
Java virtual machine
工作中不直接和Java 虛擬機器打交道,沒有進行過調優等工作,所以對虛擬機器體會不深,這裡簡單總結下Java虛擬機器的基礎知識,對更好的理解Java語言有幫助。
章節如下:
- 資料型別
- 執行時資料區
- 垃圾收集機制和記憶體分配策略
- Class 檔案的結構
- 虛擬機器的類載入機制
1.資料型別
資料型別 ├── 原始型別 │ ├── boolean型別 │ ├── returnAddress型別 │ └── 數字型別(Numberic type) │ ├── 整數型別 │ │ ├── byte │ │ ├── char(0-63335(2^16 -1)) │ │ ├── int │ │ └── short │ └── 浮點型別 │ ├── float │ └── double └── 引用型別 ├── 類 型別 ├── 陣列型別 └── 介面型別
returnAddress用於java 虛擬機器的jsr, ret, jsr_w指令; 這種型別的值指向的是java虛擬機器指令的操作碼。
和數字型別不同,returnAddress在java語言中沒有對應的型別,也不能被執行的程式修改。
儘管Java虛擬機器定義了boolean型別,但是對這種型別的支援並不多,並沒有專門用於操作boolean型別的指令。Java語言中對boolean型別值的操作,在編譯完成後會使用Java虛擬機器的int型別。Java 虛擬機器也不直接支援boolean型別的陣列,"newarray"指令可以建立boolean 型別陣列,boolean型別陣列的訪問和修改都是使用的byte陣列的指令。Oracle的Java虛擬機器實現是將Java中的boolean陣列編碼為Java虛擬機器的byte 陣列,每個成員佔用8個bit。
物件可以分為兩類: 1.動態分配的類例項。2.陣列。
2.執行時資料區

一部分執行時資料區是在Java虛擬機器啟動是建立的,並且只有當Java虛擬機器退出是銷燬。一部分是執行緒啟動時建立,線上程退出時銷燬。
程式計數器:
程式計數器是一塊比較小的記憶體空間。
因為Java虛擬機器的多執行緒是通過執行緒輪流切換並分配處理器時間的方式實現的,所以每個執行緒都要有自己的程式計數器,來記錄程式執行的位置,以便執行緒切換後執行緒可以恢復到正確的執行位置。
如果執行緒當前執行的不是native方法,那麼程式計數器記錄的是Java虛擬機器的指令地址,如果是native方法,那麼程式計數器的內容是未知的;另外,程式計數器也可以容納returnAddress或者指定平臺的native指標。
Java虛擬機器棧:
Java虛擬機器棧是執行緒私有的,每個執行緒在被建立時,都會有對應的Java虛擬機器棧被建立; 當執行緒退出時,相應的Java虛擬機器棧也會被銷燬。Java虛擬機器棧描述的是Java方法執行的記憶體模型,每個方法在執行時都會建立一個棧幀,用於儲存區域性變量表,運算元棧以及方法出口等資訊。所以一個方法呼叫的過程對應了一個棧幀在Java虛擬機器中入棧出棧的過程。
Java虛擬機器棧可以是固定大小的也可以是可擴充套件的,縮小的; 如果是固定大小的棧,那麼當請求的棧深度大於Java虛擬機器所允許的深度時,那麼將會丟擲StackOverflowError;如果是可擴充套件的,那麼如果擴充套件時不能申請到足夠的記憶體, 那麼將丟擲OutOfMemoryError。
Java虛擬機器棧的記憶體空間可以不是連續的。
堆(Heap):
堆是空間最大的一塊記憶體空間了,在Java虛擬機器啟動時被建立; 是所有執行緒共享的執行時資料區。虛擬機器規範裡說所有的類物件和陣列都會在這裡建立,但是由於JIT編譯器的發展,逃逸分析技術的發展以及棧上分配、標量替換優化技術的出現,所有物件都在堆上分配已經變的沒那麼絕對了。
堆中的空間由GC來回收。
堆的記憶體空間可以不是連續的。
堆的大小可以固定,也可以擴充套件,縮小。如果堆無法成功擴充套件,那麼會丟擲OutOfMemoryError。
方法區:
方法區也是Java虛擬機器內所有執行緒共享的,在Java虛擬機器啟動時被建立。用於儲存已載入的類資訊,比如執行時常量池,資料域和方法資料,以及方法和建構函式的code,包括那些用於類和介面初始化,例項初始化的特殊方法。
方法區是heap的一個邏輯分割槽,大小可以是固定,也可以擴充套件,縮小;可以不實現垃圾收集。
方法區記憶體空間可以不是連續的。
如果方法區不能請求到足夠的記憶體,那麼會丟擲OutOfMemoryError。
執行時常量池:
執行時常量池在方法區中,當Java虛擬機器載入類或者介面的時候會被建立。
每個類或者介面編譯後生成的class檔案中都有一個"constatn_pool"表,執行時常量池就是這個表格的執行時代表。執行時常量池中包含了各種常量,包括數字型的字面值和符號引用,這些內容將在類或者介面載入後進入方法區的執行時常量池中存放。
執行時常量池不同於class檔案中的"constant_pool"表,"constant_pool"表是在編譯時就確定了的,而執行時常量池是動態的。Java語言並不要求常量一定是隻有編譯期才能產生,即並非預置到"constant_pool"中的常量才能進入執行時常量池,執行時產生的常量依然可以放入執行時常量池中,常見的是String的intern()方法產生的常量。
當常量池無法申請到記憶體是會丟擲OutOfMemoryError。
本地方法棧:
本地方法棧和Java虛擬機器棧的作用類似,Java虛擬機器棧為執行Java方法服務,而本地方法棧為執行native方法服務。
本地方法棧也是執行緒私有的。另外,本地方法棧同樣會有StackOverflowError和OutOfMemoryError。
棧幀:
棧幀在方法呼叫時建立,當方法呼叫結束後銷燬。棧幀儲存了局部變量表,運算元棧,方法出口以及當前方法所屬類的執行常量池的引用(為了動態連結)。
棧幀的空間是在Java虛擬機器棧上分配的,所以是執行緒私有的,不能被其他執行緒共享。
任何時間點只有一個棧幀是active狀態,即當前棧幀,與之相關的是當前方法,當前類。
區域性變量表的大小是在編譯時就確定了的,具體內容由方法的code決定。單個區域性變數可以儲存boolean, byte, char, short, int, float, reference和returnAddress型別。long和double型別
會佔用兩個連續的區域性變數空間。
運算元棧的大小也是編譯時確定的,具體內容由方法的code決定。
動態連結:將class檔案中的符號轉化為具體的方法引用,對於未知的符號會載入相應的類; 並將變數訪問轉化為執行時變數儲存結構的合適偏移量。這種延遲繫結可以減少類之間的關聯性,一個類改變不會導致其他類變化。
區域性變量表
區域性變量表(Local Variable Table)是一組變數值儲存空間,用於存放方法引數和方法內部定義的區域性變數。在Java程式被編譯成Class檔案時,就在方法的Code屬性的max_locals資料項中確定了該方法所需要分配的區域性變量表的最大容量。
物件的儲存佈局和訪問定位:
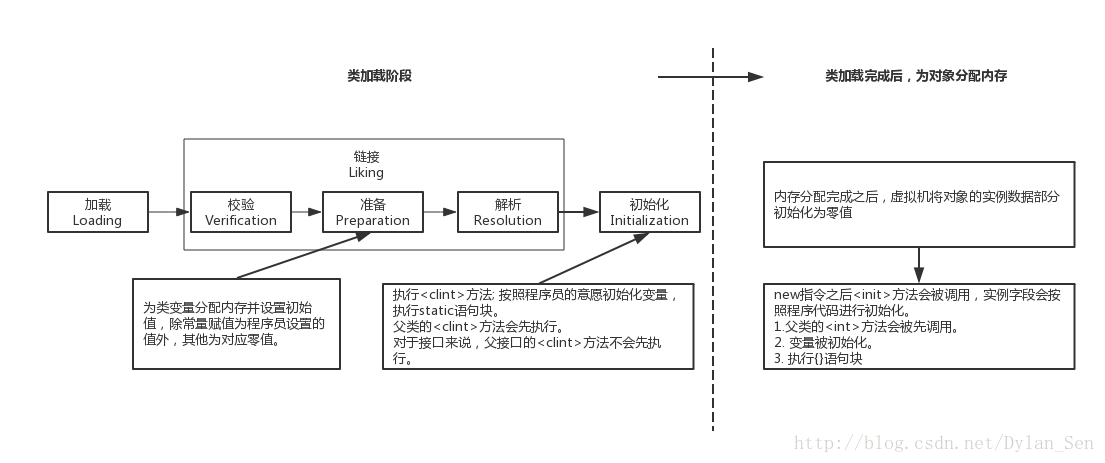
當虛擬機器遇到一條new指令時,首先會去檢查指令引數是否能在常量池中定位到一個類的符號引用,並檢查這個類是否已經載入,解析和初始化過。如果沒有,便去執行類的載入過程。載入完成後,虛擬機器會為物件分配記憶體,一般一個物件在記憶體中的佈局分為三部分:物件頭,例項資料和對齊填充。物件頭用於儲存物件自身的執行時資料; 例項資料是物件真正儲存的有效資訊,也是程式程式碼中所定義的各種型別的欄位內容,包括從父類繼承的以及本身定義的; 對齊填充沒有有用資訊,只是為了便於記憶體管理。記憶體分配完成之後,虛擬機器將物件的例項資料部分初始化為零值,所以物件的例項欄位不賦初始值也可以直接使用。至此,虛擬機器層面的物件已經建立完成,但是Java層面的物件還沒有建立完成,new指令之後<init>方法會被呼叫,例項欄位會按照程式程式碼進行初始化。
Java程式是通過棧上的reference引用來操作堆裡的物件的,使用reference定位堆裡物件的方法一般有兩種:控制代碼和直接訪問。
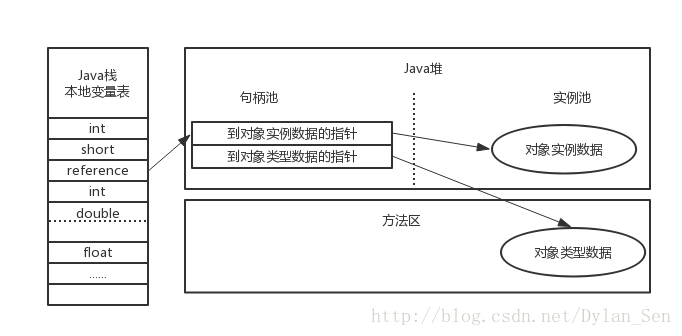
下圖展現的是用控制代碼定位物件的方式:
首先Java堆中劃分出一部分記憶體作為控制代碼池,reference中儲存的是指向物件控制代碼的地址。控制代碼中包含兩部分,一部分是到物件例項資料的指標,另外一部分是到物件型別資料的指標。這種方式的好處是reference中可以保持比較穩定的控制代碼地址,當物件被移動時,不需要改變reference的值。
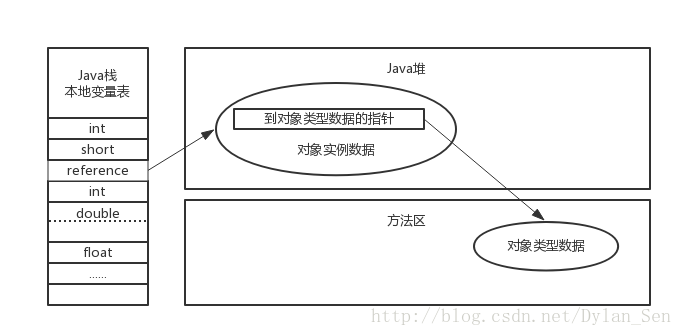
下圖展現的是直接訪問物件的方式:
reference中儲存的是物件在堆中的地址;這種方式因為節省了一次指標定位,所以會更快速 。
3.垃圾收集機制和記憶體分配策略
記憶體管理一直都很重要,java的垃圾收集機制為開發提供了方便,至少Java開發人員不用像C++,C開發人員那樣為記憶體洩漏提心吊膽。
回收記憶體可以分成三個子問題,第一是回收那些物件-判斷物件的是否依然存活; 第二是什麼時候回收; 第三是如何回收物件。
第一,回收那些物件-判斷物件的是否依然存活?常見的思路有:
- 引用計數
- 可達性分析
第二,什麼時候回收?
- 安全點,當程式執行到安全點時停下進行GC。
- 安全區域,當程式執行到安全區域是進行GC。
第三,如何回收物件?
考慮到效率以及記憶體使用情況,常見的思路有:
- 標記-清楚演算法:首先標記要回收的物件,其次回收物件; 這個演算法是最基礎的演算法,效率不高,記憶體碎片多,使用率也低。
- 複製演算法:這種演算法的思路就是將記憶體分塊,只使用其中一部分; 回收時,將存活物件移動到沒有使用的記憶體中。
- 標記-整理演算法:這種演算法的思路是將存活物件移動到記憶體的一端,然後清理到邊界外的記憶體。
- 分代收集演算法:根據物件存活週期的不同,將記憶體劃分為幾塊,一般是分為新生代和老年代。然後本別使用不同的演算法進行收集。
4.class 檔案的結構
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
magic魔法數用於確認檔案的結構,取值0xCAFEBABE。
minor_version和major_version分別表示檔案支援的最小版本和最打版本(含)。
constant_pool_count表示constant_pool中的數量。
constant_pool表中的每一項記錄都是代表string常量, 類/介面名字等常量的結構體。
有效索引是1-constant_pool_count -1。
access_flag用於表明類或者介面的訪問許可權和屬性。access_flag的值是多個flag按位與操作得到的; 常用的flag有ACC_PUBLIC(0x0001),ACC_FINAL(0x0002)等。
this_class的值必須是constant_pool中的一個有效索引,對應的記錄是一個可以代表當前class檔案所定義類/介面的CONSTANT_Class_info結構體。
super_class
對一個Class(類)來說,super_class的值必須是0或者constant_pool中的有效值,constant_pool中對應的記錄也必須是一個CONSTANT_Class_info結構體。
對一個Interface(介面)來說,super_class的值必須是constant_pool中的有效值,constant_pool中對應的記錄也必須是一個代表Class物件的CONSTANT_Class_info結構體。
interfaces_count的值表示當前類/介面的父介面數量
interfaces[interfaces_count] interfaces表中的每一個值都必須是constant_pool中的一個有效索引。
fields_count 表示當前Class/Interface內的變數的數量,包括所有的類變數和例項變數;但是不包括從父類/介面中繼承來的變數。
fields[fields_count] 中的每一項都是field_info結構,field_info結構如下:
field_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
name_index是值必須是constant_pool中的一個有效索引。
methods_count表示methods表中的方法數量。
methods[methods_count] 方法表中的每一項記錄都是method_info結構體;該表包含了當前類/介面宣告的所有方法,包括例項方法,類方法,例項初始化方法和類/介面初始化方法,但是不包含從父類/父介面中繼承的方法。
method_info結構體如下:
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
name_index是值也必須是constant_pool中的一個有效索引。
attributes_count表示屬性表中的數量。
attributes[attributes_count] 屬性表中的每項記錄都是attribute_info結構體。
attributes在ClassFile,fields_info,method_info和Code_attribute都有有使用,不過統一使用了下面的結構體:
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}
attribute_name_index必須是constant_pool常量池中的有效索引; constant_pool常量池中的記錄是CONSTANT_Utf8_info結構體,這個結構體是用來表示String常量的:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
5.虛擬機器的類載入機制
虛擬機器將描述類/介面的資料從class檔案載入到記憶體,並經過校驗,準備,解析和初始化,最終形成可以被虛擬機器直接呼叫的Java型別,這整個過程就是虛擬機器的類載入機制。
和編譯期就需要連結的語言不同(比如C語言),Java語言的載入,連結和初始化發生在執行期,雖然增加了一些效能開銷,但是增加了靈活性和可擴充套件性。
虛擬機器載入機制的流程可以用下圖表示:
載入,校驗,準備,初始化和解除安裝是按照順序執行的(各階段可能有交叉), 但是解析階段可能發生在初始化之後。
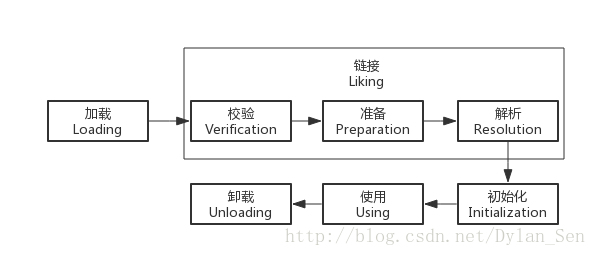
虛擬機器沒有規定什麼時候進行類/介面載入,但是規定了下面幾種情況要執行類/介面的初始化:
類或者介面 C 什麼情況下會被初始化?
- new, getstatic, putstatic和invokestatic指令被執行的時候; 即new一個物件的時候或者呼叫一個類或者介面的靜態方法或者靜態域時。
- 使用java.lang.reflect包對類進行反射呼叫時。
- 如果C是一個類,當初始化它的一個子類時,它也會被初始化。
- 如果C是一個介面,並且聲明瞭一個非靜態,非抽象的方法,那麼當初始化一個直接或間接實現了C的類時,C也會被初始化。
- C本來就被設計做為Java虛擬機器啟動時的初始類/介面。
- 第一次呼叫java.lang.invoke.MethodHandle例項C,而C是對方法控制代碼REF_getStatic,REF_putStatic,REF_invokeStatic或REF_newInvokeSpecial進行控制代碼解析的結果。
在初始化之前一個類/介面必須被載入,驗證,準備,解析(可選)。
Java虛擬機器在初始化的過程中要解決多執行緒,以及迴圈初始化的問題。每個類或者介面都有一個初始化鎖,在初始化的時候要拿到這個鎖。
對於靜態域(欄位),只有定義這個域的類/接口才會被初始化,即在子類中呼叫父類/介面中的靜態欄位時,只會觸發父類/介面的初始化,而不會觸發子類的初始化。
常量在編譯階段會進入引用類的常量池中,所以引用常量不會觸發定義常量類的初始化。
載入要完成以下工作:
- 根據一個類/介面的名字獲取定義此類的二進位制位元組流。
- 將二進位制位元組流代表的靜態儲存結構轉化為方法區的執行時資料結構。
- 在記憶體中生成一個代表這個類/介面的java.lang.Class物件,作為方法區這個類的各種資料的訪問入口(這個物件可能不在堆上; 使用反射時獲取的是這個Class物件?)。
對於非陣列類/介面,是有類載入器完成載入(系統提供的啟動類載入器或者使用者自定義的類載入器); 陣列類是由虛擬機器直接建立的。如果比較兩個非陣列類是否"相等", 只有在同一個類載入器的條件下才有意義,即使載入自同一class檔案的類也會由於類載入器的不同而不相等。
驗證階段用於檢查代表類/介面的二進位制流格式是否正確以及符合要求,並且不會危害虛擬機器的安全。
驗證階段大致完成下面4個階段的工作:
檔案格式驗證:格式是否符合規範; 比如魔法數是否正確,版本號是否在有效範圍內等內容。
元資料驗證:進行語義分析,保證內容符合語言要求。
位元組碼驗證:最複雜的一個階段; 確定程式語義是否合法,是否符合邏輯。
符合引用驗證:這個階段發生在解析階段,即將符合引用轉為直接引用時,確保解析階段能順利進行。
準備階段會正式為類變數(被static修飾的變數)分配記憶體並設定初始值這些變數所使用的記憶體都在方法區內分配; 零值通常為資料零值,而非程式設計師設定的值, 但是如果是常量則會被設定為設定的值,而非零值。
[例如]
public static int value = 123;
在準備階段會被賦值為0,而非123。
public static final int value =123;
但是如果被final修飾那麼value會被初始化為123, 而非0。
解析階段是虛擬機器將常量池內的符合引用轉化為直接引用的過程。
符號引用以一組符號來描述所引用的目標,符號可以是任何形式的字面量,只要可以無歧義的定位到目標即可。符號引用和虛擬機器記憶體佈局無關,也和相關類是否載入無關。所以虛擬機器記憶體實現可能不盡相同,但是各種虛擬機器使用的符號引用形式都是一樣的, 因為虛擬機器規範明確定義了符號引用的字面量形式。
下面是虛擬機器規定的常量池中資料的規範格式:
cp_info {
u1 tag;
u1 info[];
}
tag用於表明當前常量的型別;info的內容隨tag變化。
除了規範格式,虛擬機器規範還為各種型別都定義了格式,比如CONSTANT_Class_info,CONSTANT_MethodType_info和CONSTANT_Utf8_info等。
直接引用可以只直接定位目標的指標,相對偏移量或者是可以間接定位目標的控制代碼。直接引用和虛擬機器的具體記憶體實現有關,同一個符合引用在不同的虛擬機器實現上一般是不同的。
初始化階段:
初始化階段開始執行java程式碼(或者位元組碼),按照程式設計師的意願初始化類變數和其他資源; 或者說初始化階段是執行 <clint>的過程。
<clint>是編譯器收集類中所有類變數的賦值動作和靜態語句塊(static {})中的語句合併產生的; 編譯器收集的順序是由語句在原始檔中出現的順序決定的,靜態語句快只能訪問定義在它之前的變數,對於定義在它之後的變數靜態語句塊可以賦值,但是不能訪問。如果一個類中沒有靜態語句塊,也沒有類變數的賦值操作,那麼<clint>方法就不會生成。虛擬機器會在呼叫子類的<clint>方法前呼叫父類的<clint>方法。介面雖然不能使用靜態語句塊,但是可以有變數賦值操作,所以同樣會有<clint>方法,不過執行介面中的<clint>方法時不需要先執行父介面的<clint>方法,只有當父介面中定義的變數被使用時,父介面的<clint>方法才會被呼叫。對於實現了介面的類來說,初始化時,介面的<clint>方法也不會被先執行。虛擬機器會對<clint>方法加鎖,以應對多執行緒同時初始化一個類,所以<clint>方法中耗時問題可能會導致執行緒阻塞。
例項構造器<int>和類構造器<clint>都是在位元組碼生成的時候由編譯器生成的(<int>並不是指預設建構函式,兩者不是一回事)。這兩個構造器都是在程式碼收斂的過程中產生的,編譯器會把語句塊(對於例項構造器是"{}", 對於類構造器是"static {}")、變數初始化(例項變數和類變數)、呼叫父類的例項構造器(類構造器不需要呼叫父類的<clint>方法,虛擬機器會會保證父類構造器的執行,但是在<clint>方法中經常生成呼叫java.lang.Object的<int>方法的程式碼)等操作收斂到<int>和<clint>方法之中。並且保證一定是按先執行父類的例項構造器,然後初始化變數,最後執行語句塊的順序進行。
虛擬機器規範的"2.9 Special Methods"章節對<int>和<clint>方法也有描述。
下圖展現的是我們new一個物件時,虛擬機器所執行的初始化操作:
參考資料:
- The Java ® Virtual Machine Specification Java SE 9 Edition
- 《深入理解Java虛擬機器:JVM高階特性和最佳實踐》