
word2vec 學習和理解
這裡先按吳恩達老師的課程講解的softmax做一個筆記,和之前看的一個大神的文章,相對比,來方便我對word2vec的理解。
目的:學習一個詞嵌入矩陣E。
手段:構建一個語言模型。
最老的方法:
預測一個句子(4個詞)之後的下一個詞是什麼。
例如,下面是一個樣本:
a glass of orange (juice).
樣本輸入: a glass of orange
樣本輸出:juice
實際上,我們會遍歷一篇文章,然後文章中如果有這麼一句話a glass of orange (juice).
它就可以作為一個樣本了。
I want a glass of orange juice.
這樣的句子,按照視窗為4來處理的話,可能會有如下的樣本:
樣本輸入(樣本輸出)
want a glass of (orange)
want a glass of (apple)
want a glass of (mango)
這樣, 經過訓練之後,orange apple mango等詞彙就會有相近的詞向量。
(為什麼?以後可以再思考解釋一下。暫時沒想通)
訓練的模型為:
詞嵌入矩陣E,隨機初始化。假設one-hot表示有10000個詞(實際更多),詞向量維度是300,那麼E大小為300*10000
開始:
(1)->4個詞的one-hot
(2)-> 乘以E,得到4個詞的詞向量表示,合併成一個大的向量
(3)-> 輸入到一個隱藏層
(4)-> 輸出到一個softmax
(5)-> 輸出為樣本輸出。
輸入層:詞向量維度為300,那麼(2)得到的向量長度為4*300 = 1200,即輸入層有1200個特徵。
隱藏層:假設隱藏層的啟用項有500個(可能沒那麼少,這裡打個比方),那麼隱藏層權重矩陣W1 是 1200*500的。不過這層的引數我們不關注。
softmax層:為了獲得一個詞庫總量(本例為10000詞)的分類器。所以softmax的權重為W2 = 500*10000.
分類器如下:
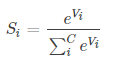
e_Vi是隱藏層的輸出,i表示one-hot的第一個詞。Si是樣本輸出表示的單詞。
可以看到,分母有一個超大的求和,大小為one-hot詞向量大小,這個例子是10000。
為了計算得到一個樣本的損失函式,需要進行10000次求和。
這個計算簡直不能忍的。
於是後面會有其他的模型來解決這個求和量過大的問題(還會解決這個模型的其他缺陷,這裡不做過多討論)。
第二部分
上面,語言模型是根據前面4個詞,預測最後一個詞。
但實際,我們的目標不是語言模型本身,所以可以用另一種方法來預測詞的關係。
比如,用上下文。
I want a glass of orange juice to go ...
還是orange這個詞,這時候,我們的樣本就不一定是前面4個詞了。可以是左邊取幾個,右邊取幾個。
比如如下是一個樣本:(左右視窗是2)
glass of (orange) juice to
此外,還有其他方式,比如取上一個詞作為輸入,預測下一個詞。
of (orange)
之類的。 這個就是skip-gram的思路。
接下來的例子,模型為:
一個上文->預測一個下文
開始:
(1)->one-hot 乘以 詞嵌入矩陣E,得到詞向量
(2)->詞嵌入矩陣輸入到一個softmaxt,直接預測下文
(3)沒有了。
我們看到,吳恩達課程裡,講softmax層的計算公式時,為:
這個公式是直接把前面層所做的東西合併了。
這裡的θ,就是softmax層的權重。小寫t表示單詞t在one-hot裡的下表序號。
這個公式,實際上就是將softmax的輸出做一個歸一化,求得t分類的相對概率。