TensorFlow報錯Fetch argument None has invalid type class 'NoneType'
阿新 • • 發佈:2018-11-27
寫了一個TensorFlow卷積神經網路的訓練程式。
基於mnist資料集進行訓練和測試。
但是在程式執行的時候報出了下面的錯誤。
Traceback (most recent call last): File "nn_eg.py", line 104, in <module> train_loss, train_op = sess.run([loss, train_op], {input_x: batch[0], output_y: batch[1]}) File "/home/zhonghangalex/venv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 929, in run run_metadata_ptr) File "/home/zhonghangalex/venv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1137, in _run self._graph, fetches, feed_dict_tensor, feed_handles=feed_handles) File "/home/zhonghangalex/venv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 471, in __init__ self._fetch_mapper = _FetchMapper.for_fetch(fetches) File "/home/zhonghangalex/venv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 261, in for_fetch return _ListFetchMapper(fetch) File "/home/zhonghangalex/venv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 370, in __init__ self._mappers = [_FetchMapper.for_fetch(fetch) for fetch in fetches] File "/home/zhonghangalex/venv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 370, in <listcomp> self._mappers = [_FetchMapper.for_fetch(fetch) for fetch in fetches] File "/home/zhonghangalex/venv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 258, in for_fetch type(fetch))) TypeError: Fetch argument None has invalid type <class 'NoneType'>
這裡我們看到錯誤指向的是程式碼的104行,我將這部分的程式碼貼出來:
# 訓練神經網路 for i in range(20000): batch = mnist.train.next_batch(50) #從Train(訓練)資料集裡取下一個50樣本 train_loss, train_op = sess.run([loss, train_op], {input_x: batch[0], output_y: batch[1]}) if i % 100 == 0: test_accuracy = sess.run(accuracy, {input_x: test_x, output_y: test_y}) print("Step=%d, Train loss=%.4f, [Test accuracy=%.2f]" % (i, train_loss, test_accuracy))
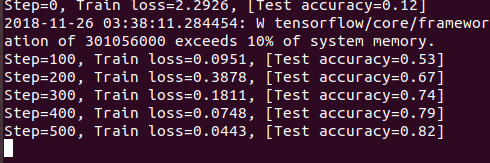
這是對神經網路訓練的過程,指定訓練20000步,有一個奇怪的現象就是,迴圈的第一步進行得很順暢,可是從第二步開始就報了這個錯誤:

這就說明了應該是變量出現了問題。
查閱資料後發現是因為:
train_op變數重新分配給結果的第二個元素sess.run()(恰好是None)。因此,在第二次迭代中,train_op是None,這導致錯誤。 解決的方法很簡單,就是把兩個變數的第二個變數改為“_”:
# 訓練神經網路 for i in range(20000): batch = mnist.train.next_batch(50) #從Train(訓練)資料集裡取下一個50樣本 train_loss, _ = sess.run([loss, train_op], {input_x: batch[0], output_y: batch[1]}) if i % 100 == 0: test_accuracy = sess.run(accuracy, {input_x: test_x, output_y: test_y}) print("Step=%d, Train loss=%.4f, [Test accuracy=%.2f]" % (i, train_loss, test_accuracy))
這樣便成功開始了訓練: