
轉:InnoDB多版本(MVCC)實現簡要分析
InnoDB多版本(MVCC)實現簡要分析
基本知識
假設對於多版本(MVCC)的基礎知識,有所瞭解。InnoDB為了實現多版本的一致讀,採用的是基於回滾段的協議。
行結構
InnoDB表資料的組織方式為主鍵聚簇索引。由於採用索引組織表結構,記錄的ROWID是可變的(索引頁分裂的時候,Structure Modification Operation,SMO),因此二級索引中採用的是(索引鍵值, 主鍵鍵值)的組合來唯一確定一條記錄。
無論是聚簇索引,還是二級索引,其每條記錄都包含了一個DELETED BIT位,用於標識該記錄是否是刪除記錄。除此之外,聚簇索引記錄還有兩個系統列:DATA_TRX_ID
聚簇索引行結構(與多版本一致讀有關的部分,DELETED BIT省略):

二級索引行結構:
從聚簇索引行結構,與二級索引行結構可以看出,聚簇索引中包含版本資訊(事務號+回滾指標),二級索引不包含版本資訊,二級索引項的可見性如何判斷?下面將會給出。
Read View
InnoDB預設的隔離級別為Repeatable Read (RR),可重複讀。InnoDB在開始一個RR讀之前,會建立一個Read View。Read View
dulint low_limit_id; /* 事務號 >= low_limit_id的記錄,對於當前Read View都是不可見的 */
dulint up_limit_id; /* 事務號 < up_limit_id ,對於當前Read View都是可見的 */
ulint n_trx_ids; /* Number of cells in the trx_ids array */
dulint* trx_ids; /* Additional trx ids which the read should
not see: typically, these are the active
transactions at the time when the read is
serialized, except the reading transaction
itself; the trx ids in this array are in a
descending order */
dulint creator_trx_id; /* trx id of creating transaction, or
(0, 0) used in purge */
簡單來說,Read View記錄讀開始時,所有的活動事務,這些事務所做的修改對於Read View是不可見的。除此之外,所有其他的小於建立Read View的事務號的所有記錄均可見。可見包括兩層含義:
記錄可見,且Deleted bit = 0;當前記錄是可見的有效記錄。
記錄可見,且Deleted bit = 1;當前記錄是可見的刪除記錄。此記錄在本事務開始之前,已經刪除。
測試方法:
–create table and index
create table test (id int primary key, comment char(50)) engine=InnoDB;
create index test_idx on test(comment);
–Insert
insert into test values(1, ‘aaa’);
insert into test values(2, ‘bbb’);
–update primary key
update test set id = 9 where id = 1;
–update non-primary key with different value
update test set comment = ‘ccc’ where id = 9;
–update non-primary key with same value
update test set comment = ‘bbb’ where id = 2 and comment = ‘bbb’;
–read隔離級別
repeatable read(RR)
測試結果
update primary key
程式碼呼叫流程:
ha_innobase::update_row -> row_update_for_mysql -> row_upd_step -> row_upd -> row_upd_clust_step -> row_upd_clust_rec_by_insert -> btr_cur_del_mark_set_clust_rec -> row_ins_index_entry
簡單來說,就是將cluster index的舊記錄標記位刪除;插入一條新紀錄。該語句執行完之後,資料結構如下:

版本仍舊儲存在聚簇索引之中,其DATA_TRX_ID被設定為1811,Deleted bit設定為1,undo中記錄了前映象的事務id = 1809。新版本DATA_TRX_ID也為1811。通過此圖,還可以發現,雖然新老版本是一條記錄,但是在聚簇索引中是通過兩條記錄來標識的。同時,由於更新了主鍵,二級索引也需要做相應的更新(二級索引中包含主鍵項)。
update non-primary key(diff value)
更新comment欄位,程式碼呼叫流程與上面有部分不同,可以自行跟蹤,此處省略。更新操作執行完之後,索引結構變更如下:
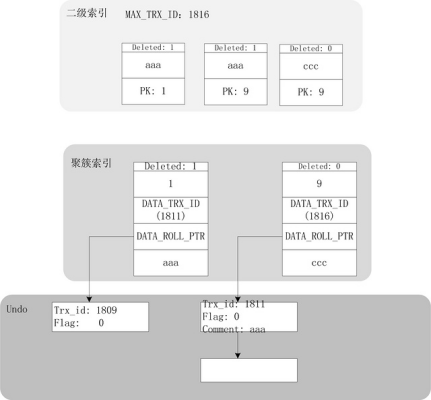
從上圖可見,更新二級索引的鍵值時,聚簇索引本身並不會產生新的記錄項,而是將舊版本資訊記錄在undo之中。與此同時,二級索引將會產生新的索引項,其PK值保持不變,指向聚簇索引的同一條記錄。細心的讀者可能會發現,二級索引頁面中有一個MAX_TRX_ID,此值記錄的是更新二級索引頁面的最大事務ID。通過MAX_TRX_ID的過濾,INNODB能夠實現大部分的輔助索引覆蓋性掃描(僅僅掃描輔助索引,不需要回聚簇索引)。具體過濾方法,將在後面的內容中給出。
update non-primary key(same value)
最後一個測試用例,是更新comment項為同樣的值。在我的測試中,更新之後的索引結構如下:
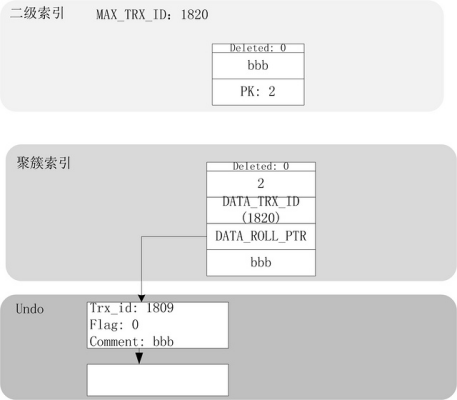
聚簇索引仍舊會更新,但是二級索引保持不變。
總結
無論是聚簇索引,還是二級索引,只要其鍵值更新,就會產生新版本。將老版本資料deleted bti設定為1;同時插入新版本。
對於聚簇索引,如果更新操作沒有更新primary key,那麼更新不會產生新版本,而是在原有版本上進行更新,老版本進入undo表空間,通過記錄上的undo指標進行回滾。
對於二級索引,如果更新操作沒有更新其鍵值,那麼二級索引記錄保持不變。
對於二級索引,更新操作無論更新primary key,或者是二級索引鍵值,都會導致二級索引產生新版本資料。
聚簇索引設定記錄deleted bit時,會同時更新DATA_TRX_ID列。老版本DATA_TRX_ID進入undo表空間;二級索引設定deleted bit時,不寫入undo。
可見性判斷
主鍵查詢
select * from test where id = 1;
針對測試1,如果1811(DATA_TRX_ID) < read_view.up_limit_id,證明被標記為刪除的記錄1可見。刪除可見 -> 無記錄返回。
針對測試1,如果1811(DATA_TRX_ID) >= read_view.low_limit_id,證明被標記為刪除的記錄1不可見,通過DATA_ROLL_PTR回滾記錄,得到DATA_TRX_ID = 1809。如果1809可見,則返回記錄(1,aaa);否則無記錄返回。
針對測試1,如果up_limit_id,low_limit_id都無法判斷可見性,那麼遍歷read_view中的trx_ids,依次對比事務id,如果在DATA_TRX_ID在trx_ids陣列中,則不可見(更新未提交)。
select * from test where id = 9;
針對測試2,如果1816可見,返回(9,ccc)。
針對測試2,如果1816不可見,通過DATA_ROLL_PTR回滾到1811,如果1811可見,返回(9, aaa)。
針對測試2,如果1811不可見,無結果返回。
select * from test where id > 0;
針對測試1,索引中,滿足條件的同一記錄,有兩個版本(版本1,delete bit =1)。那麼是否會一條記錄返回兩次呢?必定不會,這是因為pk = 1的可見性與pk = 9的可見性是一致的,同時pk = 1是標記了deleted bit的版本。如果事務ID = 1811可見。那麼pk = 1 delete可見,無記錄返回,pk = 9返回記錄;如果1811不可見,回滾到1809可見,那麼pk = 1返回記錄,pk = 9回滾後無記錄。
總結:
通過主鍵查詢記錄,需要配合read_view,記錄DATA_TRX_ID,記錄DATA_ROLL_PTR指標共同判斷。
read_view用於判斷當前記錄是否可見(判斷DATA_TRX_ID)。DATA_ROLL_PTR用於將當前記錄回滾到前一版本。
非主鍵查詢
select comment from test where comment > ‘ ‘;
針對測試2,二級索引,當前頁面的最大更新事務MAX_TRX_ID = 1816。如果MAX_TRX_ID < read_view.up_limit_id,當前頁面所有資料均可見,本頁面可以進行索引覆蓋性掃描。丟棄所有deleted bit = 1的記錄,返回deleted bit = 0 的記錄;此時返回 (ccc)。(row_select_for_mysql ->lock_sec_rec_cons_read_sees)
針對測試2,二級索引,如果當前頁面不能滿足MAX_TRX_ID < read_view.up_limit_id,說明當前頁面無法進行索引覆蓋性掃描,此時需要針對每一項,到聚簇索引中判斷可見性。回到測試2,二級索引中有兩項pk = 9 (一項deleted bit = 1,另一個為0),對應的聚簇索引中只有一項pk= 9。如何保證通過二級索引過來的同一記錄的多個版本,在聚簇索引中最多隻能被返回一次?如果當前事務id 1811可見。二級索引pk = 9的記錄(兩項),通過聚簇索引的undo,都定位到了同一記錄項。此時,InnoDB通過以下的一個表示式,來保證來自二級索引,指向同一聚簇索引記錄的多個版本項,有且最多僅有一個版本將會返回資料:
if (clust_rec
&& (old_vers || rec_get_deleted_flag(
rec,dict_table_is_comp(sec_index->table)))
&& !row_sel_sec_rec_is_for_clust_rec(rec, sec_index, clust_rec, clust_index))
滿足if判斷的所有聚簇索引記錄,都直接丟棄,以上判斷的邏輯如下:
需要回聚簇索引掃描,並且獲得記錄
聚簇索引記錄為回滾版本,或者二級索引中的記錄為刪除版本
聚簇索引項,與二級索引項,其鍵值並不相等
為什麼滿足if判斷,就可以直接丟棄資料?用白話來說,就是我們通過二級索引記錄,定位聚簇索引記錄,定位之後,還需要再次檢查聚簇索引記錄是否仍舊是我在二級索引中看到的記錄。如果不是,則直接丟棄;如果是,則返回。
根據此條件,結合查詢與測試2中的索引結構。可見版本為事務1811.二級索引中的兩項pk = 9都能通過聚簇索引回滾到1811版本。但是,二級索引記錄(ccc,9)與聚簇索引回滾後的版本(aaa,9)不一致,直接丟棄。只有二級索引記錄(aaa,9)保持一致,直接返回。
總結:
二級索引的多版本可見性判斷,需要通過聚簇索引完成。
二級索引頁面中儲存了MAX_TRX_ID,可以快速判斷當前頁面中,是否所有項均可見,可以實現二級索引頁面級別的索引覆蓋掃描。一般而言,此判斷是滿足條件的,保證了索引覆蓋掃描 (index only scan)的高效性。
二級索引中的項,需要與聚簇索引中的可見性進行比較,保證聚簇索引中的可見項,與二級索引中的項資料一致。
疑問
在http://blogs.InnoDB.com/wp/2011/04/mysql-5-6-multi-threaded-purge/中,作者提到,InnoDB的purge操作,是通過遍歷undo來實現對於標記位deleted項的回收的。如果二級索引本身標記deleted位不記錄undo,那麼這個回收操作如何完成?還是說purge是通過解析redo來完成回收的?(根據下面對於purge的流程分析,此問題已解決)
Purge流程
Purge功能:
InnoDB由於要支援多版本協議,因此無論是更新,刪除,都只是設定記錄上的deleted bit標記位,而不是真正的刪除記錄。後續這些記錄的真正刪除,是通過Purge後臺程序實現的。Purge程序定期掃描InnoDB的undo,按照先讀老undo,再讀新undo的順序,讀取每條undo record。對於每一條undo record,判斷其對應的記錄是否可以被purge(purge程序有自己的read view,等同於程序開始時最老的活動事務之前的view,保證purge的資料,一定是不可見資料,對任何人來說),如果可以purge,則構造完整記錄(row_purge_parse_undo_rec)。然後按照先purge二級索引,最後purge聚簇索引的順序,purge一個操作生成的舊版本完整記錄。
一個完整的purge函式呼叫流程如下:
row_purge_step->row_purge->trx_purge_fetch_next_rec->row_purge_parse_undo_rec
->row_purge_del_mark->row_purge_remove_sec_if_poss
->row_purge_remove_clust_if_poss
總結:
purge是通過遍歷undo實現的。
purge的粒度是一條記錄上的一個操作。如果一條記錄被update了3次,產生3個old版本,均可purge。那麼purge讀取undo,對於每一個操作,都會呼叫一次purge。一個purge刪除一個操作產生的old版本(按照操作從老到新的順序)。
purge按照先二級索引,最後聚簇索引的順序進行。
purge二級索引,通過構造出的索引項進行查詢定位。不能直接針對某個二級頁面進行,因為不知道記錄的存放page。
對於二級索引設定deleted bit為不需要記錄undo,因為purge是根據聚簇索引undo實現。因此二級索引deleted bit被設定為1的項,沒有記錄undo,仍舊可以被purge。
purge是一個耗時的操作。二級索引的purge,需要search_path定位資料,相當於每個二級索引,都做了一次index unique scan。
一次delete操作,IO翻番。第一次IO是將記錄的deleted bit設定為1;第二次的IO是將記錄刪除。
--此文章轉載自登博的部落格,由於連結已經找不到,這裡給大家分享。