
Spark原理 | SparkSQL Catalyst解析
Catalyst Optimizer是SparkSQL的核心元件(查詢優化器),它負責將SQL語句轉換成物理執行計劃,Catalyst的優劣決定了SQL執行的效能。
查詢優化器是一個SQL引擎的核心,開源常用的有Apache Calcite(很多開源元件都通過引入Calcite來實現查詢優化,如Hive/Phoenix/Drill等),另外一個是orca(HAWQ/GreenPlum中使用)。
關係代數是查詢優化器的理論基礎。常見的查詢優化技術:查詢重用(ReuseSubquery/ReuseExchange等)/RBO/CBO等。
SparkSQL執行流程
SparkSQL中對一條SQL語句的處理過程如上圖所示:
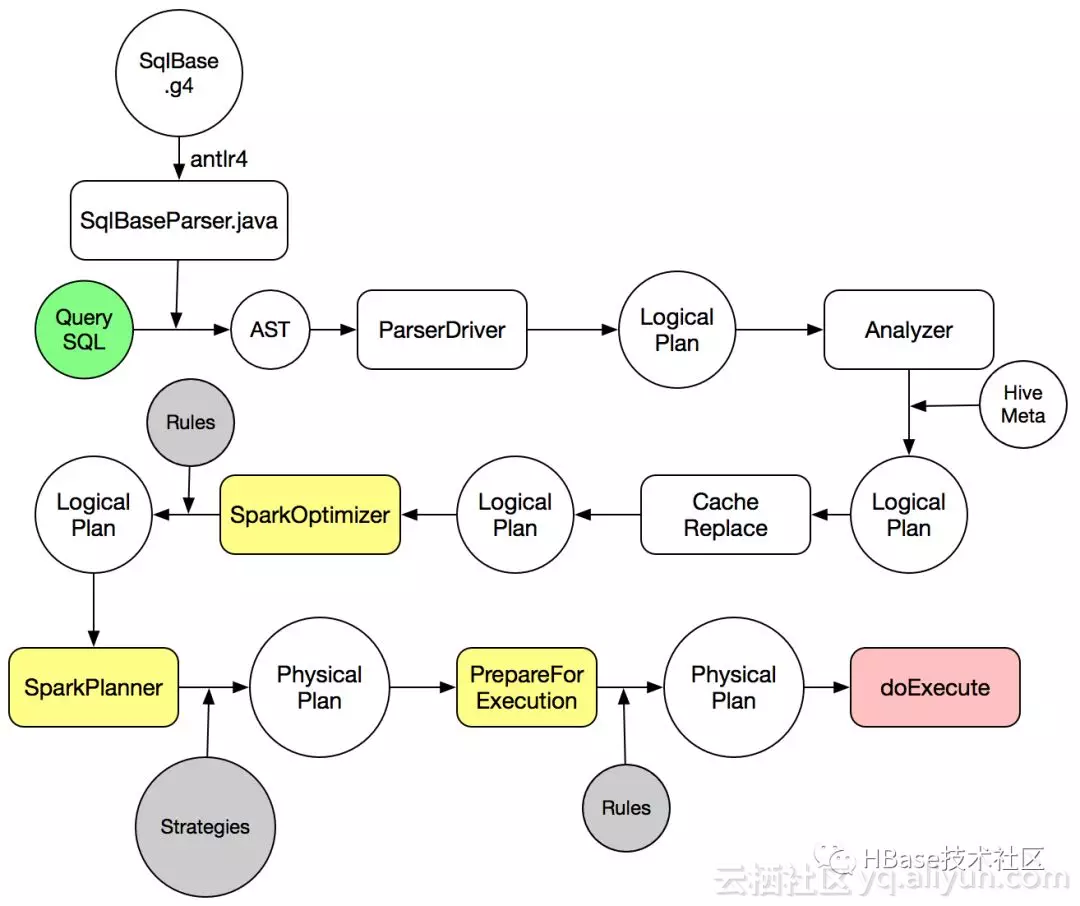
1.SqlParser將SQL語句解析成一個邏輯執行計劃(未解析)
相關推薦
Spark原理 | SparkSQL Catalyst解析
Catalyst Optimizer是SparkSQL的核心元件(查詢優化器),它負責將SQL語句轉換成物理執行計劃,Catalyst的優劣決定了SQL執行的效能。 查詢優化器是一個SQL引擎的核心,開源常用的有Apache Calcite(很多開源元件都通過引入Calcite來實現查詢優化,如
【原創】大資料基礎之Spark(4)RDD原理及程式碼解析
一 簡介 spark核心是RDD,官方文件地址:https://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds官方描述如下:重點是可容錯,可並行處理 Spark r
【原創】大資料基礎之Spark(5)Shuffle實現原理及程式碼解析
一 簡介 Shuffle,簡而言之,就是對資料進行重新分割槽,其中會涉及大量的網路io和磁碟io,為什麼需要shuffle,以詞頻統計reduceByKey過程為例, serverA:partition1: (hello, 1), (word, 1)serverB:partition2: (hell
大資料(Spark-S3-SparkSQL架構及原理)
Spark SQL的發展 HDFS -> HIVE 由於Hadoop在企業生產中的大量使用,HDFS上積累
Spark之SparkSql
.text string pac mit lec ddd style show gist -- Spark SQL 以編程方式指定模式 val sqlContext = new org.apache.spark.sql.SQLContext(sc) val employe
深入研究Spark SQL的Catalyst優化器(原創翻譯)
超越 href 語法 英文 更多 com edi 此外 並行化 Spark SQL是Spark最新和技術最為復雜的組件之一。它支持SQL查詢和新的DataFrame API。Spark SQL的核心是Catalyst優化器,它以一種新穎的方式利用高級編程語言特性(例如Sca
hive on spark VS SparkSQL VS hive on tez
dir csdn cluster 並且 http 緩沖 快速 bsp pos http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details
DNS服務原理及區域解析庫文件配置
DNS原理 區域解析庫 一、DNS服務概述 DNS(Domain Name service或者Domain Name Server)中文名叫做域名服務或者域名服務器, 屬於應用層協議, 為C/S架構, 使用TCP/UDP的53號端口. [root@docker-package ~]# cat /e
spark-submit&spark-class腳本解析
options mman 程序 空字符 結果 ast 數據存儲 zed 大小 ################################################ #從spark-shell調用之後,傳進來--class org.apache.spark.r
CopyOnWriteArrayList實現原理以及原始碼解析
CopyOnWriteArrayList實現原理以及原始碼解析 1、CopyOnWrite容器(併發容器) Copy-On-Write簡稱COW,是一種用於程式設計中的優化策略。 其基本思路是,從一開始大家都在共享同一個內容,當某個人想要修改這個內容的時候,才
LinkedList實現原理以及原始碼解析(1.7)
LinkedList實現原理以及原始碼解析(1.7) 在1.7之後,oracle將LinkedList做了一些優化, 將1.6中的環形結構優化為了直線型了連結串列結構。 1、LinkedList定義: public class LinkedList<E>
ArrayList實現原理以及原始碼解析(補充JDK1.7,1.8)
ArrayList實現原理以及原始碼解析(補充JDK1.7,1.8) ArrayList的基本知識在上一節已經討論過,這節主要看ArrayList在JDK1.6到1.8的一些實現變化。 JDK版本不一樣,ArrayList類的原始碼也不一樣。 1、ArrayList類結構:
ArrayList實現原理以及原始碼解析(JDK1.6)
ArrayList實現原理以及原始碼解析(JDK1.6) 1、ArrayList ArrayList是基於陣列實現的,是一個動態陣列,其容量能自動增長,類似於C語言中的動態申請記憶體,動態增長記憶體。 ArrayList不是執行緒安全的,只能用在單執行緒環境下。
ConcurrentHashMap實現原理以及原始碼解析
ConcurrentHashMap實現原理以及原始碼解析 ConcurrentHashMap是Java1.5中引用的一個執行緒安全的支援高併發的HashMap集合類。 1、執行緒不安全的HashMap 因為多執行緒環境下,使用Hashmap進行put操作會引起死迴圈
CocurrentHashMap實現原理及原始碼解析
##1、CocurrentHashMap概念 CocurrentHashMap是jdk中的容器,是hashmap的一個提升,結構圖: 這裡對比在對比hashmap的結構: 可以看出CocurrentHashMap對比HashMa
二維碼掃描登陸的原理及深入解析
一、單方掃描登陸 基本的實現流程: PC端開啟login.html,ajax請求passport.wx.com?appid=123&redirect_uri=monitor.wx.com,服務端響應帶有uuid=456和狀態碼200的內容,再次發起兩個aj
機器學習實戰(Machine Learning in Action)學習筆記————03.決策樹原理、原始碼解析及測試
機器學習實戰(Machine Learning in Action)學習筆記————03.決策樹原理、原始碼解析及測試關鍵字:決策樹、python、原始碼解析、測試作者:米倉山下時間:2018-10-24機器學習實戰(Machine Learning in Action,@author: Peter Harr
【Spark】SparkSql分析結果寫入Mysql
文章目錄 前言 裝備 Core Code 1. Mysql資料庫建結果表 2. DB配置檔案 3. 搞個檔案 4. 資料分層 5. SparkJob父類 6. MetroAnalysisJob(具體
【NLP】Attention原理和原始碼解析
對attention一直停留在淺層的理解,看了幾篇介紹思想及原理的文章,也沒實踐過,今天立個Flag,一天深入原理和原始碼!如果你也是處於attention model level one的狀態,那不妨好好看一下啦。 內容: 核心思想 原理解析(圖解+公式) 模型分類 優缺點 TF原始碼解析
Lucene全文檢索之倒排索引實現原理、API解析【2018.11】
》 官網 http://lucene.apache.org/ 下載地址:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/7.5.0/ 》 Lucene的全文檢索是指什麼: 程式掃描文件