
實現報表的可控快取
使用快取可以提升報表效能是不爭的事實,一般高階報表工具都會提供報表快取功能,可將整個報表計算結果快取在檔案系統中,以便使用者下次訪問相同引數的報表時可以快速讀取快取結果進行展現。但有些情況下報表開發人員還希望對快取的內容進行更準確和靈活的控制,比如快取的不是整個報表結果而是其中一部分、快取內容可被其它報表或程式複用,以及對不同的快取結果設定不同的超時時間,從而應對資料量和實時性方面的不同情況。這時,一般的報表快取就無法滿足需求了。
集算器與報表結合使用時,可以幫助開發人員靈活控制快取內容。這裡我們將開發人員在使用集算器可以靈活控制的報表快取內容稱為可控快取。可控快取可以帶來更大的靈活性和好處,充分解決實際應用中的報表效能問題。下面我們就對前面提到的部分快取、快取複用和設定不同超時時間三個方面展開討論。
部分快取
在報表開發中,有時並不希望將所有報表結果進行快取,這樣可以避免耗費過高的快取成本(磁碟空間和應用伺服器資源開銷)。另外,當報表中的部分資料實時性要求很高,需要實時與資料庫互動進行資料查詢,那麼這部分資料也不適合進行快取。
通過集算器的可控快取可以將變化不頻繁的中間結果快取起來,當報表再次請求時,實時性要求高的資料仍然實時從資料庫中讀取,同時結合快取中的非實時資料進行報表計算,得到最終報表結果集。
常規快取方案沒有這種快取部分結果的功能,只能設定整個報表是否進行快取,這樣報表在涉及不同時效性資料時就會發生矛盾,而集算器實現的可控快取顯然更加靈活,效率更高。
舉例
訂單(Orders)資料中超過 3 個月的資料就不再發生變化(冷資料)
資料結構如下:
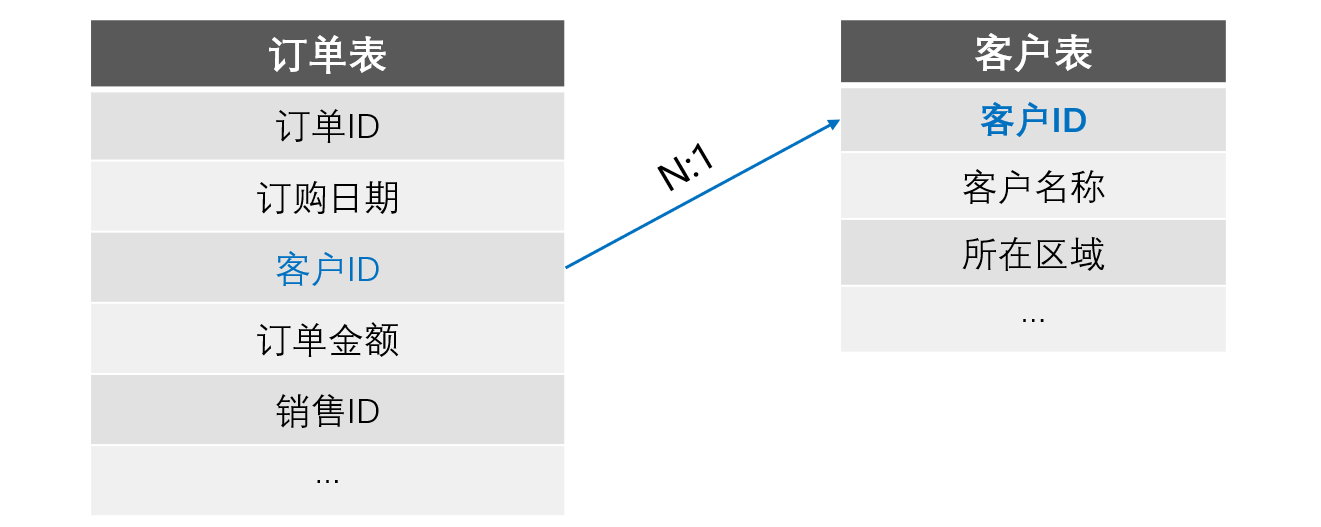
現查詢近 6 個月的訂單明細並彙總月訂單數量和金額。
報表表樣如下:
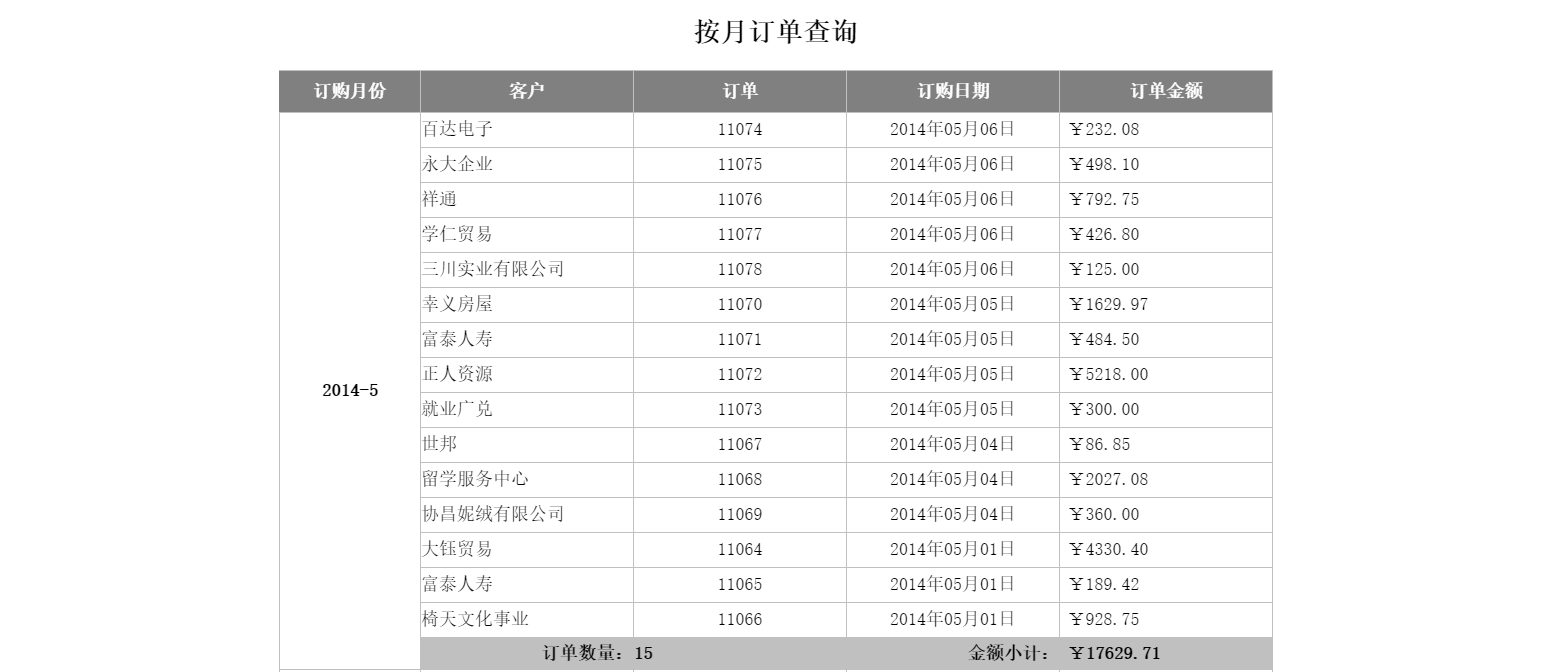
直接從資料庫訂單表檢索 6 個月的資料實現雖然最簡單,但每次查詢都要從資料庫取全部資料顯然效能不高。可以將 3 個月以上不變的資料在初次查詢時快取起來,而 3 個月內的資料仍然從資料庫讀取,這樣以後再查時直接讀快取和資料庫資料來加速報表效能,可以顯著減少資料庫的計算時間和 JDBC 的傳輸時間。
集算器將根據查詢月份判斷:
如果查詢的是歷史資料第一次查詢資料庫並寫快取,以後直接讀快取;
如果查詢的是實時資料則每次都從資料庫讀取;
如果查詢的資料包含歷史資料和實時資料則將歷史資料寫快取,實時資料讀取資料庫。
集算器實現
引數
查詢引數為起止月份(每個月 1 日),實現中日期過濾資料均通過起止引數處理
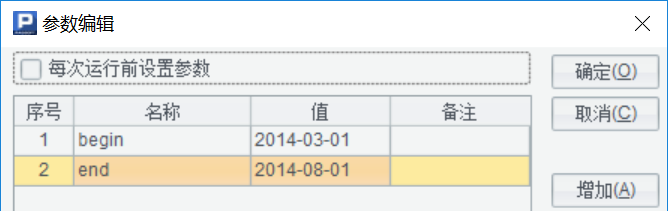
集算器資料準備
| A | B | C | |
|---|---|---|---|
| 1 | =filePath=”/usr/report/cache/” | / 快取目錄 | |
| 2 | =reportName=”orders_customer_month” | / 報表名稱,快取使用報表名 + 引數命名 | |
| 3 | [email protected]([email protected](now()),-3) | / 三個月前日期 | |
| 4 | =his_end=[end,A3].min() | / 歷史資料日期終值 | |
| 5 | [email protected](end) | / 查詢日期終值 | |
| 6 | =sql=”select 公司名稱 客戶, 訂單 ID, 訂購日期, 訂單金額 from 訂單, 客戶 where 訂單. 客戶 ID= 客戶. 客戶 ID and 訂購日期 >=? and 訂購日期 <=?” | ||
| 7 | =f=file(filePath/reportName/”=”/begin/”+”/his_end) | / 快取檔案 | |
| 8 | =rs=[] | / 報表結果集 | |
| 9 | if f.exists() | // 如果有快取 | |
| 10 | [email protected]() | / 歷史資料讀快取 | |
| 11 | >rs=rs|B10 |
/ 快取結果新增到結果集 | |
| 12 | [email protected](A3,1) | / 查詢資料庫起始日期 | |
| 13 | if B12<end | / 有實時資料查詢資料庫 | |
| 14 | =connect(“demo”) | ||
| 15 | >rs=rs|[email protected](sql,B12,A5) |
||
| 16 | return rs | ||
| 17 | else | // 無快取 | |
| 18 | =connect(“demo”) | ||
| 19 | [email protected](sql,begin,A5) | / 全量資料讀庫 | |
| 20 | if begin<his_end | / 將歷史資料寫入快取 | |
| 21 | =B19.select(訂購日期 >=begin && 訂購日期 <=A5) | ||
| 22 | >[email protected](C21) | ||
| 23 | return rs |
指令碼解析:
1、A1-A2 分別設定快取目錄和報表名稱,報表名稱用於快取檔案命名
2、A3-A5 根據月份引數計算曆史資料日期、實時資料日期等
3、A6 為查詢 SQL,由於後面會重複使用,這裡將其賦值給 sql 變數
4、A7 設定快取檔案,檔名為:報表名 = 快取起始月 - 快取終止月,如:orders_customer_month=2014-01-01+2014-04-01
5、A8 定義報表資料集變數 rs,後續讀快取和查詢資料庫結果都會追加到 rs 中
6、A9-C16 判斷快取(包含三個月以上資料)如果存在,則根據查詢月份讀取快取歷史資料(B10),如果還包含實時資料則查詢資料庫(C15),結果集追加到 rs 中併為報表輸出結果(B16)
7、A17-C23 如果沒有快取(可能是初次查詢,也可能查詢的是實時資料),則直接查詢資料庫並返回結果(B19),若查詢資料中包含歷史歷史資料,則寫快取(C21 和 C22)
報表呼叫
這裡假定讀者已經瞭解集算器與報表的關係,集算器僅為報表提供資料準備,將計算結果以資料集的方式提供給報表進行呈現。集算器指令碼可以被潤乾報表 5.0 及以上版本直接引用(集算器資料集);如果是其他報表工具,集算器提供了標準 JDBC 和 ODBC 介面,可以採用類似呼叫儲存過程的方式呼叫集算器指令碼,詳細可以參考教程《應用整合 - 被 JAVA 呼叫》章節,以及《集算器與 BIRT 整合》或《集算器與 JasperReport 整合》。
以上通過舉例說明了通過集算器實現報表快取部分結果提升報表效能的過程,這種方式可以靈活控制快取內容,加速報表執行。此外,將結果快取到磁碟避免了通過資料庫 JDBC 取數效率低下的問題,資料量大時尤其適用,同時由於快取無需和資料庫互動,降低了資料庫的訪問和計算壓力,在報表加速的同時緩解了資料庫負擔。
值得注意的是,業務資料無論是否分庫都可以使用這個方式提升報表效能。
快取複用
集算器實現的可控快取可以複用,一個報表的快取結果(部分或全部)可以被其他報表或程式讀取並使用,而不必像常規報表快取方案那樣重複快取同樣的結果,這同樣也會大幅度提高整體快取的效率。
與快取部分結果適應實時性要求的情況類似,當其他報表或程式使用某個報表的快取結果時,只需從快取中(一般是磁碟檔案)讀取,並與報表中其他資料來源(可能是 DB、檔案,或是另一個報表的快取)進行混合運算,就能得到報表需要的結果集。而常規的報表快取以報表模板為單位進行快取,彼此無法複用,在造成資源浪費之外還會增加一定的效能開銷。
上例中,如果另一張報表希望按客戶來彙總訂單情況:
報表表樣如下:
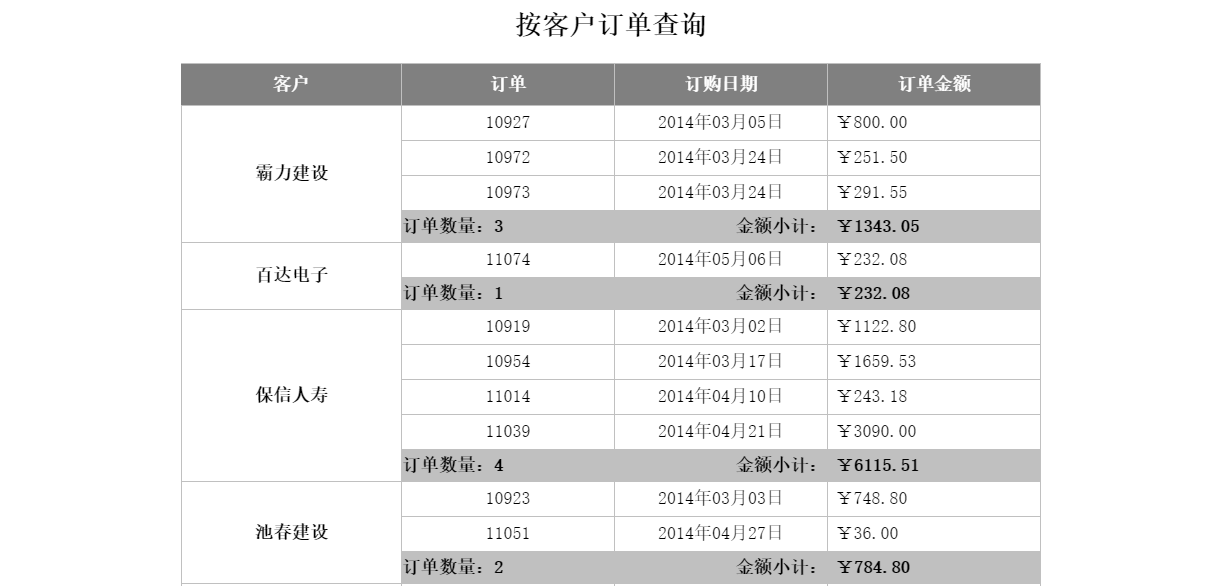
熟悉報表的開發者都知道,這兩張報表只是分組方式不同,資料來源是完全一樣的,這樣我們就還可以使用上面的程式碼獲取資料來源,並且生成和訪問快取,這兩張報表就可以共用快取了。
設定不同的超時時間
我們都知道快取一定都會有超時時間,超過時間後的快取就會因為失效而被清除,報表再訪問時需要重新生成快取檔案。
一般報表工具的快取超時時間會在配置檔案中設定,如 3600s 或 7200s,這種設定有時作用於單張報表的所有引數,有時甚至作用於所有報表,換句話說,整個報表甚至整個系統必須使用同樣的設定。
顯然,這種做法的效能並不高,很難兼顧不同更新頻率的資料。如果能夠針對不同的報表場景設定不同的超時時間,那樣會更加有效。例如,針對大量歷史資料進行查詢的報表,由於歷史資料的變化不大,我們希望報表的快取結果可以儲存較長時間,以便每次查詢時都能從快取中快速讀取結果;而針對資料變化頻繁,實時性要求較高的報表則希望超時時間較短,以便充分滿足資料的實時性要求。
集算器實現的可控快取允許開發人員針對不同的報表需求設定不同的超時時間,以應對上述提到的報表場景,例如可以在第一個例子中增加超時設定。這種做法提供了更高的靈活性,使得報表快取達到真正意義上的精確可控。
舉例
沿用第一個例子,我們增加相應的超時設定。由於該報表月末查詢比較頻繁,因此希望快取有效時間長一些(7 天)。這時只需要將 A9 的表示式改為:
A9: if f.exists()&& interval(f.date(),now())<=7
判斷快取檔案如果存在,並且快取日期為 7 天內,則讀取快取。
本文的例子中用到的是單資料集報表,而實際上多資料集報表需要可控快取的情況更多。一個報表的多個數據集很可能變化的頻率相差很大,有的資料集很穩定,幾天甚至幾個月都不會變,而有的資料集則可能隨時都在變化。採用部分快取並設定不同的超時時間,這時對快取的可用性就非常有意義了,能夠在確保報表資料正確性的同時充分利用快取手段提高訪問效能。
需要說明的是,集算器實現可控快取也有其適用場景,並不能完全取代常規快取,常規快取手段會連同報表計算結果以及呈現屬性儲存在一起,而這裡的可控快取只快取資料,在呈現時還要再次進行外觀計算,因此更適用於資料計算強度較高,但外觀計算強度較低的場景。在實際應用中,可以取長補短,將兩者結合起來使用。