
spark分割槽數,task數目,core數,worker節點個數,excutor數量梳理
阿新 • • 發佈:2018-11-30
作者:王燚光
連結:https://www.zhihu.com/question/33270495/answer/93424104
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
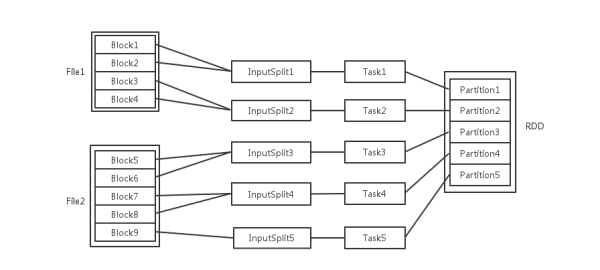
![]() 輸入可能以多個檔案的形式儲存在HDFS上,每個File都包含了很多塊,稱為Block。
當Spark讀取這些檔案作為輸入時,會根據具體資料格式對應的InputFormat進行解析,一般是將若干個Block合併成一個輸入分片,稱為InputSplit,注意InputSplit不能跨越檔案。
輸入可能以多個檔案的形式儲存在HDFS上,每個File都包含了很多塊,稱為Block。
當Spark讀取這些檔案作為輸入時,會根據具體資料格式對應的InputFormat進行解析,一般是將若干個Block合併成一個輸入分片,稱為InputSplit,注意InputSplit不能跨越檔案。
- 每個節點可以起一個或多個Executor。
- 每個Executor由若干core組成,每個Executor的每個core一次只能執行一個Task。
- 每個Task執行的結果就是生成了目標RDD的一個partiton。
- 對於資料讀入階段,例如sc.textFile,輸入檔案被劃分為多少InputSplit就會需要多少初始Task。
- 在Map階段partition數目保持不變。
- 在Reduce階段,RDD的聚合會觸發shuffle操作,聚合後的RDD的partition數目跟具體操作有關,例如repartition操作會聚合成指定分割槽數,還有一些運算元是可配置的。