
Kafka學習筆記(5)----Kafka的Consumer
1. Pull vs Push
Producer主動的通過push將訊息釋出到Broker上,Consumer通過Pull的的方式從Broker訊息訊息。
通過Push的方式由於是一有訊息就推到Broker,所以極大的保證了訊息實時性,但是在某些情況下,可能由於Consumer網路,或是其他原因倒是消費速度低,此時就可能會導致Consumer堆積大量的訊息,甚至在極端情況下會壓垮Consumer.
通過Pull拉取訊息保證了Consumer能夠按自己實際處理能力來拉取相應的訊息,並且Broker的實現也相對簡單,但是也會出現在訊息處理能力很低的情況下造成訊息的實時性過低。
kafka提供了High Level Consumer和High Level Consume兩種方式的API。
2. High Level Consumer
很多應用場景下,客戶程式只是希望從Kafka順序讀取並處理資料,而不太關心具體的offset。它同時也希望提供一些語義,例如同一條訊息只被某一個Consumer消費(單播)或被所有Consumer消費(廣播),Kafka High Level API提供了一個從Kafka消費資料的高層抽象,從而遮蔽掉其中的細節,並提供豐富的語義。
在Kafka中,High Level Consumer將從某個Partition讀取的最後一條訊息的offset存於Zookeeper中(從0.8.2開始同時支援將offset存於Zookeeper中和專用的Kafka Topic中)。這個offset基於客戶程式提供給Kafka的名字來儲存,這個名字被稱為Consumer Group,Consumer Group是整個Kafka叢集全域性唯一的,而非針對某個Topic的。每個High Level Consumer例項都屬於一Consumer Group,若不指定則屬於預設的Group。在訊息被消費之後,訊息並不會立即被刪除,只是相應的offset加一,若以可能Consumer中的offset將會跟訊息的資料一樣多,
在High Level Consumer下由於存在了關聯關係(Group ),所以訊息刪除也將不再是到一定時間或訊息條數達到某個值就刪除,而是通過壓縮的方式,保留最新的key的value的方式。具體示例如下:
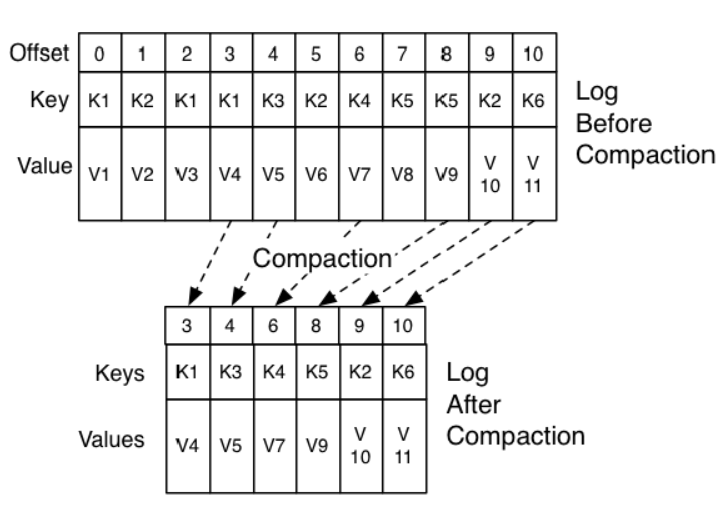
這樣就保證了訊息與offset之間仍然是正確的對應關係。
對於每條訊息,在同一個Consumer Gourp裡都只會被一個Consumer消費,不同的Cosumer Group可以消費同一條訊息。
如下:
Kafka的設計理念之一就是同時提供對離線批處理和線上流處理的支援。可以同時使用Hadoop系統進行離線批處理,Storm或它流處理系統進行流處理。也可使用Kafka的Mirror Maker將訊息從一個數據中心映象到另一個數據中心。
如圖:

Consumer的Rebalance(平衡策略)
High Level Consumer啟動時將其ID註冊到其Consumer Group下,在Zookeeper上的路徑為/consumers/[consumer group]/ids/[consumer id],在/consumers/[consumer group]/ids上註冊Watch,在/brokers/ids上註冊Watch,如果Consumer通過Topic Filter建立訊息流,則它會同時在/brokers/topics上也建立Watch,強制自己在其Consumer Group內啟動Rebalance流程
Rebalance演算法
1. 將目標Topic下的所有Partirtion排序,存於PT
2. 對某Consumer Group下所有Consumer排序,存於CG,第i個Consumer記為Ci
3. N=size(PT)/size(CG) ,向上取整
4. 解除Ci對原來分配的Partition的消費權(i從0開始)
5. 將第i∗N 到(i+1)∗N−1個Partition分配給Ci
Rebalance演算法也存在如下缺點:
1. Herd Effect: 任何Broker或者Consumer的增減都會觸發所有的Consumer的Rebalance
2. Split Brain: 每個Consumer分別單獨通過Zookeeper判斷哪些Broker和Consumer宕機,同時Consumer在同一時刻從Zookeeper“看”到的View可能不完全一樣,這是由Zookeeper的特性決定的。
3. 調整結果不可控所有Consumer分別進行Rebalance,彼此不知道對應的Rebalance是否成功
3. Low Level Consumer
使用Low Level Consumer (Simple Consumer)的主要原因是,使用者希望比Consumer Group更好的控制資料的消費,如:
1. 同一條訊息讀多次,方便Replay
2. 只消費某個Topic的部分Partition
3. 管理事務,從而確保每條訊息被處理一次(Exactly once)
與High Level Consumer相對,Low Level Consumer要求使用者做大量的額外工作
1. 在應用程式中跟蹤處理offset,並決定下一條消費哪條訊息
2. 獲知每個Partition的Leader
3. 處理Leader的變化
5. 處理多Consumer的協作