機器學習之KNN的總結
阿新 • • 發佈:2018-11-28
機器學習之KNN的總結
本片文章主要寫了針對一個csv資料,目標是對其資料進行分類,怎樣用knn實現
在此問題中將該問題分為三個步驟:
- 資料處理:對csv資料進行處理做出適合knn的資料集,包括劃分測試集及訓練集
- 資料擬合:對資料集資料進行擬合
- 資料預測及評價指標:對所訓練得到的結果進行預測以及評價
-
資料處理
-
本例項中的資料集如下圖所示:
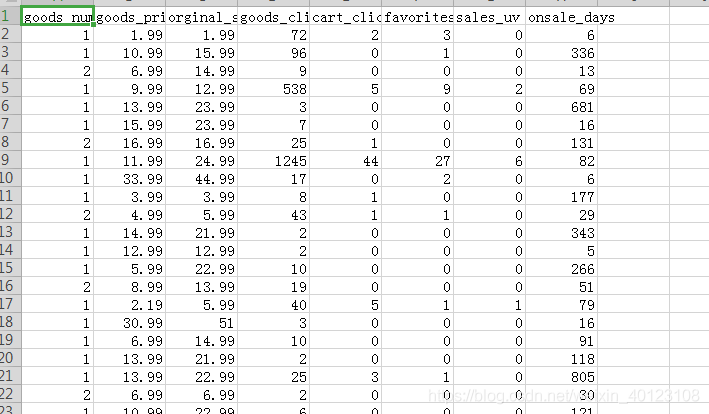
第一列為資料集的標籤,第一行為資料集的title,首先要做的處理是將資料集的資料以及標籤提取出來。即特徵與標籤類別# -*- coding: utf-8 -*- """ Created on Tue Nov 27 17:47:44 2018 @author: Administrator """ import csv from sklearn import neighbors knn = neighbors.KNeighborsClassifier()#(n_neighbors=10) from numpy import genfromtxt a = open('list.csv', 'r+') reader = csv.reader(a)#按行讀取內容 headers = next(reader)#打印出為title那行 print(headers)

該title第一列為數字序列,後七列為特徵名稱,其次是提取標籤以及資料
dataPath = r"list.csv" featureList = genfromtxt(dataPath, skip_header=1,delimiter=',',usecols=(1,2,3,4,5,6,7)) #轉化為txt,[genfromtxt用法](https://blog.csdn.net/weixin_40123108/article/details/84531460)得到後7列資料 labelList = genfromtxt(dataPath, skip_header=1,delimiter=',',usecols=(0))#得到標籤 x= featureList[:] print(len(x)) #print (x) #print ("labelList") y = labelList[:] #print (y)
劃分資料集及訓練集
from sklearn.model_selection import train_test_split#分割資料集
X_train, X_test, y_train, y_test = train_test_split(
x, y, test_size=0.25)
print(X_train.shape)
print(X_test.shape)

**
- 資料擬合
**
knn = neighbors.KNeighborsClassifier()#(n_neighbors=10)knn引數用法
knn.fit(X_train,y_train)
**
- 資料預測及評價指標
**
y_predict = knn.predict(X_test)
#呼叫該物件的測試方法,主要接收一個引數:測試資料集
probility=knn.predict_proba(X_test)
#計算各測試樣本基於概率的預測
score=knn.score(X_test,y_test,sample_weight=None)
#呼叫該物件的打分方法,計算出準確率
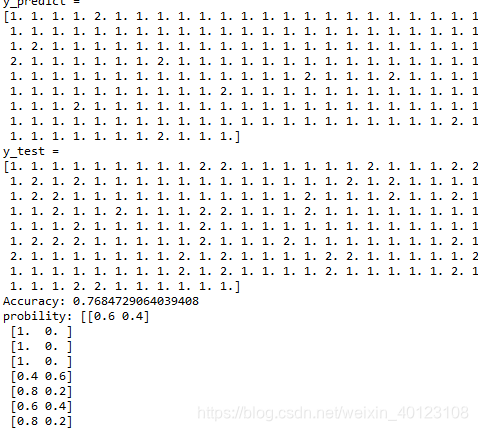
print('y_predict = ')
print(y_predict)
#輸出測試的結果
print('y_test = ')
print(y_test)
#輸出原始測試資料集的正確標籤,以方便對比
print ('Accuracy:',score )
#輸出準確率計算結果
print ('probility:',probility)