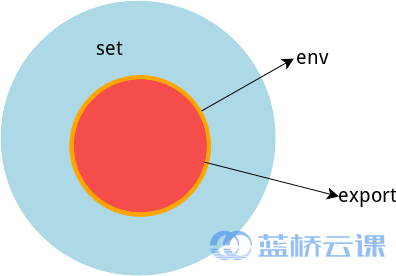
也有三個與上述三種環境變數相關的命令:set,env,export。這三個命令很相似,都是用於列印環境變數資訊,區別在於涉及的變數範圍不同。詳見下表:
命 令 說 明
set 顯示當前 Shell 所有變數,包括其內建環境變數(與 Shell 外觀等相關),使用者自定義變數及匯出的環境變數。
env 顯示與當前使用者相關的環境變數,還可以讓命令在指定環境中執行。
export 顯示從 Shell 中匯出成環境變數的變數,也能通過它將自定義變數匯出為環境變數。
按變數的生存週期來劃分,Linux 變數可分為兩類:
永久的:需要修改配置檔案,變數永久生效;
臨時的:使用 export 命令列宣告即可,變數在關閉 shell 時失效。
這裡介紹兩個重要檔案 /etc/bashrc(有的 Linux 沒有這個檔案) 和 /etc/profile ,它們分別存放的是 shell 變數和環境變數。還有要注意區別的是每個使用者目錄下的一個隱藏檔案:
.profile 可以用 ls -a 檢視
cd /home/jerry
ls -a
這個 .profile 只對當前使用者永久生效。而寫在 /etc/profile 裡面的是對所有使用者永久生效,所以如果想要新增一個永久生效的環境變數,只需要開啟 /etc/profile,在最後加上你想新增的環境變數就好啦。
Shell 中輸入一個命令,Shell 是怎麼知道去哪找到這個命令然後執行的呢?這是通過環境變數 PATH 來進行搜尋的
$ echo $PATH:檢視 PATH 環境變數的內容:
預設情況下你會看到如下輸出:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games,系統就會按照 PATH 中設定的路徑按照順序依次到目錄中去查詢,如果存在同名的命令,則執行先找到的那個。
$ gedit hello_shell.sh:建立一個 Shell 指令碼檔案:
建立一個 C 語言“ hello world ”程式:
$ gedit hello_world.c
#include <stdio.h>
int main(void)
{
printf("hello world!\n");
return 0;
}
儲存後使用 gcc 生成可執行檔案:gcc 生成二進位制檔案預設具有可執行許可權,不需要修改
$ gcc -o hello_world hello_world.c
$ PATH=$PATH:/home/shiyanlou/mybin:在前面我們應該注意到 PATH 裡面的路徑是以 : 作為分割符的,所以我們可以這樣新增自定義路徑
在每個使用者的 home 目錄中有一個 Shell 每次啟動時會預設執行一個配置指令碼,以初始化環境,包括新增一些使用者自定義環境變數等等。zsh 的配置檔案是 .zshrc,相應 Bash 的配置檔案為 .bashrc 。它們在 etc 下還都有一個或多個全域性的配置檔案,不過我們一般只修改使用者目錄下的配置檔案
我們可以簡單地使用下面命令直接新增內容到 .zshrc 中:
$ echo "PATH=$PATH:/home/shiyanlou/mybin" >> .zshrc
上述命令中 >> 表示將標準輸出以追加的方式重定向到一個檔案中,注意前面用到的 > 是以覆蓋的方式重定向到一個檔案中,使用的時候一定要注意分辨。在指定檔案不存在的情況下都會建立新的檔案
$ unset temp:變數刪除,可以使用 unset 命令刪除一個環境變數
$ source .zshrc:環境變數立即生效,
source 命令還有一個別名就是 .,注意與表示當前路徑的那個點區分開,雖然形式不一樣,但作用和使用方式一樣,上面的命令如果替換成 . 的方式就該是:
$ . ./.zshrc
注意第一個點後面有一個空格,而且後面的檔案必須指定完整的絕對或相對路徑名,source 則不需要
與搜尋相關的命令常用的有 whereis,which,find 和 locate
whereis 簡單快速:whereis 只能搜尋二進位制檔案(-b),man 幫助檔案(-m)和原始碼檔案(-s)。如果想要獲得更全面的搜尋結果可以使用 locate 命令。
locate 快而全:它可以用來查詢指定目錄下的不同檔案型別,如查詢 /etc 下所有以 sh 開頭的檔案
which 小而精:因為它只從 PATH 環境變數指定的路徑中去搜索命令
find 精而細:這條命令表示去 /etc/ 目錄下面 ,搜尋名字叫做 interfaces 的檔案或者目錄。這是 find 命令最常見的格式,千萬記住 find 的第一個引數是要搜尋的地方:$ sudo find /etc/ -name interfaces
6.檔案打包和解壓縮
檔案字尾名 說明
*.zip zip 程式打包壓縮的檔案
*.rar rar 程式壓縮的檔案
*.7z 7zip 程式壓縮的檔案
*.tar tar 程式打包,未壓縮的檔案
*.gz gzip 程式(GNU zip)壓縮的檔案
*.xz xz 程式壓縮的檔案
*.bz2 bzip2 程式壓縮的檔案
*.tar.gz tar 打包,gzip 程式壓縮的檔案
*.tar.xz tar 打包,xz 程式壓縮的檔案
*tar.bz2 tar 打包,bzip2 程式壓縮的檔案
*.tar.7z tar 打包,7z 程式壓縮的檔案
zip 壓縮打包程式:-r 引數表示遞迴打包包含子目錄的全部內容,-q 引數表示為安靜模式,即不向螢幕輸出資訊,-o,表示輸出檔案,需在其後緊跟打包輸出檔名。後面使用 du 命令檢視打包後文件的大小(後面會具體說明該命令)
$ cd /home/shiyanlou
$ zip -r -q -o shiyanlou.zip /home/shiyanlou/Desktop
$ du -h shiyanlou.zip
$ file shiyanlou.zip
$ zip -r -9 -q -o shiyanlou_9.zip /home/shiyanlou/Desktop -x ~/*.zip
這裡添加了一個引數用於設定壓縮級別 -[1-9],1 表示最快壓縮但體積大,9 表示體積最小但耗時最久。最後那個 -x 是為了排除我們上一次建立的 zip 檔案,否則又會被打包進這一次的壓縮檔案中,注意:這裡只能使用絕對路徑,否則不起作用
$ unzip shiyanlou.zip:將 shiyanlou.zip 解壓到當前目錄
$ unzip -q shiyanlou.zip -d ziptest:使用安靜模式,將檔案解壓到指定目錄,指定目錄不存在,將會自動建立。
$ unzip -l shiyanlou.zip:如果你不想解壓只想檢視壓縮包的內容你可以使用 -l 引數
tar:tar 原本只是一個打包工具,只是同時還是實現了對 7z、gzip、xz、bzip2 等工具的支援,這些壓縮工具本身只能實現對檔案或目錄(單獨壓縮目錄中的檔案)的壓縮,沒有實現對檔案的打包壓縮,所以我們也無需再單獨去學習其他幾個工具,tar 的解壓和壓縮都是同一個命令,只需引數不同,使用比較方便
建立一個 tar 包:
$ tar -cf shiyanlou.tar /home/shiyanlou/Desktop
上面命令中,-c 表示建立一個 tar 包檔案,-f 用於指定建立的檔名,注意檔名必須緊跟在 -f 引數之後,比如不能寫成 tar -fc shiyanlou.tar,可以寫成 tar -f shiyanlou.tar -c ~。你還可以加上 -v 引數以可視的的方式輸出打包的檔案。上面會自動去掉表示絕對路徑的 /,你也可以使用 -P 保留絕對路徑符。
解包一個檔案(-x 引數)到指定路徑的已存在目錄(-C 引數):
$ mkdir tardir
$ tar -xf shiyanlou.tar -C tardir
只檢視不解包檔案 -t 引數:
$ tar -tf shiyanlou.tar
說了這麼多,其實平常使用的引數並沒有那麼複雜,只需要記住常用的組合就可以了。 常用命令:
zip:
打包 :zip something.zip something (目錄請加 -r 引數)
解包:unzip something.zip
指定路徑:-d 引數
tar:
打包:tar -cf something.tar something
解包:tar -xf something.tar
指定路徑:-C 引數
7.檔案系統操作與磁碟管理
$ df:使用 df 命令檢視磁碟的容量
物理主機上的 /dev/sda2 是對應著主機硬碟的分割槽,後面的數字表示分割槽號,數字前面的字母 a 表示第幾塊硬碟(也可能是可移動磁碟),你如果主機上有多塊硬碟則可能還會出現 /dev/sdb,/dev/sdc 這些磁碟裝置都會在 /dev 目錄下以檔案的存在形式
$ df -h:看懂的方式展示
$du:使用 du 命令檢視目錄的容量
這個命令前面其實已經用了很多次了:
# 默認同樣以 塊 的大小展示
$ du
# 加上`-h`引數,以更易讀的方式展示
$ du -h
-d引數指定檢視目錄的深度
# 只檢視1級目錄的資訊
$ du -h -d 0 ~
# 檢視2級
$ du -h -d 1 ~
8.Linux幫助命令:
內建命令實際上是 shell 程式的一部分,其中包含的是一些比較簡單的 Linux 系統命令,這些命令是寫在bash原始碼的builtins裡面的,由 shell 程式識別並在 shell 程式內部完成執行,通常在 Linux 系統載入執行時 shell 就被載入並駐留在系統記憶體中。而且解析內部命令 shell 不需要建立子程序,因此其執行速度比外部命令快。比如:history、cd、exit 等等。
外部命令是 Linux 系統中的實用程式部分,因為實用程式的功能通常都比較強大,所以其包含的程式量也會很大,在系統載入時並不隨系統一起被載入到記憶體中,而是在需要時才將其調入記憶體。雖然其不包含在 shell 中,但是其命令執行過程是由 shell 程式控制的。外部命令是在 Bash 之外額外安裝的,通常放在/bin,/usr/bin,/sbin,/usr/sbin等等。比如:ls、vi等。
type 命令來區分命令是內建的還是外部的。例如這兩個得出的結果是不同的
type exit
type vim
$help:因為 help 命令是用於顯示 shell 內建命令的簡要幫助資訊。幫助資訊中顯示有該命令的簡要說明以及一些引數的使用以及說明,一定記住 help 命令只能用於顯示內建命令的幫助資訊
其實外部命令基本上都有一個引數--help,這樣就可以得到相應的幫助
$man:man 工具是顯示系統手冊頁中的內容,也就是一本電子版的字典,這些內容大多數都是對命令的解釋資訊,還有一些相關的描述。通過檢視系統文件中的 man 也可以得到程式的更多相關資訊和 Linux 的更多特性。
$info:info 來自自由軟體基金會的 GNU 專案,是 GNU 的超文字幫助系統,能夠更完整的顯示出 GNU 資訊。所以得到的資訊當然更多
9.crontab:
Linux 系統的計劃工具:crontab 命令常見於 Unix 和類 Unix 的作業系統之中(Linux 就屬於類 Unix 作業系統),用於設定週期性被執行的指令
crontab 命令從輸入裝置讀取指令,並將其存放於 crontab 檔案中,以供之後讀取和執行。通常,crontab 儲存的指令被守護程序啟用,crond 為其守護程序,crond 常常在後臺執行,每一分鐘會檢查一次是否有預定的作業需要執行
通過 crontab 命令,我們可以在固定的間隔時間執行指定的系統指令或 shell script 指令碼。時間間隔的單位可以是分鐘、小時、日、月、周的任意組合。
這裡我們看一看crontab 的格式
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
$crontab -e:新增一個計劃任務
$crontab -l :添加了哪些任務
是否成功的在後臺啟動,默默的幫我們做事,若是沒有就得執行上文準備中的第二步了
ps aux | grep cron or pgrep cron
$sudo tail -f /var/log/syslog:我們通過這樣一個命令可以檢視到執行任務命令之後在日誌中的資訊反饋
每個使用者使用 crontab -e 新增計劃任務,都會在 /var/spool/cron/crontabs 中新增一個該使用者自己的任務文件,這樣目的是為了隔離。
如果是系統級別的定時任務,應該如何處理?只需要以 sudo 許可權編輯 /etc/crontab 檔案就可以。
cron 服務監測時間最小單位是分鐘,所以 cron 會每分鐘去讀取一次 /etc/crontab 與 /var/spool/cron/crontabs 裡面的內容。
每個目錄的作用:
/etc/cron.daily,目錄下的指令碼會每天執行一次,在每天的6點25分時執行;
/etc/cron.hourly,目錄下的指令碼會每個小時執行一次,在每小時的17分鐘時執行;
/etc/cron.monthly,目錄下的指令碼會每月執行一次,在每月1號的6點52分時執行;
/etc/cron.weekly,目錄下的指令碼會每週執行一次,在每週第七天的6點47分時執行;
系統預設執行時間可以根據需求進行修改。
10.命令執行順序控制與管道
簡單的順序執行你可以使用;來完成
上面的&&就是用來實現選擇性執行的,它表示如果前面的命令執行結果(不是表示終端輸出的內容,而是表示命令執行狀態的結果)返回0則執行後面的,否則不執行,你可以從$?環境變數獲取上一次命令的返回結果
當上一條命令執行結果為≠0($?≠0)時則執行它後面的命令:
除了上述基本的使用之外,我們還可以結合著&&和||來實現一些操作,比如:
$ which cowsay>/dev/null && echo "exist" || echo "not exist"
管道是什麼?管道是一種通訊機制,通常用於程序間的通訊(也可通過socket進行網路通訊),它表現出來的形式就是將前面每一個程序的輸出(stdout)直接作為下一個程序的輸入(stdin)。
使用一些過濾程式時經常會用到的就是匿名管道,在命令列中由|分隔符表示,|在前面的內容中我們已經多次使用到了。具名管道簡單的說就是有名字的管道,通常只會在源程式中用到具名管道。下面我們就將通過一些常用的可以使用管道的"過濾程式"來幫助你熟練管道的使用。
$ ls -al /etc | less:有太多內容,螢幕不能完全顯示,這時候可以使用滾動條或快捷鍵滾動視窗來檢視。不過這時候可以使用管道
$cut:cut 命令,列印每一行的某一欄位
列印/etc/passwd檔案中每一行的前N個字元:
# 前五個(包含第五個)
$ cut /etc/passwd -c -5
# 前五個之後的(包含第五個)
$ cut /etc/passwd -c 5-
# 第五個
$ cut /etc/passwd -c 5
# 2到5之間的(包含第五個)
$ cut /etc/passwd -c 2-5
grep 命令,在文字中或 stdin 中查詢匹配字串,grep命令是很強大的,也是相當常用的一個命令,它結合正則表示式可以實現很複雜卻很高效的匹配和查詢
-r 引數表示遞迴搜尋子目錄中的檔案,-n表示列印匹配項行號,-I表示忽略二進位制檔案。這個操作實際沒有多大意義,但可以感受到grep命令的強大與實用
wc 命令用於統計並輸出一個檔案中行、單詞和位元組的數目,比如輸出/etc/passwd檔案的統計資訊
分別只輸出行數、單詞數、位元組數、字元數和輸入文字中最長一行的位元組數:
# 行數
$ wc -l /etc/passwd
# 單詞數
$ wc -w /etc/passwd
# 位元組數
$ wc -c /etc/passwd
# 字元數
$ wc -m /etc/passwd
# 最長行位元組數
$ wc -L /etc/passwd
sort 排序命令
預設為字典排序:
$ cat /etc/passwd | sort
反轉排序:
$ cat /etc/passwd | sort -r
按特定欄位排序:
$ cat /etc/passwd | sort -t':' -k 3
上面的-t引數用於指定欄位的分隔符,這裡是以":"作為分隔符;-k 欄位號用於指定對哪一個欄位進行排序。這裡/etc/passwd檔案的第三個欄位為數字,預設情況下是以字典序排序的,如果要按照數字排序就要加上-n引數:
$ cat /etc/passwd | sort -t':' -k 3 -n
uniq命令可以用於過濾或者輸出重複行,過濾重複行
11.簡單的文字處理
$tr: 命令可以用來刪除一段文字資訊中的某些文字。或者將其進行轉換
常用的選項有:
選項 說明
-d 刪除和set1匹配的字元,注意不是全詞匹配也不是按字元順序匹配
-s 去除set1指定的在輸入文字中連續並重復的字元
操作舉例:
# 刪除 "hello shiyanlou" 中所有的'o','l','h'
$ echo 'hello shiyanlou' | tr -d 'olh'
# 將"hello" 中的ll,去重為一個l
$ echo 'hello' | tr -s 'l'
# 將輸入文字,全部轉換為大寫或小寫輸出
$ echo 'input some text here' | tr '[:lower:]' '[:upper:]'
# 上面的'[:lower:]' '[:upper:]'你也可以簡單的寫作'[a-z]' '[A-Z]',當然反過來將大寫變小寫也是可以的
$col :命令可以將Tab換成對等數量的空格鍵,或反轉這個操作
常用的選項有:
選項 說明
-x 將Tab轉換為空格
-h 將空格轉換為Tab(預設選項)
操作舉例:
# 檢視 /etc/protocols 中的不可見字元,可以看到很多 ^I ,這其實就是 Tab 轉義成可見字元的符號
$ cat -A /etc/protocols
# 使用 col -x 將 /etc/protocols 中的 Tab 轉換為空格,然後再使用 cat 檢視,你發現 ^I 不見了
$ cat /etc/protocols | col -x | cat -A
$join:命令就是用於將兩個檔案中包含相同內容的那一行合併在一起
常用的選項有:
選項 說明
-t 指定分隔符,預設為空格
-i 忽略大小寫的差異
-1 指明第一個檔案要用哪個欄位來對比,預設對比第一個欄位
-2 指明第二個檔案要用哪個欄位來對比,預設對比第一個欄位
操作舉例:
# 建立兩個檔案
$ echo '1 hello' > file1
$ echo '1 shiyanlou' > file2
$ join file1 file2
# 將/etc/passwd與/etc/shadow兩個檔案合併,指定以':'作為分隔符
$ sudo join -t':' /etc/passwd /etc/shadow
# 將/etc/passwd與/etc/group兩個檔案合併,指定以':'作為分隔符, 分別比對第4和第3個欄位
$ sudo join -t':' -1 4 /etc/passwd -2 3 /etc/group
$paste:這個命令與join 命令類似,它是在不對比資料的情況下,簡單地將多個檔案合併一起,以Tab隔開。
使用方式:
paste [option] file...
常用的選項有:
選項 說明
-d 指定合併的分隔符,預設為Tab
-s 不合併到一行,每個檔案為一行
操作舉例:
$ echo hello > file1
$ echo shiyanlou > file2
$ echo www.shiyanlou.com > file3
$ paste -d ':' file1 file2 file3
$ paste -s file1 file2 file3
12.資料流重定向
Linux 預設提供了三個特殊裝置,用於終端的顯示和輸出,分別為stdin(標準輸入,對應於你在終端的輸入),stdout(標準輸出,對應於終端的輸出),stderr(標準錯誤輸出,對應於終端的輸出)。
檔案描述符 裝置檔案 說明
0 /dev/stdin 標準輸入
1 /dev/stdout 標準輸出
2 /dev/stderr 標準錯誤
檔案描述符:檔案描述符在形式上是一個非負整數。實際上,它是一個索引值,指向核心為每一個程序所維護的該程序開啟檔案的記錄表。當程式開啟一個現有檔案或者建立一個新檔案時,核心向程序返回一個檔案描述符。在程式設計中,一些涉及底層的程式編寫往往會圍繞著檔案描述符展開。但是檔案描述符這一概念往往只適用於 UNIX、Linux 這樣的作業系統。
管道預設是連線前一個命令的輸出到下一個命令的輸入,而重定向通常是需要一個檔案來建立兩個命令的連線
重定向標準輸出到檔案,這是一個很實用的操作,另一個很實用的操作是將標準錯誤重定向,標準輸出和標準錯誤都被指向偽終端的螢幕顯示,所以我們經常看到的一個命令的輸出通常是同時包含了標準輸出和標準錯誤的結果的
# 將標準錯誤重定向到標準輸出,再將標準輸出重定向到檔案,注意要將重定向到檔案寫到前面
$ cat Documents/test.c hello.c >somefile 2>&1
# 或者只用bash提供的特殊的重定向符號"&"將標準錯誤和標準輸出同時重定向到檔案
$ cat Documents/test.c hello.c &>somefilehell
注意你應該在輸出重定向檔案描述符前加上&,否則shell會當做重定向到一個檔名為1的檔案中
使用tee命令同時重定向到多個檔案
你可能還有這樣的需求,除了需要將輸出重定向到檔案,也需要將資訊列印在終端。那麼你可以使用tee命令來實現:
$ echo 'hello shiyanlou' | tee hello
13.正則表示式
而正則表示式作為這三個命令的一種使用方式(命令輸出中可以包含正則表示式)
什麼是正則表示式呢?
正則表示式,又稱正規表示式、正規表示法、正規表示式、規則表示式、常規表示法(英語:Regular Expression,在程式碼中常簡寫為 regex、regexp 或 RE),電腦科學的一個概念。正則表示式使用單個字串來描述、匹配一系列符合某個句法規則的字串。在很多文字編輯器裡,正則表示式通常被用來檢索、替換那些符合某個模式的文字。
許多程式設計語言都支援利用正則表示式進行字串操作。例如,在 Perl 中就內建了一個功能強大的正則表示式引擎。正則表示式這個概念最初是由 UNIX 中的工具軟體(例如sed和grep)普及開的。正則表示式通常縮寫成“regex”,單數有 regexp、regex,複數有 regexps、regexes、regexen。
簡單的說形式和功能上正則表示式和我們前面講的萬用字元很像,不過它們之間又有很大差別,特別在於一些特殊的匹配字元的含義上,希望初學者注意不要將兩者弄混淆。
假設我們有這樣一個文字檔案,包含"shiyanlou",和"shilouyan"這兩個字串,同樣一個表示式:
shi*
如果這作為一個正則表示式,它將只能匹配 shi,而如果不是作為正則表示式*作為一個萬用字元,則將同時匹配這兩個字串。這是為什麼呢?因為在正則表示式中*表示匹配前面的子表示式(這裡就是它前面一個字元)零次或多次,比如它可以匹配"sh","shii","shish","shiishi"等等,而作為萬用字元表示匹配萬用字元後面任意多個任意字元,所以它可以匹配"shiyanlou",和"shilouyan"兩個字元。
體驗完了,下面就來開始正式學習正則表示式吧。
2.2 基本語法
一個正則表示式通常被稱為一個模式(pattern),為用來描述或者匹配一系列符合某個句法規則的字串。
選擇
|豎直分隔符表示選擇,例如"boy|girl"可以匹配"boy"或者"girl"
數量限定
數量限定除了我們舉例用的*,還有+加號,?問號,如果在一個模式中不加數量限定符則表示出現一次且僅出現一次:
+表示前面的字元必須出現至少一次(1次或多次),例如,"goo+gle",可以匹配"gooogle","goooogle"等;
?表示前面的字元最多出現一次(0次或1次),例如,"colou?r",可以匹配"color"或者"colour";
*星號代表前面的字元可以不出現,也可以出現一次或者多次(0次、或1次、或多次),例如,“0*42”可以匹配42、042、0042、00042等。
範圍和優先順序
()圓括號可以用來定義模式字串的範圍和優先順序,這可以簡單的理解為是否將括號內的模式串作為一個整體。例如,"gr(a|e)y"等價於"gray|grey",(這裡體現了優先順序,豎直分隔符用於選擇a或者e而不是gra和ey),"(grand)?father"匹配father和grandfather(這裡體驗了範圍,?將圓括號內容作為一個整體匹配)。
語法(部分)
正則表示式有多種不同的風格,下面列舉一些常用的作為 PCRE 子集的適用於perl和python程式語言及grep或egrep的正則表示式匹配規則:(由於markdown表格解析的問題,下面的豎直分隔符用全形字元代替,實際使用時請換回半形字元)
PCRE(Perl Compatible Regular Expressions中文含義:perl語言相容正則表示式)是一個用 C 語言編寫的正則表示式函式庫,由菲利普.海澤(Philip Hazel)編寫。PCRE是一個輕量級的函式庫,比Boost 之類的正則表示式庫小得多。PCRE 十分易用,同時功能也很強大,效能超過了 POSIX 正則表示式庫和一些經典的正則表示式庫。
字元 描述
\ 將下一個字元標記為一個特殊字元、或一個原義字元。例如,“n”匹配字元“n”。“\n”匹配一個換行符。序列“\\”匹配“\”而“\(”則匹配“(”。
^ 匹配輸入字串的開始位置。
$ 匹配輸入字串的結束位置。
{n} n是一個非負整數。匹配確定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的兩個o。
{n,} n是一個非負整數。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等價於“o+”。“o{0,}”則等價於“o*”。
{n,m} m和n均為非負整數,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”將匹配“fooooood”中的前三個o。“o{0,1}”等價於“o?”。請注意在逗號和兩個數之間不能有空格。
* 匹配前面的子表示式零次或多次。例如,zo*能匹配“z”、“zo”以及“zoo”。*等價於{0,}。
+ 匹配前面的子表示式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等價於{1,}。
? 匹配前面的子表示式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等價於{0,1}。
? 當該字元緊跟在任何一個其他限制符(*,+,?,{n},{n,},{n,m})後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配所搜尋的字串,而預設的貪婪模式則儘可能多的匹配所搜尋的字串。例如,對於字串“oooo”,“o+?”將匹配單個“o”,而“o+”將匹配所有“o”。
. 匹配除“\n”之外的任何單個字元。要匹配包括“\n”在內的任何字元,請使用像“(.|\n)”的模式。
(pattern) 匹配pattern並獲取這一匹配的子字串。該子字串用於向後引用。要匹配圓括號字元,請使用“\(”或“\)”。
x|y 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”則匹配“zood”或“food”。
[xyz] 字元集合(character class)。匹配所包含的任意一個字元。例如,“[abc]”可以匹配“plain”中的“a”。其中特殊字元僅有反斜線\保持特殊含義,用於轉義字元。其它特殊字元如星號、加號、各種括號等均作為普通字元。脫字元^如果出現在首位則表示負值字元集合;如果出現在字串中間就僅作為普通字元。連字元 - 如果出現在字串中間表示字元範圍描述;如果如果出現在首位則僅作為普通字元。
[^xyz] 排除型(negate)字元集合。匹配未列出的任意字元。例如,“[^abc]”可以匹配“plain”中的“plin”。
[a-z] 字元範圍。匹配指定範圍內的任意字元。例如,“[a-z]”可以匹配“a”到“z”範圍內的任意小寫字母字元。
[^a-z] 排除型的字元範圍。匹配任何不在指定範圍內的任意字元。例如,“[^a-z]”可以匹配任何不在“a”到“z”範圍內的任意字元。
優先順序
優先順序為從上到下從左到右,依次降低:
運算子 說明
\ 轉義符
(), (?:), (?=), [] 括號和中括號
*、+、?、{n}、{n,}、{n,m} 限定符
^、$、\任何元字元 定位點和序列
| 選擇
更多正則表示式的內容可以參考以下連結:
正則表示式wiki
幾種正則表示式引擎的語法差異
各語言各平臺對正則表示式的支援
regex的思導圖:
三、grep模式匹配命令
上面空談了那麼多正則表示式的內容也並沒有提及具體該如何使用它,實在枯燥,如果說正則表示式是一門武功,那它也只能算得上一些口訣招式罷了,要把它真正練起來還得需要一些兵器在手才行,這裡我們要介紹的grep命令以及後面要講的sed,awk這些就該算作是這樣的兵器了。
3.1 基本操作
grep命令用於列印輸出文字中匹配的模式串,它使用正則表示式作為模式匹配的條件。grep支援三種正則表示式引擎,分別用三個引數指定:
引數 說明
-E POSIX擴充套件正則表示式,ERE
-G POSIX基本正則表示式,BRE
-P Perl正則表示式,PCRE
不過在你沒學過perl語言的大多數情況下你將只會使用到ERE和BRE,所以我們接下來的內容都不會討論到PCRE中特有的一些正則表示式語法(它們之間大部分內容是存在交集的,所以你不用擔心會遺漏多少重要內容)
在通過grep命令使用正則表示式之前,先介紹一下它的常用引數:
引數 說明
-b 將二進位制檔案作為文字來進行匹配
-c 統計以模式匹配的數目
-i 忽略大小寫
-n 顯示匹配文字所在行的行號
-v 反選,輸出不匹配行的內容
-r 遞迴匹配查詢
-A n n為正整數,表示after的意思,除了列出匹配行之外,還列出後面的n行
-B n n為正整數,表示before的意思,除了列出匹配行之外,還列出前面的n行
--color=auto 將輸出中的匹配項設定為自動顏色顯示
注:在大多數發行版中是預設設定了grep的顏色的,你可以通過引數指定或修改GREP_COLOR環境變數。
3.2 使用正則表示式
使用基本正則表示式,BRE
位置
查詢/etc/group檔案中以"shiyanlou"為開頭的行
$ grep 'shiyanlou' /etc/group
$ grep '^shiyanlou' /etc/group
數量
# 將匹配以'z'開頭以'o'結尾的所有字串
$ echo 'zero\nzo\nzoo' | grep 'z.*o'
# 將匹配以'z'開頭以'o'結尾,中間包含一個任意字元的字串
$ echo 'zero\nzo\nzoo' | grep 'z.o'
# 將匹配以'z'開頭,以任意多個'o'結尾的字串
$ echo 'zero\nzo\nzoo' | grep 'zo*'
注意:其中\n為換行符
選擇
# grep預設是區分大小寫的,這裡將匹配所有的小寫字母
$ echo '1234\nabcd' | grep '[a-z]'
# 將匹配所有的數字
$ echo '1234\nabcd' | grep '[0-9]'
# 將匹配所有的數字
$ echo '1234\nabcd' | grep '[[:digit:]]'
# 將匹配所有的小寫字母
$ echo '1234\nabcd' | grep '[[:lower:]]'
# 將匹配所有的大寫字母
$ echo '1234\nabcd' | grep '[[:upper:]]'
# 將匹配所有的字母和數字,包括0-9,a-z,A-Z
$ echo '1234\nabcd' | grep '[[:alnum:]]'
# 將匹配所有的字母
$ echo '1234\nabcd' | grep '[[:alpha:]]'
下面包含完整的特殊符號及說明:
特殊符號 說明
[:alnum:] 代表英文大小寫字母及數字,亦即 0-9, A-Z, a-z
[:alpha:] 代表任何英文大小寫字母,亦即 A-Z, a-z
[:blank:] 代表空白鍵與 [Tab] 按鍵兩者
[:cntrl:] 代表鍵盤上面的控制按鍵,亦即包括 CR, LF, Tab, Del.. 等等
[:digit:] 代表數字而已,亦即 0-9
[:graph:] 除了空白位元組 (空白鍵與 [Tab] 按鍵) 外的其他所有按鍵
[:lower:] 代表小寫字母,亦即 a-z
[:print:] 代表任何可以被列印出來的字元
[:punct:] 代表標點符號 (punctuation symbol),亦即:" ' ? ! ; : # $...
[:upper:] 代表大寫字母,亦即 A-Z
[:space:] 任何會產生空白的字元,包括空白鍵, [Tab], CR 等等
[:xdigit:] 代表 16 進位的數字型別,因此包括: 0-9, A-F, a-f 的數字與位元組
注意:之所以要使用特殊符號,是因為上面的[a-z]不是在所有情況下都管用,這還與主機當前的語系有關,即設定在LANG環境變數的值,zh_CN.UTF-8的話[a-z],即為所有小寫字母,其它語系可能是大小寫交替的如,"a A b B...z Z",[a-z]中就可能包含大寫字母。所以在使用[a-z]時請確保當前語系的影響,使用[:lower:]則不會有這個問題。
# 排除字元
$ $ echo 'geek\ngood' | grep '[^o]'
注意:當^放到中括號內為排除字元,否則表示行首。
使用擴充套件正則表示式,ERE
要通過grep使用擴充套件正則表示式需要加上-E引數,或使用egrep。
數量
# 只匹配"zo"
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1}'
# 匹配以"zo"開頭的所有單詞
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1,}'
注意:推薦掌握{n,m}即可,+,?,*,這幾個不太直觀,且容易弄混淆。
選擇
# 匹配"www.shiyanlou.com"和"www.google.com"
$ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -E 'www\.(shiyanlou|google)\.com'
# 或者匹配不包含"baidu"的內容
$ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -Ev 'www\.baidu\.com'
注意:因為.號有特殊含義,所以需要轉義。
關於正則表示式和grep命令的內容就介紹這麼多,下面會介紹兩個更強大的工具sed和awk,但同樣也正是因為這兩個工具的強大,我們的內容無法包含它們的全部,這裡將只對基本內容作介紹。
四、sed 流編輯器
sed工具在 man 手冊裡面的全名為"sed - stream editor for filtering and transforming text ",意即,用於過濾和轉換文字的流編輯器。
在 Linux/UNIX 的世界裡敢稱為編輯器的工具,大都非等閒之輩,比如前面的"vi/vim(編輯器之神)","emacs(神的編輯器)","gedit"這些個編輯器。sed與上述的最大不同之處在於它是一個非互動式的編輯器,下面我們就開始介紹sed這個編輯器。
4.1 sed常用引數介紹
sed 命令基本格式:
sed [引數]... [執行命令] [輸入檔案]...
# 形如:
$ sed -i 's/sad/happy/' test # 表示將test檔案中的"sad"替換為"happy"
引數 說明
-n 安靜模式,只打印受影響的行,預設列印輸入資料的全部內容
-e 用於在指令碼中新增多個執行命令一次執行,在命令列中執行多個命令通常不需要加該引數
-f filename 指定執行filename檔案中的命令
-r 使用擴充套件正則表示式,預設為標準正則表示式
-i 將直接修改輸入檔案內容,而不是列印到標準輸出裝置
4.2 sed編輯器的執行命令(這裡”執行“解釋為名詞)
sed執行命令格式:
[n1][,n2]command
[n1][~step]command
# 其中一些命令可以在後面加上作用範圍,形如:
$ sed -i 's/sad/happy/g' test # g表示全域性範圍
$ sed -i 's/sad/happy/4' test # 4表示指定行中的第四個匹配字串
其中n1,n2表示輸入內容的行號,它們之間為,逗號則表示從n1到n2行,如果為~波浪號則表示從n1開始以step為步進的所有行;command為執行動作,下面為一些常用動作指令:
命令 說明
s 行內替換
c 整行替換
a 插入到指定行的後面
i 插入到指定行的前面
p 列印指定行,通常與-n引數配合使用
d 刪除指定行
4.3 sed操作舉例
我們先找一個用於練習的文字檔案:
$ cp /etc/passwd ~
列印指定行
# 列印2-5行
$ nl passwd | sed -n '2,5p'
# 列印奇數行
$ nl passwd | sed -n '1~2p'
行內替換
# 將輸入文字中"shiyanlou" 全域性替換為"hehe",並只打印替換的那一行,注意這裡不能省略最後的"p"命令
$ sed -n 's/shiyanlou/hehe/gp' passwd
注意: 行內替換可以結合正則表示式使用。
行間替換
$ nl passwd | grep "shiyanlou"
# 刪除第21行
$ sed -n '21c\www.shiyanlou.com' passwd
(這裡我們只把要刪的行打印出來了,並沒有真正的刪除,如果要刪除的話,請使用-i引數)
關於sed命令就介紹這麼多,你如果希望瞭解更多sed的高階用法,你可以參看如下連結:
sed簡明教程
sed單行指令碼快速參考
sed完全手冊
五、awk文字處理語言
看到上面的標題,你可能會感到驚異,難道我們這裡要學習的是一門“語言”麼,確切的說,我們是要在這裡學習awk文字處理語言,只是我們並不會在這裡學習到比較完整的關於awk的內容,還是因為前面的原因,它太強大了,它的應用無處不在,我們無法在這裡以簡短的文字描述面面俱到,如果你有目標成為一個linux系統管理員,確實想學好awk,你一不用擔心,實驗樓會在之後陸續上線linux系統管理員的學習路徑,裡面會有單獨的關於正則表示式,awk,sed等相關課程,敬請期待吧。下面的內容,我們就作為一個關於awk的入門體驗章節吧,其中會介紹一些awk的常用操作。
5.1 awk介紹
AWK是一種優良的文字處理工具,Linux及Unix環境中現有的功能最強大的資料處理引擎之一.其名稱得自於它的創始人Alfred Aho(阿爾佛雷德·艾侯)、Peter Jay Weinberger(彼得·溫伯格)和Brian Wilson Kernighan(布萊恩·柯林漢)姓氏的首個字母.AWK程式設計語言,三位建立者已將它正式定義為“樣式掃描和處理語言”。它允許您建立簡短的程式,這些程式讀取輸入檔案、為資料排序、處理資料、對輸入執行計算以及生成報表,還有無數其他的功能。最簡單地說,AWK是一種用於處理文字的程式語言工具。
在大多數linux發行版上面,實際我們使用的是gawk(GNU awk,awk的GNU版本),在我們的環境中ubuntu上,預設提供的是mawk,不過我們通常可以直接使用awk命令(awk語言的直譯器),因為系統已經為我們建立好了awk指向mawk的符號連結。
$ ll /usr/bin/awk
nawk: 在 20 世紀 80 年代中期,對 awk語言進行了更新,並不同程度地使用一種稱為 nawk(new awk) 的增強版本對其進行了替換。許多系統中仍然存在著舊的awk 直譯器,但通常將其安裝為 oawk (old awk) 命令,而 nawk 直譯器則安裝為主要的 awk 命令,也可以使用 nawk 命令。Dr. Kernighan 仍然在對 nawk 進行維護,與 gawk 一樣,它也是開放原始碼的,並且可以免費獲得; gawk: 是 GNU Project 的awk直譯器的開放原始碼實現。儘管早期的 GAWK 發行版是舊的 AWK 的替代程式,但不斷地對其進行了更新,以包含 NAWK 的特性; mawk 也是awk程式語言的一種直譯器,mawk遵循 POSIX 1003.2 (草案 11.3)定義的 AWK 語言,包含了一些沒有在AWK 手冊中提到的特色,同時 mawk 提供一小部分擴充套件,另外據說mawk是實現最快的awk
5.2 awk的一些基礎概念
awk所有的操作都是基於pattern(模式)—action(動作)對來完成的,如下面的形式:
$ pattern {action}
你可以看到就如同很多程式語言一樣,它將所有的動作操作用一對{}花括號包圍起來。其中pattern通常是表示用於匹配輸入的文字的“關係式”或“正則表示式”,action則是表示匹配後將執行的動作。在一個完整awk操作中,這兩者可以只有其中一個,如果沒有pattern則預設匹配輸入的全部文字,如果沒有action則預設為列印匹配內容到螢幕。
awk處理文字的方式,是將文字分割成一些“欄位”,然後再對這些欄位進行處理,預設情況下,awk以空格作為一個欄位的分割符,不過這不是固定的,你可以任意指定分隔符,下面將告訴你如何做到這一點。
5.3 awk命令基本格式
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
其中-F引數用於預先指定前面提到的欄位分隔符(還有其他指定欄位的方式) ,-v用於預先為awk程式指定變數,-f引數用於指定awk命令要執行的程式檔案,或者在不加-f引數的情況下直接將程式語句放在這裡,最後為awk需要處理的文字輸入,且可以同時輸入多個文字檔案。現在我們還是直接來具體體驗一下吧。
5.4 awk操作體驗
先用vim新建一個文字文件
$ vim test
包含如下內容:
I like linux
www.shiyanlou.com
使用awk將文字內容列印到終端
# "quote>" 不用輸入
$ awk '{
> print
> }' test
# 或者寫到一行
$ awk '{print}' test
說明:在這個操作中我是省略了pattern,所以awk會預設匹配輸入文字的全部內容,然後在"{}"花括號中執行動作,即print列印所有匹配項,這裡是全部文字內容
將test的第一行的每個欄位單獨顯示為一行
$ awk '{
> if(NR==1){
> print $1 "\n" $2 "\n" $3
> } else {
> print}
> }' test
# 或者
$ awk '{
> if(NR==1){
> OFS="\n"
> print $1, $2, $3
> } else {
> print}
> }' test
說明:你首先應該注意的是,這裡我使用了awk語言的分支選擇語句if,它的使用和很多高階語言如C/C++語言基本一致,如果你有這些語言的基礎,這裡將很好理解。另一個你需要注意的是NR與OFS,這兩個是awk內建的變數,NR表示當前讀入的記錄數,你可以簡單的理解為當前處理的行數,OFS表示輸出時的欄位分隔符,預設為" "空格,如上圖所見,我們將欄位分隔符設定為\n換行符,所以第一行原本以空格為欄位分隔的內容就分別輸出到單獨一行了。然後是$N其中N為相應的欄位號,這也是awk的內建變數,它表示引用相應的欄位,因為我們這裡第一行只有三個欄位,所以只引用到了$3。除此之外另一個這裡沒有出現的$0,它表示引用當前記錄(當前行)的全部內容。
將test的第二行的以點為分段的欄位換成以空格為分隔
$ awk -F'.' '{
> if(NR==2){
> print $1 "\t" $2 "\t" $3
> }}' test
# 或者
$ awk '
> BEGIN{
> FS="."
> OFS="\t" # 如果寫為一行,兩個動作語句之間應該以";"號分開
> }{
> if(NR==2){
> print $1, $2, $3
> }}' test
說明:這裡的-F引數,前面已經介紹過,它是用來預先指定待處理記錄的欄位分隔符。我們需要注意的是除了指定OFS我們還可以在print 語句中直接列印特殊符號如這裡的\t,print列印的非變數內容都需要用""一對引號包圍起來。上面另一個版本,展示了實現預先指定變數分隔符的另一種方式,即使用BEGIN,就這個表示式指示了,其後的動作將在所有動作之前執行,這裡是FS賦值了新的"."點號代替預設的" "空格
注意:首先說明一點,我們在學習和使用awk的時候應該儘可能將其作為一門程式語言來理解,這樣將會使你學習起來更容易,所以初學階段在練習awk時應該儘量按照我那樣的方式分多行按照一般程