
Python 解析百度,搜狗詞庫
阿新 • • 發佈:2018-11-28
最近在解析百度詞庫https://shurufa.baidu.com/dict。說一下解決思路吧。
把檔案下載下來會發現是位元組流。而計算機儲存資料有兩種方式,大端位元組序,小端位元組序。
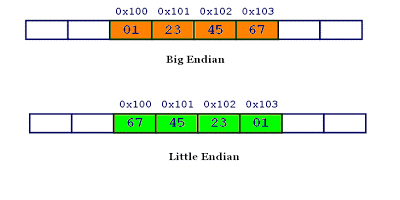
計算機的內部處理都是小端位元組序。人類還是習慣讀寫大端位元組序。所以,除了計算機的內部處理,其他的場合幾乎都是大端位元組序,比如網路傳輸和檔案儲存。
計算機處理位元組序的時候,不知道什麼是高位位元組,什麼是低位位元組。它只知道按順序讀取位元組,先讀第一個位元組,再讀第二個位元組。
如果是大端位元組序,先讀到的就是高位位元組,後讀到的就是低位位元組。小端位元組序正好相反。
而百度詞庫在儲存的時候使用了大端儲存,但如果想要解析出漢字,需要先將大端儲存轉為小端儲存
def be2le(self): of = open(self.originfile,'rb') lef = open(self.lefile, 'wb') contents = of.read() contents_size = contents.__len__() mo_size = (contents_size % 2) #保證是偶數 if mo_size > 0: contents_size += (2-mo_size) contents += contents + b'0000' #大小端交換 for i in range(0, contents_size, 2): self.buf[1] = contents[i] self.buf[0] = contents[i+1] le_bytes = struct.pack('2B', self.buf[0], self.buf[1]) lef.write(le_bytes) print('寫入成功轉為小端的位元組流') of.close() lef.close()
之後再讀取位元組流,每4位解析成一個漢字字母或者字元。注意百度詞庫解析是從0x350這個位置開始。再根據規律拼接。經實測搜狗詞庫的解析上面程式碼同樣適用起始位置改為0x2628.
詳情在我的git上https://github.com/zhao-dapeng/Lexicon-analysis/blob/master/baidudict.py好用的話記得點個start