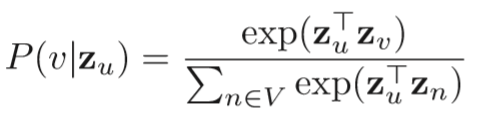network embedding 學習心得
network embedding學習心得
如今,網路這種形式被廣泛應用在各個領域,例如社交網路,生物網路和資訊網路。隨著如今大資料的火熱,資訊變得越來越繁多,網路也變得越來越龐大複雜,因此對於網路的分析和處理也變得越來越有挑戰性。其中一項挑戰就是怎麼樣找到一種有效的網路表示,通過這種表示使得網路相關的任務在時間和空間上更有效率。
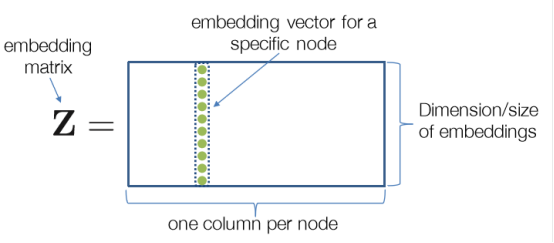
Network embedding 是一種網路表示的方法,它通過學習來將網路中的節點對映到低緯度的向量空間中,節點之間的關係(如邊)可以通過計算它們在向量空間中的距離來捕獲,即網路中節點的拓撲資訊和結構資訊也要嵌入到向量空間中去。

這種網路表示方法相較傳統的方法優點是十分明顯的,傳統的方法通常直接使用網路的鄰接矩陣去表示網路,這樣就很有可能包含噪聲或冗餘資訊,並且當網路較大時,這種表示方法佔用的空間也是巨大的。而基於嵌入的方法是通過學習來獲得網路中節點的表示,所以可以減少噪聲或冗餘資訊,並且可以保留內部的結構資訊。同時,由於對映的方法是由研究者來定義,即研究者可以根據實際的問題來嵌入他感興趣的資訊到向量空間中,所以這種方法具有更高的靈活性和可擴充套件性。由於學習後的節點之間不再耦合,所以可以將主流平行計算的解決方案應用到大規模的網路分析中去。此外,network embedding與如今比較火熱的機器學習方向關係緊密,許多現成的機器學習方法(如深度學習模型)可以直接應用與解決網路問題。
Network embedding通常有兩個目標:首先,可以從學習的向量空間中重建原始網路,即如果兩個節點之間存在邊的關係,則在向量空間中這兩個節點之間的距離應該相對較小,通過這種方式可以很好地保持網路關係。其次,學習的向量表示還可以有效地支援網路推理,例如邊的預測、識別重要的節點和推斷節點標籤等。
總的來說,network embedidng有三個步驟:
1. 定義一個編碼器(即網路中的節點到低緯度向量空間的對映)。
2. 定義一個節點相似度函式(即如何計算原始網路中節點之間的相似度)。
3. 通過學習來對編碼器進行更新,使得原始圖中節點之間的相似度可以通

可以看出,network embedding的一個關鍵點在於如何定義節點之間的相似度,即可以認為相連線的兩個節點是相似的,也可以認為有共同鄰居的兩個節點是相似的,或者可以認為具有相似的結構環境的節點是相似的……以此可以設計不同的embedding方法。
這裡舉幾個例子簡單瞭解一下network embedding 的方法和改進思路:
1. 基於鄰接矩陣的相似度
這種方法通過邊的權值來定義節點之間的相似度,即兩個節點之間存在邊且邊的權值越大,兩個節點的相似度也就越大,通過此定義我們可以得到相應的損失函式:
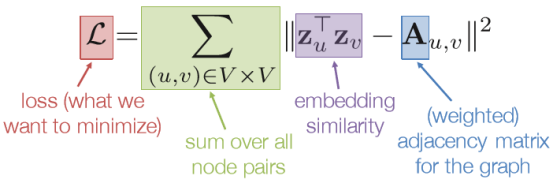
然後可以用梯度下降(SGD)等方法去最小化損失函式,並通過此過程來不斷更新Z來學習節點的向量表示。
這種方法的缺點很明顯:
一是時間複雜度較高(Ο(|V|2)),因為要考慮每一對節點之間的相似度。
二是引數較多(Ο(|V|)),即每個節點的向量表示中的每一個元素都需要當作引數進行更新。
三是隻考慮了局部直接相連的關係,對於網路的整體資訊沒有得到保留。
2. Random Walk Embedding
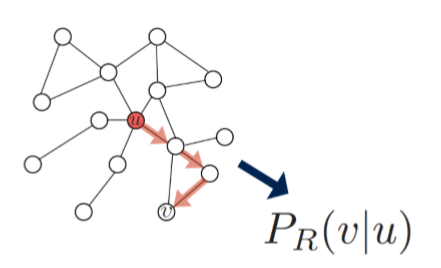
Random walk embedding 是目前比較成功且被廣泛利用的一種embedding方法,目前許多最新的方法是在它的基礎之上進行改進得到的,它的思想是認為在一次隨機遊走的過程中所遍歷的節點是具有相似性的,若兩個節點同時出現在一次隨機遊走的次數越多,則它們之間的相似度也就越高。在此方法中,節點的向量表示的點積對應的是兩個節點同時出現在一次隨機遊走的概率。
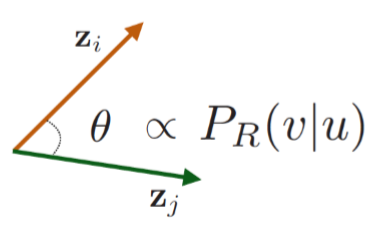
這種方法有效地解決了上一方法中存在的問題,一是它通過隨機遊走整合了局部和高階鄰居的資訊,二是在訓練過程中不需要考慮所有的節點對(只需要考慮在隨機遊走過程中同時出現的節點)。
Random walk embedding的步驟如下:
a. 定義隨機遊走策略R和遊走長度,對網路中的每個節點進行一定次數的隨機遊走。
b. 對每次遊走的開始節點u,收集它所對應的在隨機遊走過程中出現的節點集合NR(u)。
c. 根據如下的損失函式對節點的向量表示進行更新。

其中,P(v|zu)可以通過softmax來表示: