
第四十二講 I/O流——位元組流在操作中文資料
本篇文章主要圍繞字元編碼展開,為了能夠更好地講述這一主題,我將從位元組流操作中文資料開始。
位元組流操作中文資料
假設編寫有如下程式,程式碼貼出如下:
package cn.liayun.readcn;
import java.io.FileOutputStream;
import java.io.IOException;
public class ReadCNDemo {
public static void main(String[] args) throws IOException {
writeCNText();
}
public static 此時執行以上程式,可以發現在cn.txt文字檔案中有”你好“兩字,並且檔案大小僅有4位元組。其原因是String類的getBytes()方法是使用平臺的預設字符集(即GBK碼錶,而在GBK碼錶裡面,一箇中文佔2個位元組)將”你好“字串編碼為了一個位元組陣列。
上面程式將”你好“兩字寫入cn.txt文字檔案之後,我們需要使用位元組流將其讀取出來,由於該文字檔案大小僅有4位元組,可使用位元組輸出流的read()方法一個位元組一個位元組地讀取出來,程式碼如下:
package cn.liayun.readcn;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class ReadCNDemo {
public static void main(String[] args) throws IOException {
readCNText();
}
public static void readCNText() throws IOException {
FileInputStream fis = 執行以上程式,可發現Eclipse控制檯列印如下,截圖如下。
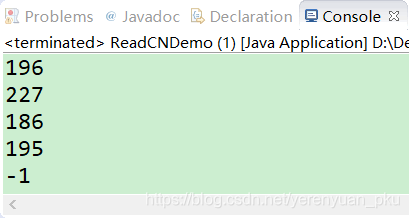
上面輸出的東西是一堆數字,我們可能看不懂,而我們想要看到的是”你好“兩字,那麼問題歸納為:使用位元組輸出流讀取中文時,是按照位元組形式,但是一箇中文在GBK碼錶中是2個位元組,而且位元組輸出流的read()方法一次讀取一個位元組,如何可以獲取到一箇中文呢?解決方案就是別讀一個就操作,多讀一些存起來,再操作,存到位元組陣列中,將位元組陣列轉成字串就哦了。
package cn.liayun.readcn;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class ReadCNDemo {
public static void main(String[] args) throws IOException {
readCNText();
}
public static void readCNText() throws IOException {
FileInputStream fis = new FileInputStream("tempfile\\cn.txt");
//讀取中文,按照位元組的形式,但是一箇中文,GBK碼錶中是兩個位元組
//而位元組流的read方法一次讀取一個位元組,如何可以獲取到一箇中文呢?
//別讀一個就操作,多讀一些存起來,再操作,存到位元組陣列中,將位元組陣列轉成字串就哦了
byte[] buf = new byte[1024];
int len = fis.read(buf);
String s = new String(buf, 0, len);//將位元組陣列轉換成字串,而且是按照預設的編碼表(GBK)進行解碼。
System.out.println(s);
fis.close();
}
}
須知String類的String(byte[] bytes, int offset, int length)構造方法是通過使用平臺的預設字符集(即GBK碼錶)解碼指定的byte子陣列,構造一個新的String。接下來,就要引出編碼表這一概念了。
編碼表
編碼表的由來
計算機只能識別二進位制資料,早期由來是電訊號。為了方便應用計算機,讓它可以識別各個國家的文字,就將各個國家的文字用數字來表示,並一一對應,形成一張表,這就是編碼表。
常見的編碼表
| 編碼表名稱 | 說明 |
|---|---|
| ASCII | 美國標準資訊交換碼,用一個位元組的7位可以表示 |
| ISO8859-1 | 拉丁碼錶或歐洲碼錶,用一個位元組的8位表示 |
| GB2312 | 中國的中文編碼表 |
| GBK | 中國的中文編碼表升級,融合了更多的中文文字元號 |
| GB18030 | GBK的取代版本 |
| BIG-5 | 通行於臺灣、香港地區的一個繁體字編碼方案,俗稱”大五碼“ |
| Unicode | 國際標準碼,融合了多種文字,所有文字都用兩個位元組來表示,Java語言使用的就是Unicode |
| UTF-8 | 最多用三個位元組來表示一個字元。UTF-8不同,它定義了一種”區間規則“,這種規則可以和ASCII編碼保持最大程度的相容:它將Unicode編碼為00000000-0000007F的字元,用單個位元組來表示;將Unicode編碼為00000080-000007FF的字元,用兩個位元組來表示;將Unicode編碼為00000800-0000FFFF的字元,用三個位元組來表示 |
編碼與解碼
- 編碼:把看得懂的變成看不懂的。即將字串變成位元組陣列(String→byte[]),代表方法為
str.getBytes(charsetName); - 解碼:把看不懂的變成看得懂的。即將位元組陣列變成字串(byte[]→String),代表方法為
new String(byte[], charsetName)。
關於編碼與解碼,有一個結論,即由UTF-8編碼,自然要通過UTF-8來解碼;同理,由GBK來編碼,自然也要通過GBK來解碼,否則會出現亂碼。下面我會通過若干個案例來詳述編碼與解碼。
由GBK來編碼,通過GBK來解碼
首先執行以下程式,給出程式程式碼如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 預設編碼方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "GBK");// 通過GBK來解碼
System.out.println("s1 = " + s1);
}
}
執行以上程式,可發現Eclipse控制檯列印如下,截圖如下。

發現輸出結果並無亂碼。
由GBK來編碼,通過UTF-8來解碼
然後再執行以下程式,觀察執行後的結果,給出程式程式碼如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 預設編碼方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通過UFT-8來解碼
System.out.println("s1 = " + s1);
}
}
執行以上程式,可發現Eclipse控制檯列印如下,截圖如下。
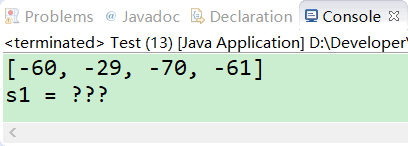
發現輸出了亂碼——???。
由UTF-8來編碼,通過UTF-8來解碼
那怎麼不是像上面那樣輸出三個問號呢?method()方法的程式碼應修改為如下,即可解決亂碼問題。
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("UTF-8");// 預設編碼方式就是UTF-8
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通過UFT-8來解碼
System.out.println("s1 = " + s1);
}
}
再次執行以上程式,可發現Eclipse控制檯列印如下,截圖如下。

由UTF-8來編碼,通過GBK來解碼
接著再執行以下程式,觀察執行後的結果,給出程式程式碼如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("UTF-8");// 預設編碼方式就是UTF-8
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "GBK");// 通過GBK來解碼
System.out.println("s1 = " + s1);
}
}
執行以上程式,可發現Eclipse控制檯列印如下,截圖如下。

發現輸出結果出現了亂碼,至於怎麼解決我就不說了。
由GBK來編碼,再通過ISO8859-1來解碼,亂碼問題如何解決?
這裡有一種特殊的情況,先對字串“你好”進行GBK編碼,再通過ISO8859-1解碼,程式程式碼如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 預設編碼方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "ISO8859-1");// 通過ISO8859-1來解碼
System.out.println("s1 = " + s1);
}
}
執行以上程式,輸出結果肯定會出現亂碼——???。

如果要輸出正確的字串內容,可對s1進行ISO8859-1編碼,然後再通過GBK解碼,所以method()方法的程式碼應修改為如下,即可解決亂碼問題。
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 預設編碼方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "ISO8859-1");// 通過ISO8859-1來解碼
System.out.println("s1 = " + s1);
// 對s1進行ISO8859-1編碼
byte[] b2 = s1.getBytes("ISO8859-1");
System.out.println(Arrays.toString(b2));
String s2 = new String(b2, "GBK"); // 通過GBK來解碼
System.out.println("s2 = " + s2);
}
}
不理解以上程式碼沒關係,下面我會圖解,如下:

由GBK來編碼,再通過UTF-8來解碼,亂碼問題如何解決?
現在來思考這樣一個問題:先對字串“你好”進行GBK編碼,再通過UTF-8解碼,編寫程式碼如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 預設編碼方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通過UTF-8來解碼
System.out.println("s1 = " + s1);
}
}
執行以上程式,此時肯定會輸出亂碼——???。如果想要輸出正確的字串內容,可不可以對s1進行一次UTF-8編碼,然後再通過GBK解碼呢?即method()方法的程式碼應修改為如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 預設編碼方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通過UTF-8來解碼
System.out.println("s1 = " + s1);
// 對s1進行UTF-8編碼
byte[] b2 = s1.getBytes("UTF-8");
System.out.println(Arrays.toString(b2));
String s2 = new String(b2, "GBK"); // 通過GBK來解碼
System.out.println("s2 = " + s2);
}
}
答案是不可以。如若不信,讀者不妨試著呼叫以上方法,可以看到Eclipse控制檯列印如下,給出截圖。

發現依然輸出亂碼——錕斤拷錕?,其原因又是什麼呢?不妨畫張圖來解釋一下。
