中文文字的關鍵字提取
阿新 • • 發佈:2018-11-30
基於 TF-IDF 演算法的關鍵詞抽取
import jieba.analyse sentence = "人工智慧(Artificial Intelligence),英文縮寫為AI。它是研究、開發用於模擬、延伸和擴充套件人的智慧的理論、方法、技術及應用系統的一門新的技術科學。人工智慧是電腦科學的一個分支,它企圖瞭解智慧的實質,並生產出一種新的能以人類智慧相似的方式做出反應的智慧機器,該領域的研究包括機器人、語言識別、影象識別、自然語言處理和專家系統等。人工智慧從誕生以來,理論和技術日益成熟,應用領域也不斷擴大,可以設想,未來人工智慧帶來的科技產品,將會是人類智慧的“容器”。人工智慧可以對人的意識、思維的資訊過程的模擬。人工智慧不是人的智慧,但能像人那樣思考、也可能超過人的智慧。人工智慧是一門極富挑戰性的科學,從事這項工作的人必須懂得計算機知識,心理學和哲學。人工智慧是包括十分廣泛的科學,它由不同的領域組成,如機器學習,計算機視覺等等,總的說來,人工智慧研究的一個主要目標是使機器能夠勝任一些通常需要人類智慧才能完成的複雜工作。但不同的時代、不同的人對這種“複雜工作”的理解是不同的。2017年12月,人工智慧入選“2017年度中國媒體十大流行語”。" # sentence:待提取的文字語料; # topK:返回 TF/IDF 權重最大的關鍵詞個數,預設值為 20; # withWeight:是否需要返回關鍵詞權重值,預設值為 False; # allowPOS:僅包括指定詞性的詞,預設值為空,即不篩選。 keywords = " ".join(jieba.analyse.extract_tags(sentence , topK=20, withWeight=False, allowPOS=())) print(keywords) keywords =(jieba.analyse.extract_tags(sentence , topK=10, withWeight=True, allowPOS=(['n','v']))) print(keywords)
基於 TextRank 演算法進行關鍵詞提取
import jieba.analyse sentence = "人工智慧(Artificial Intelligence),英文縮寫為AI。它是研究、開發用於模擬、延伸和擴充套件人的智慧的理論、方法、技術及應用系統的一門新的技術科學。人工智慧是電腦科學的一個分支,它企圖瞭解智慧的實質,並生產出一種新的能以人類智慧相似的方式做出反應的智慧機器,該領域的研究包括機器人、語言識別、影象識別、自然語言處理和專家系統等。人工智慧從誕生以來,理論和技術日益成熟,應用領域也不斷擴大,可以設想,未來人工智慧帶來的科技產品,將會是人類智慧的“容器”。人工智慧可以對人的意識、思維的資訊過程的模擬。人工智慧不是人的智慧,但能像人那樣思考、也可能超過人的智慧。人工智慧是一門極富挑戰性的科學,從事這項工作的人必須懂得計算機知識,心理學和哲學。人工智慧是包括十分廣泛的科學,它由不同的領域組成,如機器學習,計算機視覺等等,總的說來,人工智慧研究的一個主要目標是使機器能夠勝任一些通常需要人類智慧才能完成的複雜工作。但不同的時代、不同的人對這種“複雜工作”的理解是不同的。2017年12月,人工智慧入選“2017年度中國媒體十大流行語”。" result = " ".join(jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))) print(result) # 只需要名詞和動詞 result = " ".join(jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('n','v'))) print(result)
結果:
智慧 人工智慧 機器 人類 研究 技術 模擬 包括 科學 工作 領域 理論 計算機 年度 需要 語言 相似 方式 做出 心理學
智慧 人工智慧 機器 人類 技術 模擬 包括 科學 理論 計算機 領域 年度 需要 心理學 資訊 語言 識別 帶來 過程 延伸
基於 LDA 主題模型進行關鍵詞提取
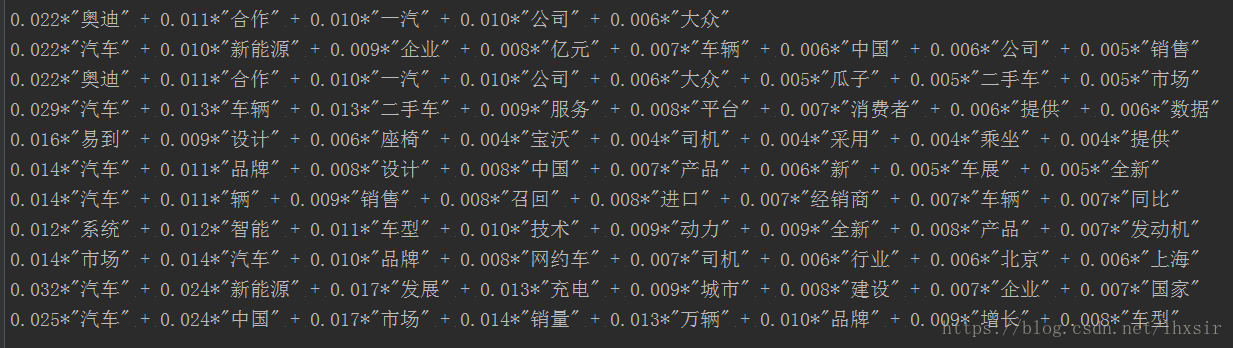
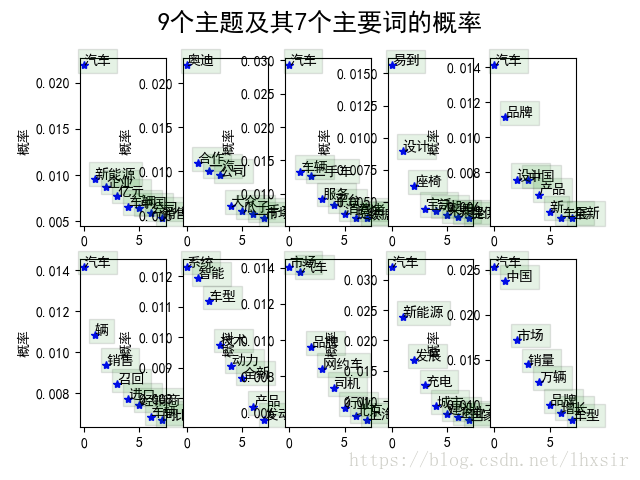
# 引入庫檔案 import jieba.analyse as analyse import jieba import pandas as pd from gensim import corpora, models, similarities import gensim import numpy as np import matplotlib.pyplot as plt # % matplotlib inline # 設定檔案路徑 file_desc = "".join(["D://input_py//day03//",'car.csv']) stop_words = "".join(["D://input_py//day03//",'stopwords.txt']) # 定義停用詞 stopwords=pd.read_csv(stop_words,index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8') stopwords=stopwords['stopword'].values # 載入語料 df = pd.read_csv(file_desc, encoding='utf-8') # 刪除nan行 df.dropna(inplace=True) lines=df.content.values.tolist() # 開始分詞 sentences=[] for line in lines: try: segs=jieba.lcut(line) segs = [v for v in segs if not str(v).isdigit()]#去數字 segs = list(filter(lambda x:x.strip(), segs)) #去左右空格 segs = list(filter(lambda x:x not in stopwords, segs)) #去掉停用詞 sentences.append(segs) except Exception: print(line) continue # 構建詞袋模型 dictionary = corpora.Dictionary(sentences) corpus = [dictionary.doc2bow(sentence) for sentence in sentences] # lda模型,num_topics是主題的個數,這裡定義了5個 lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10) # 我們查一下第1號分類,其中最常出現的5個詞是: print(lda.print_topic(1, topn=5)) # 我們列印所有5個主題,每個主題顯示8個詞 for topic in lda.print_topics(num_topics=10, num_words=8): print(topic[1]) #顯示中文matplotlib plt.rcParams['font.sans-serif'] = [u'SimHei'] plt.rcParams['axes.unicode_minus'] = False # 在視覺化部分,我們首先畫出了九個主題的7個詞的概率分佈圖 num_show_term = 8 # 每個主題下顯示幾個詞 num_topics = 10 for i, k in enumerate(range(num_topics)): ax = plt.subplot(2, 5, i+1) item_dis_all = lda.get_topic_terms(topicid=k) item_dis = np.array(item_dis_all[:num_show_term]) ax.plot(range(num_show_term), item_dis[:, 1], 'b*') item_word_id = item_dis[:, 0].astype(np.int) word = [dictionary.id2token[i] for i in item_word_id] ax.set_ylabel(u"概率") for j in range(num_show_term): ax.text(j, item_dis[j, 1], word[j], bbox=dict(facecolor='green',alpha=0.1)) plt.suptitle(u'9個主題及其7個主要詞的概率', fontsize=18) plt.show()