
帶你玩轉Visual Studio——帶你理解多位元組編碼與Unicode碼
轉自:http://blog.csdn.net/luoweifu/article/details/49382969
多位元組字元與寬位元組字元
char與wchar_t
我們知道C++基本資料型別中表示字元的有兩種:char、wchar_t。
char叫多位元組字元,一個char佔一個位元組,之所以叫多位元組字元是因為它表示一個字時可能是一個位元組也可能是多個位元組。一個英文字元(如’s’)用一個char(一個位元組)表示,一箇中文漢字(如’中’)用3個char(三個位元組)表示,看下面的例子。
void TestChar()
{
char ch1 = 's' - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
結點如下:
ch1:s
ch2:
str:中
wchar_t被稱為寬字元,一個wchar_t佔2個位元組。之所以叫寬字元是因為所有的字都要用兩個位元組(即一個wchar_t)來表示,不管是英文還是中文。看下面的例子:
void TestWchar_t()
{
wcout.imbue(locale("chs")); // 將wcout的本地化語言設定為中文 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
結果如下:
ch1:s
ch2:中
str:中
str2:中國
說明:
1. 用常量字元給wchar_t變數賦值時,前面要加L。如: wchar_t wch2 = L’中’;
2. 用常量字串給wchar_t陣列賦值時,前面要加L。如: wchar_t wstr2[3] = L”中國”;
3. 如果不加L,對於英文可以正常,但對於非英文(如中文)會出錯。
string與wstring
字元陣列可以表示一個字串,但它是一個定長的字串,我們在使用之前必須知道這個陣列的長度。為方便字串的操作,STL為我們定義好了字串的類string和wstring。大家對string肯定不陌生,但wstring可能就用的少了。
string是普通的多位元組版本,是基於char的,對char陣列進行的一種封裝。
wstring是Unicode版本,是基於wchar_t的,對wchar_t陣列進行的一種封裝。
string 與 wstring的相關轉換:
以下的兩個方法是跨平臺的,可在Windows下使用,也可在Linux下使用。
#include <cstdlib>
#include <string.h>
#include <string>
// wstring => string
std::string WString2String(const std::wstring& ws)
{
std::string strLocale = setlocale(LC_ALL, "");
const wchar_t* wchSrc = ws.c_str();
size_t nDestSize = wcstombs(NULL, wchSrc, 0) + 1;
char *chDest = new char[nDestSize];
memset(chDest,0,nDestSize);
wcstombs(chDest,wchSrc,nDestSize);
std::string strResult = chDest;
delete []chDest;
setlocale(LC_ALL, strLocale.c_str());
return strResult;
}
// string => wstring
std::wstring String2WString(const std::string& s)
{
std::string strLocale = setlocale(LC_ALL, "");
const char* chSrc = s.c_str();
size_t nDestSize = mbstowcs(NULL, chSrc, 0) + 1;
wchar_t* wchDest = new wchar_t[nDestSize];
wmemset(wchDest, 0, nDestSize);
mbstowcs(wchDest,chSrc,nDestSize);
std::wstring wstrResult = wchDest;
delete []wchDest;
setlocale(LC_ALL, strLocale.c_str());
return wstrResult;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
字符集(Charcater Set)與字元編碼(Encoding)
字符集(Charcater Set或Charset):是一個系統支援的所有抽象字元的集合,也就是一系列字元的集合。字元是各種文字和符號的總稱,包括各國家文字、標點符號、圖形符號、數字等。常見的字符集有:ASCII字符集、GB2312字符集(主要用於處理中文漢字)、GBK字符集(主要用於處理中文漢字)、Unicode字符集等。
字元編碼(Character Encoding):是一套法則,使用該法則能夠對自然語言的字元的一個字符集(如字母表或音節表),與計算機能識別的二進位制數字進行配對。即它能在符號集合與數字系統之間建立對應關係,是資訊處理的一項基本技術。通常人們用符號集合(一般情況下就是文字)來表達資訊,而計算機的資訊處理系統則是以二進位制的數字來儲存和處理資訊的。字元編碼就是將符號轉換為計算機能識別的二進位制編碼。
一般一個字符集等同於一個編碼方式,ANSI體系(ANSI是一種字元程式碼,為使計算機支援更多語言,通常使用 0x80~0xFF 範圍的 2 個位元組來表示 1 個字元)的字符集如ASCII、ISO 8859-1、GB2312、GBK等等都是如此。一般我們說一種編碼都是針對某一特定的字符集。
一個字符集上也可以有多種編碼方式,例如UCS字符集(也是Unicode使用的字符集)上有UTF-8、UTF-16、UTF-32等編碼方式。
從計算機字元編碼的發展歷史角度來看,大概經歷了三個階段:
第一個階段:ASCII字符集和ASCII編碼。
計算機剛開始只支援英語(即拉丁字元),其它語言不能夠在計算機上儲存和顯示。ASCII用一個位元組(Byte)的7位(bit)表示一個字元,第一位置0。後來為了表示更多的歐洲常用字元又對ASCII進行了擴充套件,又有了EASCII,EASCII用8位表示一個字元,使它能多表示128個字元,支援了部分西歐字元。
第二個階段:ANSI編碼(本地化)
為使計算機支援更多語言,通常使用 0x80~0xFF 範圍的 2 個位元組來表示 1 個字元。比如:漢字 ‘中’ 在中文作業系統中,使用 [0xD6,0xD0] 這兩個位元組儲存。
不同的國家和地區制定了不同的標準,由此產生了 GB2312, BIG5, JIS 等各自的編碼標準。這些使用 2 個位元組來代表一個字元的各種漢字延伸編碼方式,稱為 ANSI 編碼。在簡體中文系統下,ANSI 編碼代表 GB2312 編碼,在日文作業系統下,ANSI 編碼代表 JIS 編碼。
不同 ANSI 編碼之間互不相容,當資訊在國際間交流時,無法將屬於兩種語言的文字,儲存在同一段 ANSI 編碼的文字中。
第三個階段:UNICODE(國際化)
為了使國際間資訊交流更加方便,國際組織制定了 UNICODE 字符集,為各種語言中的每一個字元設定了統一併且唯一的數字編號,以滿足跨語言、跨平臺進行文字轉換、處理的要求。UNICODE 常見的有三種編碼方式:UTF-8(1個位元組表示)、UTF-16((2個位元組表示))、UTF-32(4個位元組表示)。
我們可以用一個樹狀圖來表示由ASCII發展而來的各個字符集和編碼的分支:
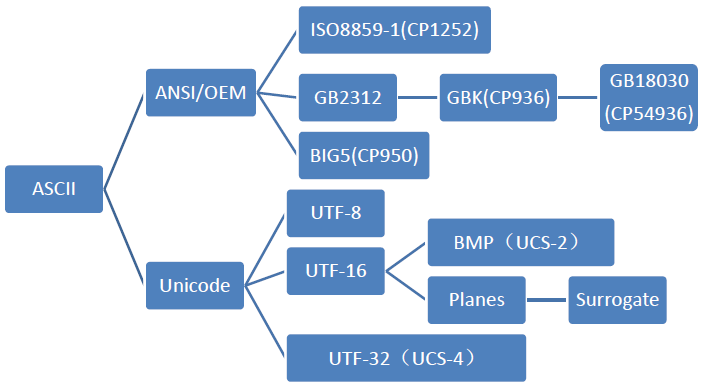
圖 1: 各種型別的編譯
如果要更詳細地瞭解字符集和字元編碼請參考:
字符集和字元編碼(Charset & Encoding)
工程裡多位元組與寬字元的配製
右鍵你的工程名->Properties,設定如下:
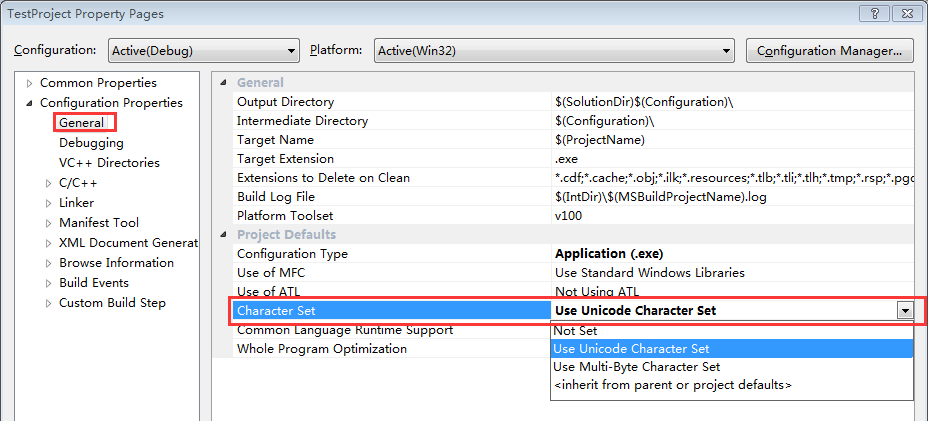
圖 2: Character Set
- 當設定為Use Unicode Character Set時,會有預編譯巨集:_UNICODE、UNICODE
圖 3: Unicode - 當設定為Use Multi-Byte Character Set時,會有預編譯巨集:_MBCS
圖 4: Multi-Byte
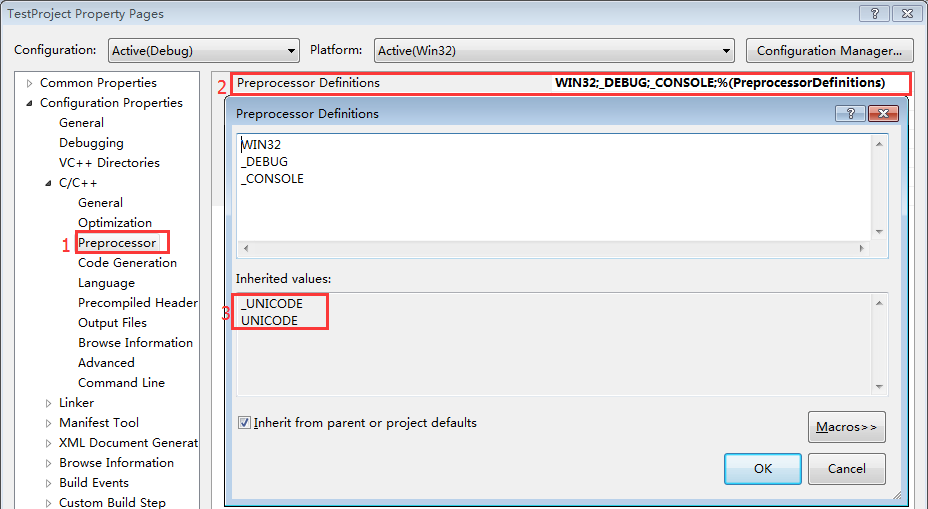
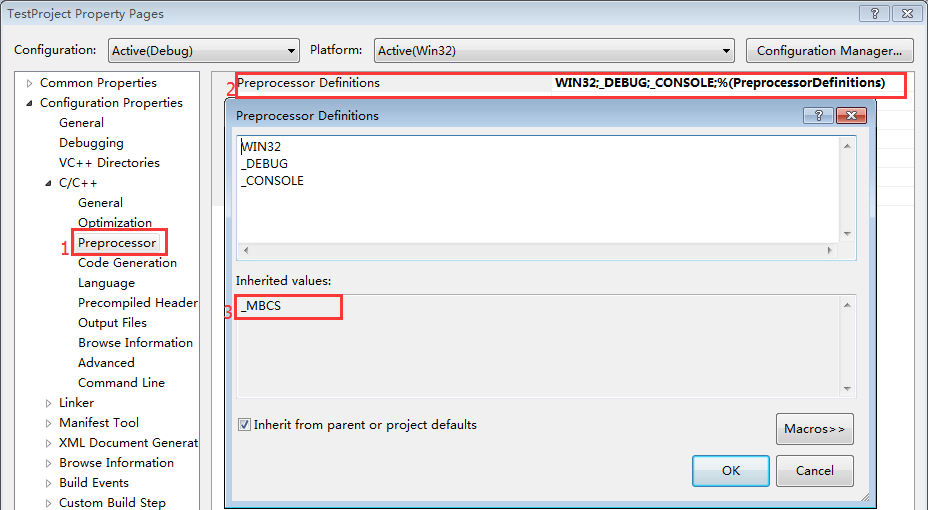
Unicode Character Set與Multi-Byte Character Set有什麼區別呢?
Unicode Character Set和Multi-Byte Character Set這兩個設定有什麼區別呢?我們來看一個例子:
有一個程式需要用MessageBox彈出提示框:
#include "windows.h"
void TestMessageBox()
{
::MessageBox(NULL, "這是一個測試程式!", "Title", MB_OK);
}- 1
- 2
- 3
- 4
- 5
- 6
上面這個Demo非常簡單不用多說了吧!我們將Character Set設定為Multi-Byte Character Set時,可以正常編譯和執行。但當我們設定為Unicode Character Set,則會有以下編譯錯誤:
error C2664: ‘MessageBoxW’ : cannot convert parameter 2 from ‘const char [18]’ to ‘LPCWSTR’
這是因為MessageBox有兩個版本,一個MessageBoxW針對Unicode版的,一個是MessageBoxA針對Multi-Byte的,它們通過不同巨集進行隔開,預設不同的巨集會使用不同的版本。我們使用了Use Unicode Character Set就預設了_UNICODE、UNICODE巨集,所以編譯時就會使用MessageBoxW,這時我們傳入多位元組常量字串肯定會有問題,而應該傳入寬符的字串,即將”Title”改為L”Title”就可以了,”這是一個測試程式!”也一樣。
WINUSERAPI
int
WINAPI
MessageBoxA(
__in_opt HWND hWnd,
__in_opt LPCSTR lpText,
__in_opt LPCSTR lpCaption,
__in UINT uType);
WINUSERAPI
int
WINAPI
MessageBoxW(
__in_opt HWND hWnd,
__in_opt LPCWSTR lpText,
__in_opt LPCWSTR lpCaption,
__in UINT uType);
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
上面的Multi-Byte Character Set一般是指ANSI(多位元組)字符集,關於ANSI請參考第二小節字符集(Charcater Set)與字元編碼(Encoding)。而Unicode Character Set就是Unicode字符集,一般是指UTF-16編碼的Unicode。也就是說每個字元編碼為兩個位元組,兩個位元組可以表示65535個字元,65535個字元可以表示世界上大部分的語言。
一般推薦使用Unicode的方式,因為它可以適應各個國家語言,在進行軟體國際時將會非常便得。除非在對儲存要求非常高的時候,或要相容C的程式碼時,我們才會使用多位元組的方式 。
理解_T()、_Text()巨集即L”“
上一小節對MessageBox的呼叫中除了使用L”Title”外,還可以使用_T(“Title”)和_TEXT(“Title”)。而且你會發現在MFC和Win32程式中會更多地使用_T和_TEXT,那_T、_TEXT和L之間有什麼區別呢?
通過第一小節多位元組字元與寬位元組字元我們知道表示多位元組字元(char)串常量時用一般的雙引號括起來就可以了,如”String test”;而表示寬位元組字元(wchar_t)串常量時要在引號前加L,如L”String test”。
檢視tchar.h標頭檔案的定義我們知道_T和_TEXT的功能是一樣的,是一個預定義的巨集。
#define _T(x) __T(x)
#define _TEXT(x) __T(x)- 1
- 2
我們再看看__T(x)的定義,發現它有兩個:
#ifdef _UNICODE
// ... 省略其它程式碼
#define __T(x) L ## x
// ... 省略其它程式碼
#else /* ndef _UNICODE */
// ... 省略其它程式碼
#define __T(x) x
// ... 省略其它程式碼
#endif /* _UNICODE */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
這下明白了嗎?當我們的工程的Character Set設定為Use Unicode Character Set時_T和_TEXT就會在常量字串前面加L,否則(即Use Multi-Byte Character Set時)就會以一般的字串處理。
Dword、LPSTR、LPWSTR、LPCSTR、LPCWSTR、LPTSTR、LPCTSTR
VC++中還有一些常用的巨集你也許會範糊塗,如Dword、LPSTR、LPWSTR、LPCSTR、LPCWSTR、LPTSTR、LPCTSTR。這裡我們統一總結一下:
常見的巨集:
| 型別 | MBCS | UNICODE |
|---|---|---|
| WCHAR | wchar_t | wchar_t |
| LPSTR | char* | char* |
| LPCSTR | const char* | const char* |
| LPWSTR | wchar_t* | wchar_t* |
| LPCWSTR | const wchar_t* | const wchar_t* |
| TCHAR | char | wchar_t |
| LPTSTR | TCHAR*(或char*) | TCHAR* (或wchar_t*) |
| LPCTSTR | const TCHAR* | const TCHAR* |
相互轉換方法:
LPWSTR->LPTSTR: W2T();
LPTSTR->LPWSTR: T2W();
LPCWSTR->LPCSTR: W2CT();
LPCSTR->LPCWSTR: T2CW();
ANSI->UNICODE: A2W();
UNICODE->ANSI: W2A();
字串函式:
還有一些字串的操作函式,它們也有一 一對應關係:
| MBCS | UNICODE |
|---|---|
| strlen(); | wcslen(); |
| strcpy(); | wcscpy(); |
| strcmp(); | wcscmp(); |
| strcat(); | wcscat(); |
| strchr(); | wcschr(); |
| … | … |
通過這些函式和巨集的命名你也許就發現了一些霍規律,一般帶有字首w(或字尾W)的都是用於寬字元的,而不帶字首w(或帶有後綴A)的一般是用於多位元組字元的。
理解CString產生的原因與工作的機理
CString:動態的TCHAR陣列,是對TCHAR陣列的一種封閉。它是一個完全獨立的類,封裝了“+”等操作符和字串操作方法,換句話說就是CString是對TCHAR操作的方法的集合。它的作用是方便WIN32程式和MFC程式進行字串的處理和型別的轉換。
關於CString更詳細的用法請參考:
CString與string、char*的區別和轉換
CString的常見用法