
SQL 使用總結一( 規範、基礎)
目錄
寫在之前
資料庫的使用有些年頭,工作也換了幾個,但是感覺資料庫的使用情況都是大差不差的(工作過的幾個公司)。這次剛剛換了一個新的工作,進來後發現數據庫的使用情況也沒比之前的有多大的進步。然而因為公司性質的不同,工作人員等的不同,相對來說,儲存過程用的多了點;其他,總體上和之前上班公司的使用情況差不多。而找到這份工作前,也經歷了一些面試,各種資料庫的理論知識,高階應用等,很多公司都會問。
坐下來仔細想想,似乎只是在談理論的時候這些知識才是有用的,但事實工作中又都沒怎麼去用,高階的不提,基礎的如外來鍵約束,唯一性約束等好多都是沒有用過的。(當然這也和實際工作中的很多因素有關)但是最近看report service應用的時候,下載了微軟官網給例項資料庫,裡面的表,從命名規範,到外來鍵,約束,索引等等,使用的很好,至少在之前的工作中我不從遇到。沒有在BAT等大公司蹲過,所以說我坐井觀天也罷,沒啥好說的;但是我想,對於大部分從事軟體行業的人來說,又有多少是在BAT裡面的呢?
所以總是感覺應該寫點啥,但是這絕對不是教程,姑且算是我的一個總結吧~~(希望以後儘量能用到實際專案中,而不是隻是在理論上遐想)
命名規範
命名規範是在資料庫規格化過程中最重要的考慮因素之一。名稱是我們應用資料庫物件的方式。表的名稱應該能夠描述所儲存資訊的型別,以便我們找到需要的資料。對於沒有參加資料庫設計而需要查詢資料庫的使用者來說,具有描述性的名稱更為重要。所有在為物件選擇名稱時,特別是表和列的名稱,應該讓名稱反應出所儲存的資料。比如說,儲存僱員資訊的表可以命名為EMPLOYEE_TBL。列的名稱也是如此,比如儲存僱員電話號碼的列,顯然名稱為PHONE_NUMBER是比較合適的。
應該在公司範圍內統一命名規範,不僅是資料庫裡的表的命名,而是使用者、檔案和其他相關物件的命名都應該遵守。命名規範還讓我們更容易判斷表的用途和資料庫系統裡面檔案的位置,從而有助於資料庫的管理。設計和堅持命名規範是公司開發成功資料庫實現的第一步。
規格化形式
1、第一規格形式(第一正規化)
給資料庫中的每一個表或者大多數表都設定主鍵。第一正規化(1NF)是指資料庫表的每一列都是不可分割的基本資料項,同一列中不能有多個值,即實體中的某個屬性不能有多個值或者不能有重複的屬性。在第一正規化(1NF)中表的每一行只包含一個例項的資訊。
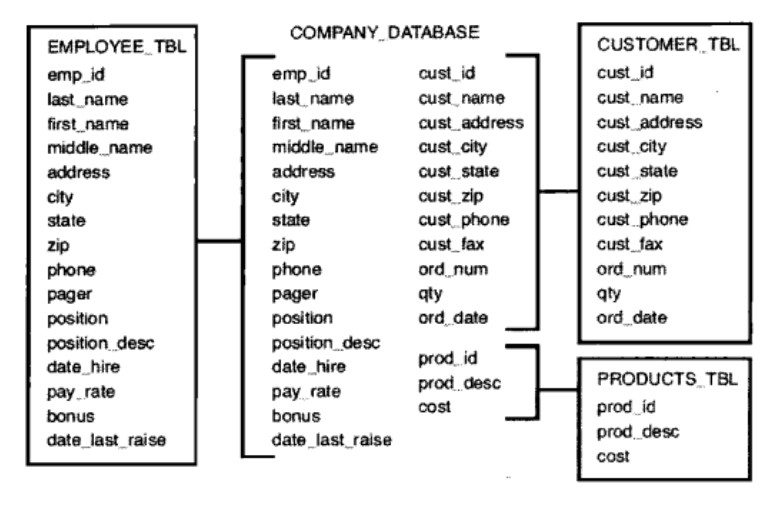
2、第二規格形式(第二正規化)
提取對主鍵僅有部分依賴的資料,把它們儲存到另一個表裡。
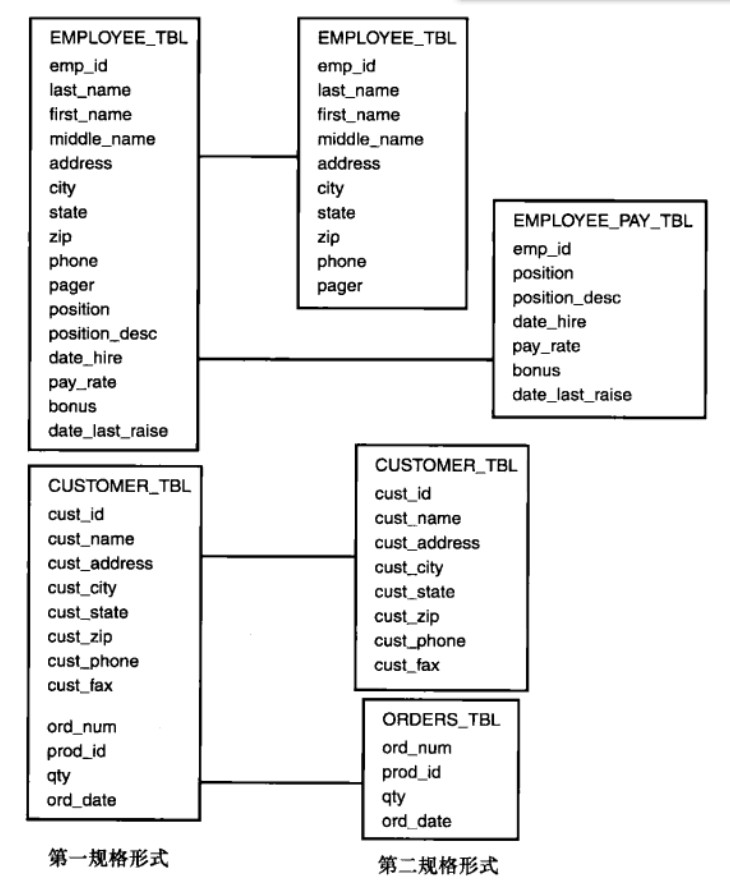
從圖中可以看出,第二正規化(2NF)是在第一正規化(1NF)的基礎上,把兩個表進一步劃分為更明確的單元。
3、第三規格化形式(第三正規化)
刪除表裡不依賴於主鍵的資料。滿足第三正規化(3NF)必須先滿足第二正規化(2NF)。簡而言之,第三正規化(3NF)要求一個數據庫表中不包含已在其它表中已包含的非主關鍵字資訊。
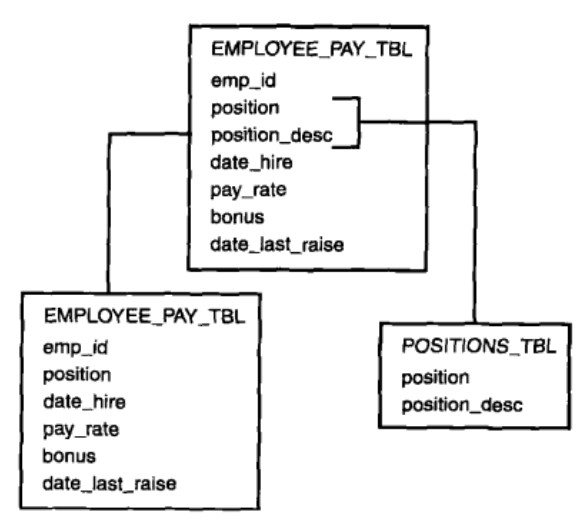
4、規格化的優點和缺點
規格化為資料庫帶來了很多好處,主要包含了如下幾點:
- 更好的資料庫整體組織性
- 減少冗餘資料
- 資料庫內部的資料一致性
- 更靈活的資料庫設計
- 更好的處理資料庫安全
- 加強引用整體性的概念
規劃雖然帶來了好處,但是它有個不可迴避的缺點:降低資料庫效能。效能的降低程度取決於查詢或事務被提交給資料庫的時機,其中涉及多個因素,如CPU使用率,記憶體使用率和輸入/輸出。
5、去規格化資料庫
去規格化是修改規格化資料庫的表的結構,在可控制的資料冗餘範圍內提高資料庫效能。嘗試提高資料庫效能是進行去規格化資料庫的唯一原因。去規格化的資料庫與沒有進行規格化的資料庫不一樣,去規格化是在資料庫規格化基礎上進行一些調整,因為規格化的資料庫需要頻繁的進行表的結合而降低了效能。去規格化會把一些獨立的表合成在一起,或是建立重複的資料,從而減少在資料檢索時需要結合的表的數量,進而減少所需的I/O和CPU的時間。這在較大的資料倉庫程式中會有明顯好處,其中的計算可能會涉及表裡數以百萬行的資料。
去規格化也是有代價的。它增加了資料冗餘,雖然提高了效能,但是需要付出更多的精力來處理相關的資料。程式程式碼會更復雜,因為資料被分散到了多個表,而且可能更難於定位。另外,引用完整性更加瑣碎,因為相關資料存在於多個表裡。規格化和去規格化都有好處,但是都需要我們對實際的資料和公司的詳細業務需求有全面的瞭解。在確定要著手進行去規格化時,一定要仔細記錄所採取的過程,以便於更好的處理像資料冗餘這樣的問題,維護系統內部的資料庫完整性。
從已有表建立新表
語法格式如下
select [*|column1,column2...]
into new_table_name
from table_name
[where]例如,下面是一個已經存在的表

執行如下語句
select *
into table_new
from table_test
where Id = 1可以看到如下內容

這表示已經從現有的表建立了一個新表,並且還把相應的資料新增到了新表中。
這裡補充另一種情況,即對現有表插入資料,相同的是它們都有into關鍵字,但是這個是牽扯到是子查詢的概念,子查詢可以和select,insert ,update,delete等一起使用,甚至還有巢狀的子查詢,但是這裡不過多說了,有興趣的自行度娘瞭解。這裡要是的和insert一起使用而實現的對現有表進行資料插入。
程式碼為
insert into table_new
select Id, TestNaem,ColName1,ColName3
from Table_Test
where Id in(2,3)結果如下

完整性約束
完整性約束用於確定關係型資料庫裡資料的準確性和一致性。在關係型資料庫裡,資料完整性是通過引用完整性的概念實現的,而在引用完整性裡包含了很多型別。
1、主鍵約束
主鍵是表裡一個或多個用於實現記錄唯一性的欄位。雖然主鍵通常是有一個欄位構成的,但是也可以有多個欄位組成。
隱式實現
create table Employee_TBL
(
emp_id varchar(50) not null primary key,
....
)
顯示實現
create table Employee_TBL
(
emp_id varchar(50) not null,
emp_name nvarchar(50) not null ,
primary key(emp_id)
)
包含了多個欄位的主鍵定義有如下兩種
create table Product_TST
(
prod_id varchar(20) not null,
vend_id varchar(20) not null,
product varchar(20) not null,
cost decimal(18,2) not null,
primary key (prod_id,vend_id)
)
alter table Product_TST
add constraint products_pk primary key (prod_id,vend_id)
2、唯一性約束
唯一性約束要求表裡某個欄位的值在每條記錄裡都是唯一的,這一點和主鍵類似。即使我們對一個欄位設定了主鍵約束,也可對另一個欄位設定唯一性約束,儘管它不會當作主鍵使用。
create table Employee_TBL
(
emp_id varchar(50) not null primary key,
emp_name nvarchar(100) not null,
emp_phone varchar(11) unique,
....
)
3、外來鍵約束
外來鍵是子表裡的一個欄位,引用父表裡的主鍵。外來鍵約束是確保表與表之間引用完整性的主要機制。一個被定義為外來鍵的欄位用於引用另一個表裡的主鍵。
create table Employee_Pay_tst
(
emp_id varchar(50) not null primary key,
position varchar(15) not null,
date_hire date null,
pay_rate decimal(12,2) not null,
date_last_raise date null,
constraint emp_id_fk foreign key (emp_id) references Employee_TBL (emp_id)
)
另外也可以使用alter table 新增外來鍵
alter table Employee_Pay_tst add
constraint emp_id_fk foreign key (emp_id) references Employee_TBL (emp_id)注:1、外來鍵約束中兩個關聯的欄位的資料型別和長度必須嚴格一致;2、兩個表必須都有主鍵
4、NOT NULL約束
前面的範例中,每個欄位的資料型別之後都使用了關鍵字NULL或NOT NULL。NOT NULL也是一個可以用於欄位的約束,它不允許欄位包含NULL值;換句話說,定義了NOT NULL的欄位在每條記錄中都必須是有值的。在沒有指定NOT NULL時,欄位預設是NULL,也就是可以是NULL值。
5、檢查約束
檢查約束用於檢查輸入到特定欄位的資料的有效性,可以提供後端的資料庫編輯,雖然編輯通常是在前端程式裡完成的。一般情況下,編輯功能限制了能夠輸入到欄位或物件的值,無論這個功能是在資料庫還是前端程式裡實現。檢查約束為資料提供了另一層保護。
create table Employee_TBL
(
emp_id varchar(50) not null primary key,
emp_name nvarchar(100) not null,
emp_phone varchar(11) unique,
emp_age int,
constraint chk_emp_age check(emp_age>20 and emp_age<50)
)
6、去除約束
利用alter table命令的drop constraint選項可以去除已經定義的約束。
alter table Employee_TBL drop constraint chk_emp_age
GROUP BY分組
資料的分組是按照邏輯次序把具有重複值的欄位進行合併。分組函式有:AVG,MAX,MIN,SUM和COUNT等。GROUP BY在select語句中的位置如下
select
from
where
group by
having
order bySELECT語句在使用GROUP BY字句時必須滿足一定條件。特別是被選中的欄位必須出現在GROUP BY 子句中,除了上面提到的分組彙總函式。GROUP BY子句裡的欄位不必與SELECT子句裡的欄位具有相同的次序。只要SELECT子句的欄位名稱是符合條件的,它的名稱就必須出現在GROUP BY 子句裡。而和ORDER BY 子句一樣,GROUP BY 子句裡也可以用整數代表欄位名稱,需要注意的是以數字代表名稱時,第一個欄位名稱用的數字1而不是數字0。
GROUP BY和ORDER BY 的相同之處在於它們都是對資料進行排序。ORDER BY子句專門用於對查詢得到的資料進行排序,GROUP BY子句也把查詢得到的資料排序為適合分組的資料,因此,GROUP BY 子句也可以像ORDER BY子句那樣用於資料排序。
用GROUP BY 子句實現排序操作的區別與缺點是:
- 所有被選中的、非彙總函式的欄位必須列在GROUP BY 子句裡;
- 除非需要使用匯總函式,否則使用GROUP BY 子句進行排序通常是沒有必要的。
所以,GROUP BY 子句用於對相同的資料進行分組,而ORDER BY子句基本上只是用於讓資料形成次序。另一點,GROUP BY子句可以在建立檢視語句中進行資料排序,而ORDER BY子句不行。
HAVING子句和GROUP BY子句聯合使用時,用於告訴GROUP BY 子句在輸出裡包含哪些分組。HAVING對於GROUP BY的作用相當於WHERE對於SELECT的作用。換句話說,WHERE子句設定被選中欄位的條件,而HAVING子句設定GROUP BY子句形成分組的條件。因此,使用HAVING子句可以讓結果裡包含或是去除整組的資料。
多個表結合查詢
結合是把兩個或者多個表組合在一起來獲取資料。常見的結合方式有:等值結合或內部結合,非等值結合,外部結合和自結合。而其中外部結合又被劃分為左外部結合,右外部結合和全外部結合。一般用的關鍵字有JOIN,LEFT,RIGHT等。
在使用結合之前需要考慮一些事情:基於什麼欄位進行結合、是否有公用欄位進行結合、效能問題。查詢裡的結合越多,資料庫需要完成的工作就越多,也就意味著需要越多的時間來獲取資料。在從規格化的資料庫裡獲取資料時,結合是不可避免的,但是需要從邏輯角度來確定結合是正確執行的。不恰當的結合會導致嚴重的效能下降和不準確的查詢結果。
子查詢
1、定義
子查詢也被稱為巢狀查詢,是位於另一個查詢的WHERE子句裡的查詢,它返回的資料通常在主查詢裡作為一個查詢條件,從而進一步限制資料庫返回的資料。
子查詢必須遵循以下規則。
- 子查詢必須位於圓括號裡。
- 除非主查詢裡有多個欄位讓子查詢進行比較,否則子查詢的SELECT子句裡只能有一個欄位。
- 子查詢裡不能用ORDER BY 子句。在子查詢裡,我們可以利用GROUP BY子句實現ORDER BY功能。
- 返回多條記錄的子查詢只能與多值操作符(比如IN)配合使用。
- SELECT 列表裡不能應用任何BLOG、ARRAY、CLOB或NCLOB型別的值。
- 子查詢不能直接被包圍在函式裡。
- 操作符BETWEEN不能用於子查詢,但子查詢內部可以使用它。
2、除錯
除錯具有子查詢的語句的最好方法是分幾個部分對查詢進行求值。首先運算最內層的子查詢,然後逐步擴充套件到主查詢(這和資料庫執行查詢的次序是一樣的)。在單獨運行了每個子查詢之後,就可以把子查詢的返回值代入到主查詢,檢查主查詢的邏輯是否正確。子查詢帶來的錯誤經常是由於對其使用的操作符造成的,比如=、IN、<、>等。
PS:1、所有的sql都是基於ANSI標準;2、涉及的語句都是MS SQL SERVER的
參考:1、http://www.cnblogs.com/zhangzexdu/p/5132490.html
2、《SQL入門經典(第5版)》