
機器學習 -- 文字挖掘
1. 文字分類
(1)分詞: 中文分詞系統 -- NLPIR(也叫ICTCLAS2013), 還有庖丁解牛分詞器。
召回率(Recall):是指檢索出的相關文件數和文件庫中所有的相關文件數的比率,衡量的是檢索系統的查全率。
精度(Precise):是指檢索出的相關文件數與檢索出的文件總數的比率,衡量的是檢索系統的查準率。
(2)文字表示。 也就是文字的向量化。用得比較多的模型是向量空間模型(VSM)。其基本思想是把文件簡化為特徵項的權重為分量的向量表示。權重用詞頻表示。詞頻分為:
(a)絕對詞頻:詞在文字中出現的頻率表示文字
(b)相對詞頻: 即歸一化的詞頻。
歸一化就是從絕對數量轉化為比例的一種思路。主要運用 TF-IDF(Term Frequency-Inverse Document Frequency)公式。例如:一篇文章的總詞語數是100個,而詞語“汽車”出現了5次,那麼“汽車”一詞在該文章聽詞頻就是 5/100=5%,一個計算檔案頻率(IDF)的方法是測定有多少份檔案出現過“汽車”一詞,然後除以檔案集裡包含的檔案總數。所以如果“汽車”一詞在 100份檔案中出現過,而檔案總數是10000份,其逆向檔案頻率(IDF)是 lg(10000/100)=2 (lg 是底為10的對數)。最後的 TF-IDF=5%*2=10%。如果某個詞彙在一篇文章中出現的頻率 TF 高,並且在其他文章中很少出現,則認為這個詞彙有很好的類別區分能力,適合用來分類。TF 表示該詞彙在文件中出現的頻率,而 IDF則表示含有該詞彙的文件比例越低,則IDF越大,則說明該詞彙具有越好的類別區分能力。
(3)分類標記
分詞和分詞權重最後要和分類的標籤之間產生一個對映關係,而描述這種對映的過程是需要演算法來實現的,可以用概率來實現,也可以用基於向量空間的迴歸來實現。常用的演算法有 Rocchio 演算法、樸素貝葉斯分類演算法、K-近鄰演算法、決策樹演算法、神經網路和支援向量機演算法等。
2. Rocchio 演算法
核心思路是給每一個文件的類別都做一個標準向量 ---- 也有的地方稱為原型向量,然後用待分類的文件的向量和這個標準向量比一下餘弦相似度,相似度越高越可能屬於該分類,反之則不然。計算公式:
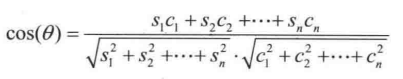
其中 S1, S2, S3...Sn 是原型向量的各個維度, C1, C2, C3...Cn 是待分類的向量的各個維度。
Rocchio 演算法的改進版本是不僅依據正樣本計算正向量,還根據負樣本計算負向量。
Rocchio 演算法做了兩個假設,使得它的分類能力打了很大的折扣:
假設一: 一個類別的文件僅僅聚集在一個質心的周圍,實際情況往往不是如此。
假設二:訓練資料是絕對正確的,因為它沒有任何定量衡量樣本是否含有噪聲的機制,錯誤的分類資料會影響質心的位置。
3. 樸素貝葉斯演算法
樸素貝葉斯演算法關注的是文件屬於某類別的概率。文件屬於某個類別的概率等於文件中每個詞屬於該類別的概率的綜合表示式。而每個詞屬於該類別的概率又在一定程度上可以用這個詞在該類別訓練文件中出現的次數(詞頻資訊)來粗略估計。
步驟如下:
(1) 對訓練文章進行分詞和向量化
(2) 對所有文章類別計算 P(Dj | x)、P(y | Dj) 和 P(z | Dj) 等
(3) 對待分類的文章進行分詞和向量化
(4)用待分類文章的詞向量中的每個詞計算 P(x | Dj )、P(y | Dj) 和 P(z | Dj) 等
注意: P(x | Dj ) 可不是計算一個值,而是計算整個詞向量中所有的詞,如果詞向量有 1000 個元素,那麼 Dj 就是 D1 到 D1000,這 1000個詞都要進行計算。
(5) 計算概率,看待分類文章屬於哪個型別的文章概率最大。
公式: 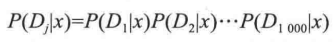 變形簡化成:
變形簡化成: 
其中, P(x | Dj ) 就是要求的值,即完整的詞向量 Dj 最終屬於 x 文章分類的概率。
P(Dj)可以設為1,因為對於已經拿到的特分類文字,所有的詞頻發生概率就已經是 1 了。
P(x) 是所有訓練文章中 x 類文章出現的概率。
4. K-近鄰演算法
演算法思路: 沒有必要去總結原型向量,只需原始的訓練樣本,這些樣本具有最基礎最原始而且準確的向量資訊。
流程: (1) 對每個樣本都進行分詞和向量化
(2) 對需要判定的樣本也進行分詞和向量化
(3) 玍判定的樣本的向量和所有訓練的樣本進行向量特徵比對,也就是相似度比對。這樣會得到它與所有訓練樣本的相似度排名列表。
(4) 從這個列表中找出相似度最高的 K 篇文章,根據這 K 篇文章的類別分別投票決定待判定的樣本屬於哪一類。
優點: 可以克服 Rocchio 演算法中無法處理線性的缺陷,同時“訓練成本”也非常低,只需加入新的訓練樣本即可。
缺點: 計算成本比較高。非常致命的缺點。
5. 支援向量機(SVM)演算法
SVM 分類器的文字分類效果很好,可以認為是最好的分類器之一。
優點:通用性較好,分類精度高,分類速度快,分類速度與訓練樣本個數無關。在查準率和查全率方面都優於KNN及樸素貝葉斯方法
缺點:訓練速度很大程度上受到訓練集規模的影響,計算開銷比較大。一些改進方法: Chunking 方法, Osuna 演算法、SMO 演算法 和互動 SVM。