
ElasticSearch學習筆記之原理介紹
ElasticSearch是一個基於Lucene的搜尋伺服器。它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。Elasticsearch是用Java開發的,並作為Apache許可條款下的開放原始碼釋出,是當前流行的企業級搜尋引擎。設計用於雲端計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用方便。
揭面:

架構圖:
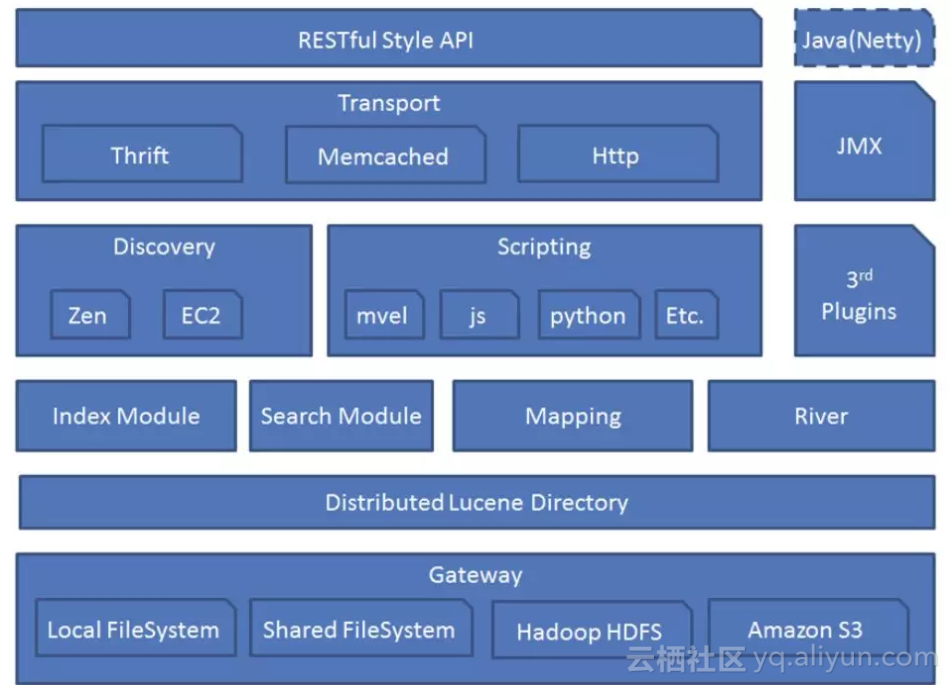
架構各模組介紹:
Lucence Directory:是lucene的框架服務發現以及選主 ZenDiscovery: 用來實現節點自動發現,還有Master節點選取,假如Master出現故障,其它的這個節點會自動選舉,產生一個新的Master;
Plugins:外掛可以通過自定的方式擴充套件加強Elasticsearch的基本功能,比如可以自定義型別對映,分詞器,本地指令碼,自動發現等;
Scripting:使用指令碼語言可以計算自定義表示式的值,比如計算自定義查詢相關度評分。支援的指令碼語言有groovy,js,mvel(1.3.0廢棄),python等;
Disovery:該模組主要負責叢集中節點的自動發現和Master節點的選舉。節點之間使用p2p的方式進行直接通訊,不存在單點故障的問題。Elasticsearch中,Master節點維護叢集的全域性狀態,比如節點加入和離開時進行shard的重新分配;
River:代表es的一個數據源,也是其它儲存方式(如:資料庫)同步資料到es的一個方法。它是以外掛方式存在的一個es服務,通過讀取river中的資料並把它索引到es中;
Gateway:模組用於儲存es叢集的元資料資訊;
Zen Discovery:zen發現機制是elasticsearch預設的內建模組。它提供了多播和單播兩種發現方式,能夠很容易的擴充套件至雲環境。zen發現機制是和其他模組整合的,例如所有節點間通訊必須用trasport模組來完成。
核心概念:
叢集(Cluster):ES叢集是一個或多個節點的集合,它們共同儲存了整個資料集,並提供了聯合索引以及可跨所有節點的搜尋能力。多節點組成的叢集擁有冗餘能力,它可以在一個或幾個節點出現故障時保證服務的整體可用性。
叢集靠其獨有的名稱進行標識,預設名稱為“elasticsearch”。節點靠其叢集名稱來決定加入哪個ES叢集,一個節點只能屬一個叢集;
節點(node):一個節點是一個邏輯上獨立的服務,可以儲存資料,並參與叢集的索引和搜尋功能, 一個節點也有唯一的名字,群集通過節點名稱進行管理和通訊;
主節點:主節點的主要職責是和叢集操作相關的內容,如建立或刪除索引,跟蹤哪些節點是群集的一部分,並決定哪些分片分配給相關的節點。穩定的主節點對叢集的健康是非常重要的。雖然主節點也可以協調節點,路由搜尋和從客戶端新增資料到資料節點,但最好不要使用這些專用的主節點。一個重要的原則是,儘可能做盡量少的工作。
對於大型的生產叢集來說,推薦使用一個專門的主節點來控制叢集,該節點將不處理任何使用者請求。
資料節點:持有資料和倒排索引。
客戶端節點:它既不能保持資料也不能成為主節點,該節點可以響應使用者的情況,把相關操作傳送到其他節點;客戶端節點會將客戶端請求路由到叢集中合適的分片上。對於讀請求來說,協調節點每次會選擇不同的分片處理請求,以實現負載均衡。
部落節點:部落節點可以跨越多個叢集,它可以接收每個叢集的狀態,然後合併成一個全域性叢集的狀態,它可以讀寫所有節點上的資料。
索引(Index): ES將資料儲存於一個或多個索引中,索引是具有類似特性的文件的集合。類比傳統的關係型資料庫領域來說,索引相當於SQL中的一個數據庫,或者一個數據儲存方案(schema)。索引由其名稱(必須為全小寫字元)進行標識,並通過引用此名稱完成文件的建立、搜尋、更新及刪除操作。一個ES叢集中可以按需建立任意數目的索引。
文件型別(Type):型別是索引內部的邏輯分割槽(category/partition),然而其意義完全取決於使用者需求。因此,一個索引內部可定義一個或多個型別(type)。一般來說,型別就是為那些擁有相同的域的文件做的預定義。例如,在索引中,可以定義一個用於儲存使用者資料的型別,一個儲存日誌資料的型別,以及一個儲存評論資料的型別。類比傳統的關係型資料庫領域來說,型別相當於“表”。
文件(Document) :文件是Lucene索引和搜尋的原子單位,它是包含了一個或多個域的容器,基於JSON格式進行表示。文件由一個或多個域組成,每個域擁有一個名字及一個或多個值,有多個值的域通常稱為“多值域”。每個文件可以儲存不同的域集,但同一型別下的文件至應該有某種程度上的相似之處。相當於資料庫的“記錄”
Mapping: 相當於資料庫中的schema,用來約束欄位的型別,不過 Elasticsearch 的 mapping 可以自動根據資料建立。
ES中,所有的文件在儲存之前都要首先進行分析。使用者可根據需要定義如何將文字分割成token、哪些token應該被過濾掉,以及哪些文字需要進行額外處理等等。
分片(shard) :ES的“分片(shard)”機制可將一個索引內部的資料分佈地儲存於多個節點,它通過將一個索引切分為多個底層物理的Lucene索引完成索引資料的分割儲存功能,這每一個物理的Lucene索引稱為一個分片(shard)。
每個分片其內部都是一個全功能且獨立的索引,因此可由叢集中的任何主機儲存。建立索引時,使用者可指定其分片的數量,預設數量為5個。
Shard有兩種型別:primary和replica,即主shard及副本shard。
Primary shard用於文件儲存,每個新的索引會自動建立5個Primary shard,當然此數量可在索引建立之前通過配置自行定義,不過,一旦建立完成,其Primary shard的數量將不可更改。
Replica shard是Primary Shard的副本,用於冗餘資料及提高搜尋效能。
每個Primary shard預設配置了一個Replica shard,但也可以配置多個,且其數量可動態更改。ES會根據需要自動增加或減少這些Replica shard的數量。
ES叢集可由多個節點組成,各Shard分散式地儲存於這些節點上。
ES可自動在節點間按需要移動shard,例如增加節點或節點故障時。簡而言之,分片實現了叢集的分散式儲存,而副本實現了其分散式處理及冗餘功能。
建立索引:

過程:當分片所在的節點接收到來自協調節點的請求後,會將該請求寫入translog,並將文件加入記憶體快取。如果請求在主分片上成功處理,該請求會並行傳送到該分片的副本上。當translog被同步到全部的主分片及其副本上後,客戶端才會收到確認通知。
記憶體緩衝會被週期性重新整理(預設是1秒),內容將被寫到檔案系統快取的一個新段(segment)上。雖然這個段並沒有被同步(fsync),但它是開放的,內容可以被搜尋到。
每30分鐘,或者當translog很大的時候,translog會被清空,檔案系統快取會被同步。這個過程在Elasticsearch中稱為沖洗(flush)。在沖洗過程中,記憶體中的緩衝將被清除,內容被寫入一個新段。段的fsync將建立一個新的提交點,並將內容重新整理到磁碟。舊的translog將被刪除並開始一個新的translog。
ES如何做到實時檢索?
由於在buffer中的索引片先同步到檔案系統快取,再刷寫到磁碟,因此在檢索時可以直接檢索檔案系統快取,保證了實時性。
這一步刷到檔案系統快取的步驟,在 Elasticsearch 中,是預設設定為 1 秒間隔的,對於大多數應用來說,幾乎就相當於是實時可搜尋了。
不過對於 ELK 的日誌場景來說,並不需要如此高的實時性,而是需要更快的寫入效能。我們可以通過 /_settings介面或者定製 template 的方式,加大 refresh_interval 引數。
當segment從檔案系統快取同步到磁碟時發生了錯誤怎麼辦? 資料會不會丟失?
由於Elasticsearch 在把資料寫入到記憶體 buffer 的同時,其實還另外記錄了一個 translog日誌,如果在這期間故障發生時,Elasticsearch會從commit位置開始,恢復整個translog檔案中的記錄,保證資料的一致性。
等到真正把 segment 刷到磁碟,且 commit 檔案進行更新的時候, translog 檔案才清空。這一步,叫做flush。同樣,Elasticsearch 也提供了 /_flush 介面。
索引資料的一致性通過 translog 保證,那麼 translog 檔案自己呢?
Elasticsearch 2.0 以後為了保證不丟失資料,每次 index、bulk、delete、update 完成的時候,一定觸發重新整理translog 到磁碟上,才給請求返回 200 OK。這個改變在提高資料安全性的同時當然也降低了一點效能
檢索文件:

搜尋相關性
相關性是由搜尋結果中Elasticsearch打給每個文件的得分決定的。預設使用的排序演算法是tf/idf(詞頻/逆文件頻率)。詞頻衡量了一個詞項在文件中出現的次數 (頻率越高 == 相關性越高),逆文件頻率衡量了詞項在全部索引中出現的頻率,是一個索引中文件總數的百分比(頻率越高 == 相關性越低)。最後的得分是tf-idf得分與其他因子比如(短語查詢中的)詞項接近度、(模糊查詢中的)詞項相似度等的組合
更新刪除索引:
刪除和更新也都是寫操作。但是Elasticsearch中的文件是不可變的,因此不能被刪除或者改動以展示其變更。那麼,該如何刪除和更新文件呢?
磁碟上的每個段都有一個相應的.del檔案。當刪除請求傳送後,文件並沒有真的被刪除,而是在.del檔案中被標記為刪除。該文件依然能匹配查詢,但是會在結果中被過濾掉。當段合併(我們將在本系列接下來的文章中講到)時,在.del檔案中被標記為刪除的文件將不會被寫入新段。
接下來我們看更新是如何工作的。在新的文件被建立時,Elasticsearch會為該文件指定一個版本號。當執行更新時,舊版本的文件在.del檔案中被標記為刪除,新版本的文件被索引到一個新段。舊版本的文件依然能匹配查詢,但是會在結果中被過濾掉。
物理刪除索引:當索引資料不斷增長時,對應的segment也會不斷的增多,查詢效能可能就會下降。因此,Elasticsearch會觸發segment合併的執行緒,把很多小的segment合併成更大的segment,然後刪除小的segment,當這些標記為刪除的segment不會被複制到新的索引段中。
Elasticseach查詢:
Elasticseach查詢分為兩種,結構化查詢和全文查詢;
儘管統一稱之為query DSL,事實上Elasticsearch中存在兩種DSL:查詢DSL(query DSL)和過濾DSL(filter DSL)。
查詢子句和過濾子句的自然屬性非常相近,但在使用目的上略有區別。
簡單來講,當執行full-text查詢或查詢結果依賴於相關度分值時應該使用查詢DSL,當執行精確值(extac-value)查詢或查詢結果僅有“yes”或“no”兩種結果時應該使用過濾DSL。
Filter DSL計算及過濾速度較快,且適於快取,因此可有效提升後續查詢請求的執行速度。而query DSL不僅要查詢匹配的文件,還需要計算每個檔案的相關度分值,因此為更重量級的查詢,其查詢結果不會被快取。
不過,得益於倒排索引,一個僅返回少量文件的簡單query或許比一個跨數百萬文件的filter執行起來並得顯得更慢。
Elasticsearch支援許多的query和filter,但最常用的也不過幾種。
Filter DSL中常見的有term Filter、terms Filter、range Filter、exists and missing Filters和bool Filter。
而Query DSL中常見的有match_all、match 、multi_match及bool Query。鑑於時間關係,這裡不再細述,朋友們可參考官方文件學習。
Queries用於查詢上下文,而filters用於過濾上下文,不過,Elasticsearch的API也支援此二者合併執行。
組合查詢可用於合併查詢子句,組合過濾用於合併過濾子句,然而,Elasticsearch的使用習慣中,也常會把filter用於query上進行過濾。不過,很少有機會需要把query用於filter上的。
結構化搜尋:是指查詢包含內部結構的資料。日期,時間,和數字都是結構化的:它們有明確的格式給你執行邏輯操作。一般包括比較數字或日期的範圍,或確定兩個值哪個大。
文字也可以被結構化。一包蠟筆有不同的顏色:紅色,綠色,藍色。一篇部落格可能被打上 分散式 和 搜尋的標籤。電子商務產品有商品統一程式碼(UPCs) 或其他有著嚴格格式的標識。
通過結構化搜尋,你的查詢結果始終是 是或非;是否應該屬於集合。結構化搜尋不關心文件的相關性或分數,它只是簡單的包含或排除文件。
這必須是有意義的邏輯,一個數字不能比同一個範圍中的其他數字更多。它只能包含在一個範圍中,或不在其中。類似的,對於結構化文字,一個值必須相等或不等。這裡沒有 更匹配 的概念。
所謂的全文搜尋查詢通常是指在給定的文字域內部搜尋指定的關鍵字,但搜尋操作該需要真正理解查詢者的目的,例如:
(1) 搜尋“UK”應該返回包含“United Kingdom”的相關文件;
(2) 搜尋“jump”應該返回包含“JUMP”、“jumped”、“jumps”、“jumping”甚至是“leap”的文件;
為了完成此類全文搜域的搜尋,ES必須首先分析文字並將其構建成為倒排索引(inverted index),倒排索引由各文件中出現的單詞列表組成,列表中的各單詞不能重複且需要指向其所在的各文件。
因此,為了建立倒排索引,需要先將各文件中域的值切分為獨立的單詞(也稱為term或token),而後將之建立為一個無重複的有序單詞列表。這個過程稱之為“分詞(tokenization)”。
其次,為了完成此類full-text域的搜尋,倒排索引中的資料還需進行“正規化(normalization)”為標準格式,才能評估其與使用者搜尋請求字串的相似度。
這裡的“分詞”及“正規化”操作也稱為“分析(analysis)”。
Analysis過程由兩個步驟的操作組成:首先將文字切分為terms(詞項)以適合構建倒排索引,其次將各terms正規化為標準形式以提升其“可搜尋度”。這兩個步驟由分析器(analyzers)完成。
一個分析器通常需要由三個元件構成:字元過濾器(Character filters)、分詞器(Tokenizer)和分詞過濾器(Token filters)組成。
字元過濾器:在文字被切割之前進行清理操作,例如移除HTML標籤,將&替換為字元等;
分詞器:將文字切分為獨立的詞項;簡單的分詞器通常是根據空白及標點符號進行切分;
分詞過濾器:轉換字元(如將大寫轉為小寫)、移除詞項(如移除a、an、of及the等)或者新增詞項(例如,新增同義詞);
Elasticsearch內建了許多字元過濾器、分詞器和分詞過濾器,使用者可按需將它們組合成“自定義”的分析器。

與SOLR比對:

三種使用方式:
