
詳談分散式最終一致性
“什麼是分散式系統?這取決於看系統的角度。對於坐在鍵盤前使用IBM個人電腦的人來說,電腦不是一個分散式的系統。但對於在電腦主機板上趴著的蟲子來說,這臺電腦就是一個分散式系統。” —— Leslie Lamport
引言
分散式一致性問題隨處可見,任何一個實體/聯接模型,都可能存在分散式一致性問題。如果把單機拆開來看,CPU、記憶體、I/O裝置組成的機箱本身就是一個小型的分散式系統,需要確保對這個系統操作的最終一致性。幸運的是這部分工作已經交給作業系統和資料庫軟體來幫我們完成。而在大型分散式企業級應用中,分散式最終一致性方案需要根據系統自身特點量身定製,是系統設計的重點。近年來隨著滬江業務的快速增長和微服務治理推廣,本地ACID事務早已不能滿足業務和系統的發展需求。大部分業務流程都需要跨多微服務的呼叫來協作完成,並且要求系統確保分散式最終一致性。
可以選擇分散式事務框架方案,目前主流的分散式事務框架大致可分為3類實現 :
-
基於XA協議的兩階段提交(2PC)方案
-
基於支付寶最早提出的TCC(Try、Confirm、Cancel)方案
-
基於ebay最早提出的訊息佇列非同步確保方案
此外還有較輕的解決方案,業務系統可以根據自身需要,選擇通過冪等/重試、狀態機、恢復日誌、非同步校驗等技術來確保最終一致性。
重型武器
採用分散式事務框架的方案,最終一致性由分散式事務框架保證,業務程式設計師對框架細節完全透明。選擇這種方案,需要注意幾個點。首先,由於分階段提交協議本身的脆弱性,主流分階段提交協議如2PC,3PC, TCC都無法完全確保最終一致性,要採用非同步校驗的手段兜底。其次,分階段提交協議帶來的高延遲,多次協議通訊RTT帶來的時間損耗。第三,基於訊息佇列非同步確保的分散式事務框架實現,需要考慮訊息可靠性和業務侵入問題。分散式事務框架也有巨大的優勢,首先,分散式事務被框架封裝成切面,業務開發只需關心純業務。其次,分散式事務的程式碼開發量大大減少。對一致性和程式碼質量有極高要求的銀行、金融領域,分散式事務框架是最佳選擇。
輕型武器
不同於採用分散式事務框架的最終一致性方案,程式設計師也可以選擇通過冪等/重試、狀態機、恢復日誌、非同步校驗等技術來確保最終一致性。這種方案不受限於平臺和框架,系統較精簡靈活,初期業務系統大都基於這種分散式一致性解決方案。不過這種方案對業務開發的要求更高,分散式一致性邏輯要業務程式設計師程式碼實現,容易出現bug。
其實,主流的分散式事務框架也是通過這些基本的系統機制如冪等/重試、狀態機、恢復日誌、非同步校驗等來確保的最終一致性,對比兩種方案,下文主要圍繞後一種展開論述,討論5點使系統達成分散式最終一致性的技術實踐。
原則
1、CAP定理

如下三屬性,任何一個聯網的共享資料系統最多隻能同時滿足 2 個 :
-
一致性(Consistency) : 每次讀取都會收到最新的寫入或錯誤
-
可用性(Availability) : 每個請求都會收到一個不是錯誤的響應
-
分割槽容忍性(Partition tolerance) : 節點之間的網路丟棄(或延遲)了任意數量的訊息,系統仍繼續執行
由於分割槽容忍性是可伸縮的最基本要求,放棄分割槽容忍性等於放棄可伸縮,所以分割槽容忍性是必選項,大部分的分散式系統都是在C和A之間做選擇。需要注意的是,雖然C都叫一致性,但CAP定理中的C和資料庫事務ACID中的C是完全不同的兩個定義。
2、BASE原則
-
Basically Available : 基本可用
-
Soft state : 軟狀態
-
Eventual consistency : 最終一致性
BASE原則發展自CAP定理,捨棄了系統的強一致性而選擇AP,但每個應用可以根據自身的業務特點,採用適當的方式來使系統達到最終一致性。用較通俗的話來描述就是 : “過程寬鬆,結果嚴格,你的老闆不關心過程,只看結果”。NoSQL資料庫Cassandra就是遵循的BASE原則設計。不過也有分散式系統設計不是遵循BASE原則,而是選擇CAP中的CP,如HBase。當然,系統對CAP三者的取捨並不是一成不變,可以根據實際需要改變策略。
實踐
1、重試
重試機制可以使分散式不一致資料自動恢復,前提是重試介面要提供冪等保證。重試機制是達成分散式最終一致性的重要手段。例如,超時重傳是TCP協議保證資料可靠性的一個重要機制,核心思想其實就是重試。在此我向大家推薦一個架構學習交流裙。交流學習裙號:687810532,裡面會分享一些資深架構師錄製的視訊錄影
-
同步重試 : 在上次請求失敗或超時,程式再次發起同步呼叫請求。後端程式不推薦同步重試,其一因為同步等待佔用系統執行緒資源,其二因為重試引起的流量放大,可能導致系統雪崩。
-
非同步重試 : 通過非同步系統(訊息佇列或排程中介軟體)對失敗或超時請求再次發起呼叫。推薦這種方式的重試,重試的時間間隔可以設定為根據重試次數指數增長,超過重試閾值仍未成功,可以報警通知並由人工訂正。
重試也是提高系統可用性的一種有效手段。如果一個服務的可用性為98%(有1個9),1次重試之後其可用性可達到99.96%(3個9),2次重試可以達到99.9992%(5個9)。
2、冪等
冪等的數學定義為
用通俗的話來說就是 : 相同的操作執行多次 和 執行一次產生的效果是一樣的。有的操作是天然冪等的,如查詢、刪除操作。有的操作是人為使其冪等,例如TCP的超時重傳操作就是冪等的,無論客戶端將一個seq位元組傳送多少次,服務端視窗只會用一次該位元組。冪等實現方式有很多 :
-
基於記錄的悲觀鎖,MySQL中通過SELECT FOR UPDATE語句實現。這種實現方式要設定AUTOCOMMIT=0,加鎖和更新記錄在同一個事務中,長時間鎖定記錄會降低系統的TPS,高併發場景不推薦使用。
-
基於記錄版本號或狀態機的樂觀鎖方案,適用於更新資料場景。例如,使用者下單購買一個商品的扣庫存操作實現冪等,可以用如下SQL語句實現 : UPDATE stocktable SET stock = stock - 1, version = version + 1 WHERE product_id = 123 and version = 1
-
基於資料庫唯一索引的去重表,適用於插入和更新資料的場景,由資料庫惟一索引確保多次插入和更新操作只有一次生效。
-
基於全域性唯一標識token實現,這種方案要注意幾點 : 1、這裡校驗token是否可使用 和 置token為已使用,是一個CAS原子操作,需要確保在一個原子操作中。 2、如果token儲存使用的是Redis,那麼驗證token的CAS操作可以使用原子自增操作incr,如果Redis值大於1則token不可使用,反之可使用。還有一種實現方式是token生成系統將token預先寫入Redis,用刪除操作來校驗token是否被使用,刪除成功代表token未被使用可執行操作。 3、如果token儲存使用的是MySQL,根據token分庫分表和建惟一索引,同時通過insert語句來判斷token是否存在,如果insert失敗則token不可使用,反之可使用。
3、狀態機
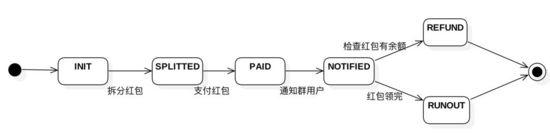
狀態機是表示實體的狀態根據條件轉移的數學模型。通過狀態機模型,系統可以判斷當前不一致狀態,以及如何校正不一致狀態到一致狀態。這樣說可能比較抽象,我們拿發微信群紅包的例子來說明。當你點開發紅包按鈕,輸入總金額、紅包個數、標題,點選支付成功後。其實根據時間先後紅包系統後臺至少經歷過這樣一個狀態機 :
-
1、當輸入總金額、紅包個數、標題點選提交,首先後臺建立一個初始化狀態(INIT)紅包
-
2、接著系統將根據你輸入的總金額和個數n將紅包拆分成n分,此時紅包的狀態為拆分成功(SPLITTED)
-
3、此時紅包後臺會監聽非同步支付訊息,如果支付成功則將紅包置為支付成功(PAID)
-
4、之後紅包系統會通知微信IM系統,傳送訊息通知群裡的使用者,此時紅包狀態為(NOTIFIED)
-
5.1、群裡的使用者把紅包搶光了,紅包狀態被系統置為已搶光(RUNOUT)
-
5.2、還有一種可能,如果群裡都是程式設計師,忙著擼程式碼,沒時間搶紅包,一定時間後紅包自動退款到支付賬號,紅包狀態便為(REFUND)
這只是一個正常業務流程的紅包狀態機,異常情況如拆分失敗、支付失敗、通知失敗、退款失敗等情況也同理存在一個狀態機器。為了方便業務實體狀態回滾和校正,狀態機要儘量設計精簡,轉移到下一個狀態的邊儘可能的只有一條路徑(終結狀態會例外),這樣在回滾和校正時能夠明確前一個狀態和後一個狀態。舉個例子,如果系統發現紅包一直處於PAID狀態,而並沒有流轉到NOTIFIED狀態,能夠判斷是通知群使用者出現異常,可以根據實際情況重新通知群使用者或者將超期紅包退款。
4、恢復日誌
恢復日誌是程式現場的記錄,也是業務資料恢復的重要依據。恢復日誌log要求全域性唯一的requestId來標示請求(實際的業務場景可採用不會重複有含義的業務id),出現異常,可以根據requestId維度redo和undo業務操作,恢復日誌具體可分為三部分 :
-
requestId請求開始時,記錄REQUEST START requestId
-
本地修改時,記錄全部的(requestId,x,originalValue, destValue)四元組,x代表操作物件,修改前x的值為originalValue,本次修改的目的操作值為destValue
-
requestId結束時,記錄REQUEST End requestId
恢復日誌是系統從不一致的狀態恢復到一致狀態的重要資料,丟失恢復日誌,意味著不一致可能無法恢復。為什麼是可能,因為有時可以通過狀態機對不一致的狀態進行恢復。
5、非同步校驗
徹底解決分散式一致性問題,有著名的Paxos演算法,通過該演算法分散式系統自發達成一致性。而在具體的業務場景,完全不需要系統自發的達成共識,我們只要在業務系統外部加上嚴格的業務約束,用來仲裁業務系統的狀態。通過非同步校驗,可以發現分散式系統中的異常狀態,並通過恢復日誌進行指令碼批量恢復或者人工處理恢復,根據校驗的粒度有 :
-
根據業務實體id校驗,使用訊息佇列,將需要校驗業務id投遞給校驗系統,進行非同步校驗。
-
根據時間維度批量校驗,使用非同步排程框架,根據時間粒度批量獲取進行非同步校驗。
此外,並不是所有系統都有可靠訊息佇列和排程服務支撐,業務系統可以增加一個本地業務id校驗回執欄位,校驗系統根據校驗步驟回撥設定校驗回執欄位,並對校驗未通過的資料進行重校驗或者訂正。
總結
分散式最終一致性問題,後端程式設計師在實際開發中經常遇到。在實際系統開發中為了確保最終一致性,往往需要組合多個技術點打出組合拳,因為招數是死的,程式設計師是活的。總結上面提到的技術點,我們可以通過冪等和重試機制,使得不一致資料能夠自動恢復;通過非同步校驗機制發現業務系統的不一致資料;通過狀態機和恢復日誌,糾正不一致的業務資料。最後,感謝閱讀本文,歡迎留言討論。在此我向大家推薦一個架構學習交流裙。交流學習裙號:687810532,裡面會分享一些資深架構師錄製的視訊錄影