fasttext論文 Bag of Tricks for Efficient Text Classification
fasttext: Bag of Tricks for Efficient Text Classification
fasttext是Facebook AI 實驗室在2016年開源的詞向量訓練和文字分類的工具。
Abstract
fasttext是一種情感分類和詞向量表示的簡單且有效的方法。在準確率上和一些深度學習分類器效果相當,在訓練和測試的速度上,比深度學習的模型快了很多數量級。使用標準的多核CPU,10min以內可以訓練1billion級的單詞量,可在1min以內對50w量級的句子做312k類的分類。
1 Introduction
在資訊檢索、排序、文件分類等問題中,文字分類的文字表示是一個重要的任務。近期,越拉越多的應用一些基於深度學習的模型得到句子表示,並且缺的了不錯的效果,這些模型再訓練和測試時比較慢,限制了它們在一些非常大的資料集上的應用。
一些簡單的線性模型效果也不錯,而且計算效率高。這些線性模型通常學習單次級別的表示,而後再進行組合得到句子級別的表示。本文的工作就是擴充套件這些模型以直接學習句子表示。通過合併一些像bag of n-grams的統計學方法,該方法的準確率和深度模型差別不大,但比深度模型快很多數量級。
本文的工作和1998年標準線性文字分類器的一些方法很類似。受一些用於非監督學習詞表示的模型,本文探索了一些簡單的方法。不同於14年Le和Mikolov提出的句子表示的學習方法,本文的方法在測試階段不需要複雜的推論,可以將得到的文字表示在其它問題中複用。本文在標籤預測和情感分析兩類問題上對本文的模型進行評測。
2 Model architecture
句子分類的一種簡單有效的方法就是通過用bag of words的方法表示句子然後訓練一個線性分類器,如LR和SVM。然而線性分類器在不同的特徵和類別上,引數無法共享,泛化性較差。普遍的解決方法是把線性分類器分解到低軼矩陣或者用多層的神經網路。在神經網路中,資訊是通過隱藏層實現共享的。
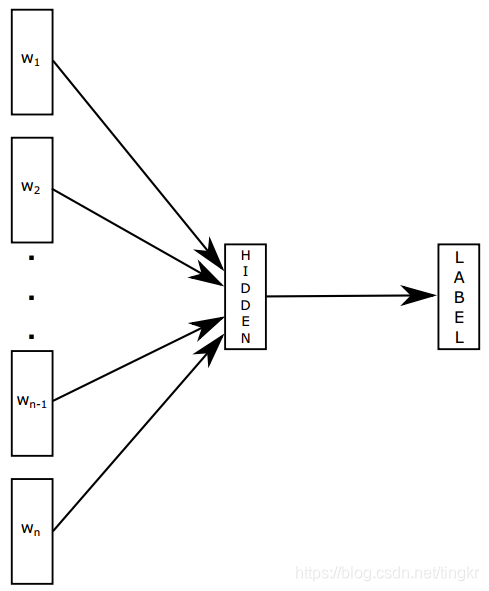
圖1 fast sentence classification模型結構
模型結構中第一列的權重矩陣可以看成是句子中詞的查詢表(look-up table)。詞的表示經過平均後得到整個文字的表示。這個結構和word2vec中的CBOW模型類似,差別在於輸出層的詞變成了標籤。這個模型把有序的單詞序列作為輸入,然後得到基於之前定義好的類別的概率分佈,概率是通過softmax函式計算得到。
模型的訓練和word2vec類似,用隨機梯度下降和反向傳播法。本文利用多個CPU進行非同步訓練。
2.1 Hierarchical softmax
當目標類別比較多的時候,線性分類器的計算量非常大,k為類別,d為隱藏層的維度,則時間複雜度為O(kd)。為了提高時間效率,本文采用了基於Huffman編碼樹的層級softmax方法,時間複雜度降到了 。在樹結構中,目標即為葉子節點。
在測試階段,確定當前單詞最有可能的類別,層級的softmax也比較耗時。每個節點都有一個概率進行描述,這個概率是從根節點到當前節點的路徑概率,如果某節點在第 層,祖先節點分別是 ,則該節點對應的概率為
根據公式可知,每個節點的概率都比其祖先節點的概率小。在樹中,要找的是最大概率的葉節點,因此在追蹤路徑走向時,可以在某一層中拋棄那些概率較小的結點,也就是忽略那些概率較小的路徑。所以測試階段的時間複雜度降到了 ,這個方法則通過二叉樹,把計算Top T的目標分類的時間複雜度降到了 。
2.2 N-gram features
詞袋模型忽略了詞的順序,但是考慮詞的順序則會增加時間複雜度。而本文利用n-gram的機制作為額外的特徵來獲取詞語順序的一些區域性資訊。這一招在實際過程中很管用,效果和直接使用詞語順序的方法差不多。
通過使用hash的trick,本文實現了一種快速且空間利用率高的n-gram的空間對映,當n為2時,只需要10M,其他情況下100M。
3 Experiments
3.1 Sentiment analysis
Datasets and baseline. 本文在8個數據集上進行了實驗,採用了和Zhang el al.1相同的評測指標,選取的baseline是來自Zhang el al.論文裡的N-grams、TFIDF、字母級別的卷積模型(char-CNN)和來自Conneau et al.2深度卷積模型(VDCNN),還和Tang et al.3的論文方法做了比較。
實驗設定:10 hidden units,5 epochs,lr在驗證集上{0.05, 0.1, 0.25, 0.5}.
準確率對比表
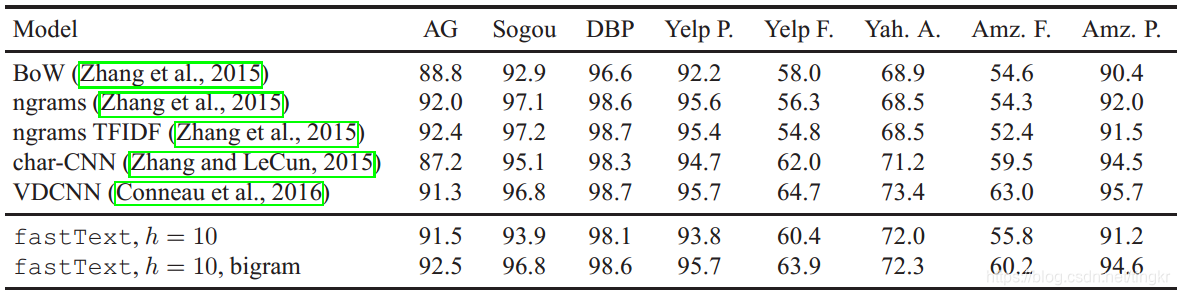
bigram的引入對準確率提升1-4%,準確率隨著n-grams中的n增加相應地增加,如n=3時,在Sougou資料集上提升到97.1%。
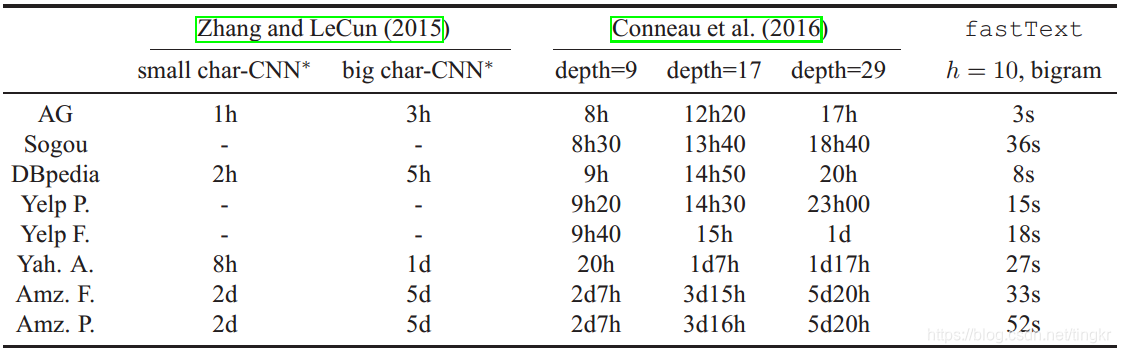
效率對比表
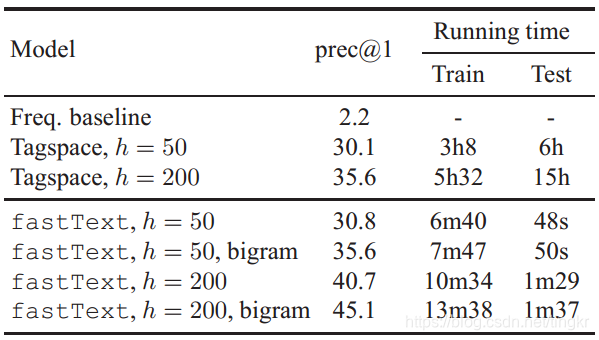
3.2 Tag prediction
Datasets and baseline. YFCC100M dataset, 包括100M帶描述、標題和標籤的圖片。任務是通過標題和描述預測標籤。移除出現次數少於100的詞和標籤,詞典大小為297,141,共312,116個標籤。訓練資料集包括91,188,648個樣例(1.5B token),驗證集包括930,497個樣例,測試集包括543,424個樣例。
實驗設定:5 epochs,baseline的方法Tagspace的hidden layer設為50或200. fasttext引入bigrams對效果提升明顯。
測試時,Tagspace需要計算所有類別的分數,導致速度很慢,fasttext在資料類別很大時(> 300k)在速度上表現出明顯優勢。
準確率和效率對比表