
摸著石頭過河:知乎核心業務 Go 語言改造實踐
背景
眾所周知,知乎社群後端的主力程式語言是 Python。
隨著知乎使用者的迅速增長和業務複雜度的持續增加,核心業務的流量在過去一年內增長了好幾倍,對應的服務端的壓力也越來越大。隨著業務發展,我們發現 Python 作為動態解釋型語言,較低的執行效率和較高的後期維護成本帶來的問題逐漸暴露出來:
-
執行效率較低。知乎目前機房機櫃空間已經不足,按照目前的使用者和流量增長速度,可預見將在短期內伺服器資源告急(針對這一點,知乎正在由單機房架構升級為異地多活架構);
-
Python 過於靈活的語言特性,導致多人協作和專案維護成本較高。
受益於近些年開源社群的發展和容器等關鍵技術的普及,知乎的基礎平臺技術選型一直較為開放。在開放的標準之上,各個語言都有成熟的開源的中介軟體可供選擇。這使得業務做選型時可以根據問題場景選擇更合適的工具,語言也是一樣。
基於此,為了解決資源佔用問題和動態語言的維護成本問題,我們決定嘗試使用靜態語言對資源佔用極高的核心業務進行重構。
為什麼選擇 Golang
如上所述,知乎在後端技術選型上比較開放。在過去幾年裡,除了 Python 作為主力語言開發,知乎內部也不乏 Java、Golang、NodeJS 和 Rust 等語言開發的專案。
通過 ZAE(Zhihu App Engine) 新建一個應用時,提供了多門語言的支援
Golang 是目前知乎內部討論交流最活躍的程式語言之一,考慮到以下幾點,我們決定嘗試用 Golang 重構內部高併發量的核心業務:
-
天然的併發優勢,特別適合 IO 密集應用
-
知乎內部基礎元件的 Golang 版生態比較完善
-
靜態型別,多人協作開發和維護更加安全可靠
-
構建好後只需一個可執行檔案即可,方便部署
-
學習成本低,且開發效率較 Python 沒有明顯降低
相比另一門也很優秀的待選語言—— Java,Golang 在知乎內部生態環境、部署的方便程度和工程師的興趣上都更勝一籌,最終我們決定,選擇 Golang 作為開發語言。
改造成果
截至目前,知乎社群 member(RPC,高峰數十萬 QPS)、評論(RPC + HTTP)、問答(RPC + HTTP)服務已經全部通過 Golang 重寫。同時因為在 Golang 化過程中我們對 Golang 基礎元件的進一步完善,目前一些新的業務在開發之初就直接選擇了 Golang 來實現,Golang 已經成為知乎內部新專案技術選型的推薦語言之一。
相比改造前,目前得到改進的點有以下:
-
節約了超過 80% 的伺服器資源。由於我們的部署系統採用藍綠部署,所以之前佔用伺服器資源最高的幾個業務會因為容器資源原因無法同時部署,需要排隊依次部署。重構後,伺服器資源得到優化,伺服器資源問題得到了有效解決。
-
多人開發和專案維護成本大幅下降。想必大家維護大型 Python 專案都有經常需要裡三層、外三層確認一個函式的引數型別和返回值。而 Golang 裡,大家都面向介面定義,然後根據介面來實現,這使得編碼過程更加安全,很多 Python 程式碼執行時才能發現的問題可以在編譯時即可發現。
-
完善了內部 Golang 基礎元件。前面提到,知乎內部基礎元件的 Golang 版比較完善,這是我們選擇 Golang 的前提之一。不過,在重構的過程中,我們發現仍有部分基礎元件不夠完善甚至缺少。所以,我們也完善和提供了不少基礎元件,為之後其它專案的 Golang 化改造提供了便利。
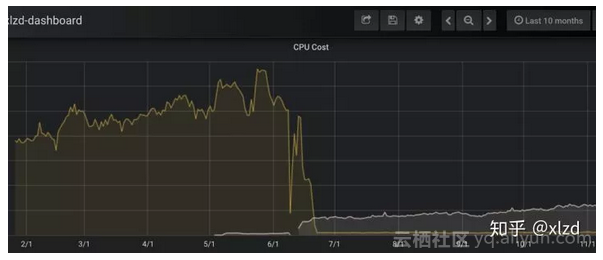
過去 10 個月問答服務的 CPU 核數佔用變化趨勢
實施過程
得益於知乎微服務化比較徹底,每個獨立的微服務想要更換語言非常方便,我們可以方便地對單個業務進行改造,且幾乎可以做到外部依賴方無感知。
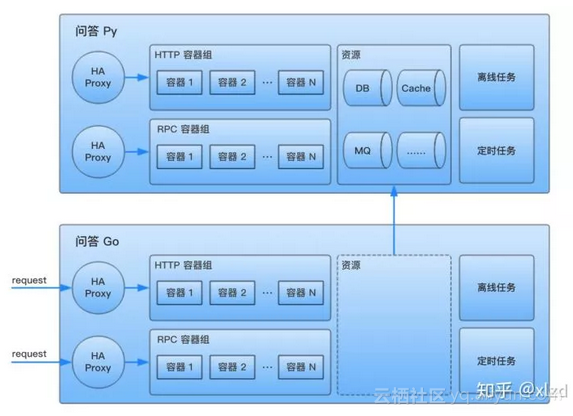
知乎內部,每個獨立的微服務有自己獨立的各種資源,服務間是沒有資源依賴的,全部通過 RPC 請求互動,每個對外提供服務(HTTP or RPC)的容器組,都通過獨立的 HAProxy 地址代理對外提供服務。一個典型的微服務結構如下:
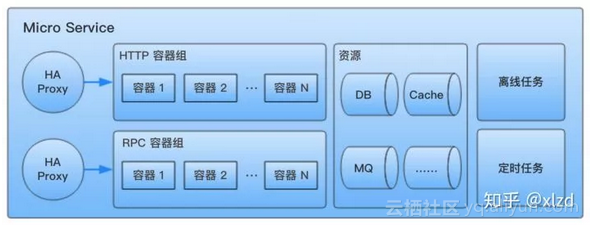
知乎內部一個典型的微服務組成,服務間沒有資源依賴
所以,我們的 Golang 化改造分為了以下幾步:
Step1. 用 Golang 重構邏輯
首先,我們會新起一個微服務,通過 Golang 來重構業務邏輯,但是:
-
新服務對外暴露的協議(HTTP 、RPC 介面定義和返回資料)與之前保持一致(保持協議一致很重要,之後遷移依賴方會更方便)
-
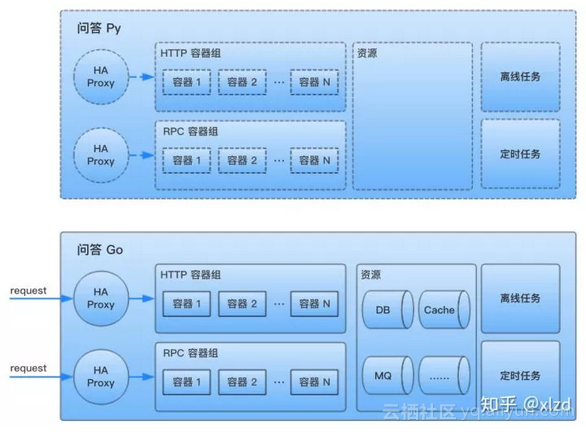
新的服務沒有自己的資源,使用待重構服務的資源:
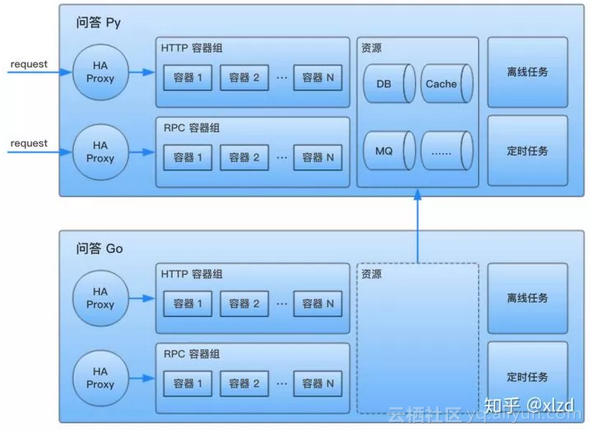
新服務(下)使用待重構服務(上)的資源,短期內資源混用
Step2. 驗證新邏輯正確性
當代碼重構完成後,在將流量切換到新邏輯之前,我們會先驗證新服務的正確性。
針對讀介面,由於其是冪等的,多次呼叫沒有副作用,所以當新版介面實現完成後,我們會在老服務收到請求的同時,起一個協程請求新服務,並對比新老服務的資料是否一致:
-
-
當請求到達老服務後,會立即啟一個協程請求新的服務,與此同時老服務的主邏輯會正常執行。
-
當請求返回後,會比較老服務與新實現的服務返回資料是否相同,如果不同,會打點記錄 + 日誌記錄。
-
工程師根據打點指標和日誌,發現新實現邏輯的錯誤,改正後繼續驗證(其實這一步,我們也發現了不少原本 Python 實現的錯誤)。
-
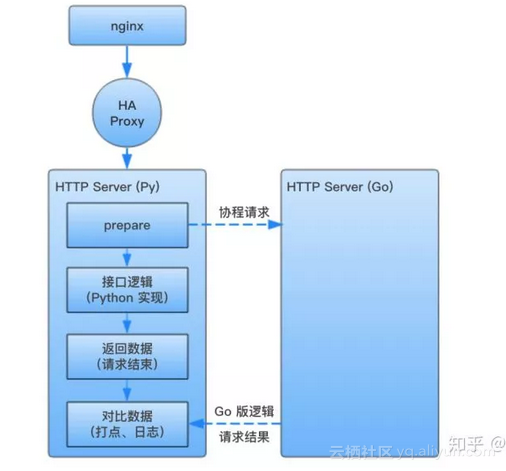
服務請求兩邊資料,並對比結果,但返回老服務的結果
而對於寫介面,大部分並不是冪等的,所以針對寫介面不能像上面這樣驗證。對於寫介面,我們主要會通過以下手段保證新舊邏輯等價:
-
-
單元測試保證
-
開發者驗證
-
QA 驗證
-
Step3. 灰度放量
當一切驗證通過之後,我們會開始按照百分比轉發流量。
此時,請求依然會被代理到老的服務的容器組,但是老服務不再處理請求,而是轉發請求到新服務中,並將新服務返回的資料直接返回。
之所以不直接從流量入口切換,是為了保證穩定性,在出現問題時可以迅速回滾。
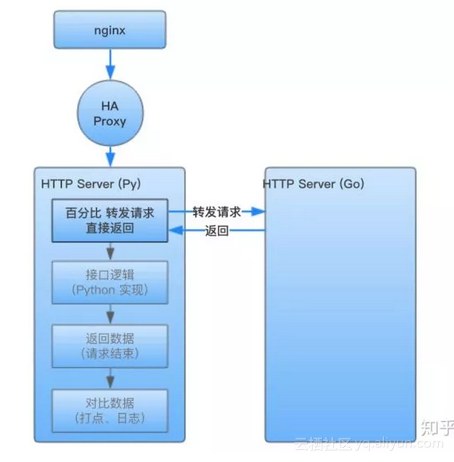
服務請求 Golang 實現
Step4. 切流量入口
當上一步的放量達到 100% 後,請求雖然依然會被代理到老的容器組,但返回的資料已經全部是新服務產生的。此時,我們可以把流量入口直接切換到新服務了。
請求直接打到新的服務,舊服務沒有流量了
Step5. 下線老服務
到這裡重構已經基本接近尾聲了。不過新服務的資源還在老服務中,以及老的沒有流量的服務其實還沒有下線。
到這裡,直接把老服務的資源歸屬調整為新服務,並下線老服務即可。
Goodbye,Python
至此,重構完成。
Golang 專案實踐
在重構的過程中,我們踩了不少坑,這裡摘其中一些與大家分享一下。如果大家有類似重構需求,可簡單參考。
換語言重構的前提是瞭解業務
不要無腦翻譯原來的程式碼,也不要無腦修復原本看似有問題的實現。在重構的初期,我們發現一些看似可以做得更好的點,悶頭一頓修改之後,卻產生了一些奇怪的問題。後面的經驗是,在重構前一定要了解業務,瞭解原本的實現。最好整個重構的過程有對應業務的工程師也參與其中。
專案結構
關於合適的專案結構,其實我們也走過不少彎路。
一開始,我們根據在 Python 中的實踐經驗,層與層之間直接通過函式提供互動介面。但是,迅速發現 Golang 很難像 Python 一樣,方便地通過 monkey patch 完成測試。
經過逐漸演進和參考各種開源專案,目前,我們的程式碼結構大致是這樣:
.
├── bin --> 構建生成的可執行檔案
├── cmd --> 各種服務的 main 函式入口( RPC、Web 等)
│ ├── service
│ │ └── main.go
│ ├── web
│ └── worker
├── gen-go --> 根據 RPC thrift 介面自動生成
├── pkg --> 真正的實現部分(下面詳細介紹)
│ ├── controller
│ ├── dao
│ ├── rpc
│ ├── service
│ └── web
│ ├── controller
│ ├── handler
│ ├── model
│ └── router
├── thrift_files --> thrift 介面定義
│ └── interface.thrift
├── vendor --> 依賴的第三方庫( dep ensure 自動拉取)
├── Gopkg.lock --> 第三方依賴版本控制
├── Gopkg.toml
├── joker.yml --> 應用構建配置
├── Makefile --> 本專案下常用的構建命令
└── README.md分別是:
-
bin:構建生成的可執行檔案,一般線上啟動就是 `bin/xxxx-service`
-
cmd:各種服務(RPC、Web、離線任務等)的 main 函式入口,一般從這裡開始執行
-
gen-go:thrift 編譯自動生成的程式碼,一般會配置 Makefile,直接 `make thrift` 即可生成(這種方式有一個弊端:很難升級 thrift 版本)
-
pkg:真正的業務實現(下面詳細介紹)
-
thrift_files:定義 RPC 介面協議
-
vendor:依賴的第三方庫
其中,pkg 下放置著專案的真正邏輯實現,其結構為:
pkg/
├── controller
│ ├── ctl.go --> 介面
│ ├── impl --> 介面的業務實現
│ │ └── ctl.go
│ └── mock --> 介面的 mock 實現
│ └── mock_ctl.go
├── dao
│ ├── impl
│ └── mock
├── rpc
│ ├── impl
│ └── mock
├── service --> 本專案 RPC 服務介面入口
│ ├── impl
│ └── mock
└── web --> Web 層(提供 HTTP 服務)
├── controller --> Web 層 controller 邏輯
│ ├── impl
│ └── mock
├── handler --> 各種 HTTP 介面實現
├── model -->
├── formatter --> 把 model 轉換成輸出給外部的格式
└── router --> 路由如上結構,值得關注的是我們在每一層之間一般都有 impl、mock 兩個包。
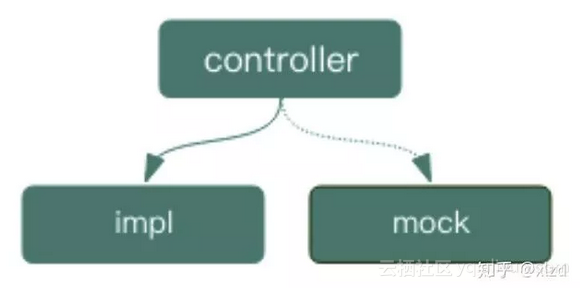
這樣做是因為 Golang 中不能像 Python 那樣方便地動態 mock 掉一個實現,不能方便地測試。我們很看重測試,Golang 實現的測試覆蓋率也保持在 85% 以上。所以我們將層與層之間先抽象出介面(如上 ctl.go),上層對下層的呼叫通過介面約定。在執行的時候,通過依賴注入繫結 impl 中對介面的實現來執行真正的業務邏輯,而測試的時候,繫結 mock 中對介面的實現來達到 mock 下層實現的目的。
同時,為了方便業務開發,我們也實現了一個 Golang 專案的腳手架,通過腳手架可以更方便地直接生成一個包含 HTTP & RPC 入口的 Golang 服務。這個腳手架已經整合到 ZAE(Zhihu App Engine),在創建出 Golang 專案後,預設的模板程式碼就生成好了。對於使用 Golang 開發的新專案,建立好就有了一個開箱即用的框架結構。
靜態程式碼檢查,越早越好
我們在開發的後期才意識到引入靜態程式碼檢查,其實最好的做法是在專案開始時就及時使用,並以較嚴格的標準保證主分支的程式碼質量。
在開發後期才引入的問題是,已經有太多程式碼不符合標準。所以我們不得不短期內忽略了很多檢查項。
很多非常基礎甚至愚蠢的錯誤,人總是無法 100% 避免的,這正是 linter 存在的價值。
實際實踐中,我們使用 gometalinter。gometalinter 本身不做程式碼檢查,而是集成了各種 linter,提供統一的配置和輸出。我們集成了 vet、golint 和 errcheck 三種檢查。
降級
降級的粒度究竟是什麼?這個問題一些工程師的觀點是 RPC 呼叫,而我們的答案是「功能」。
在重構過程中,我們按照「如果這個功能不可用,對使用者的影響該是什麼」的角度,將所有可降級的功能點都做了降級,並對所有降級加上對應的指標點和報警。最終的效果是,如果問答所有的外部 RPC 依賴全部掛了(包括 member 和鑑權這樣的基礎服務),問答本身仍然可以正常瀏覽問題和回答。
我們的降級是在 circuit 的基礎上,封裝指標收集和日誌輸出等功能。Twitch 也在生產環境中使用了這個庫,且我們超過半年的使用中,還沒有遇到什麼問題。
anti-pattern: panic - recover
大部分人開始使用 Golang 開發後,一個非常不習慣的點就是它的錯誤處理。一個簡單的 HTTP 介面實現可能是這樣:
func (h *AnswerHandler) Get(w http.ResponseWriter, r *http.Request) { ctx := r.Context() loginId, err := auth.GetLoginID(ctx) if err != nil { zapi.RenderError(err)---> return } answer, err := h.PrepareAnswer(ctx, r, loginId) if err != nil { zapi.RenderError(err)---> return } formattedAnswer, err := h.ctl.FormatAnswer(ctx, loginId, answer) if err != nil { zapi.RenderError(err)---> return } zapi.RenderJSON(w, formattedAnswer)}如上,每行程式碼後有緊跟著一個錯誤判斷。繁瑣只是其次,主要問題在於,如果錯誤處理後面的 return 語句忘寫,那麼邏輯並不會被阻斷,程式碼會繼續向下執行。在實際開發過程中,我們也確實犯過類似的錯誤。
為此,我們通過一層 middleware,在框架外層將 panic 捕獲,如果 recover 住的是框架定義的錯誤則轉換為對應的 HTTP Error 渲染出去,反之繼續向上層丟擲去。改造後的程式碼成了這樣:
func (h *AnswerHandler) Get(w http.ResponseWriter, r *http.Request) { ctx := r.Context() loginId := auth.MustGetLoginID(ctx) answer := h.MustPrepareAnswer(ctx, r, loginId) formattedAnswer := h.ctl.MustFormatAnswer(ctx, loginId, answer) zapi.RenderJSON(w, formattedAnswer)}如上,業務邏輯中以前 RenderError 並直接緊接著返回的地方,現在再遇到 error 的時候,會直接 panic。這個 panic 會在 HTTP 框架層被捕獲,如果是專案內定義的 HTTPError,則轉換成對應的介面 4xx JSON 格式返回給前端,否則繼續向上丟擲,最終變成一個 5xx 返回前端。
這裡提到這個實現並不是推薦大家這樣做,Golang 官方明確不推薦這樣使用。不過,這確實有效地解決了一些問題,這裡提出來供大家多一種參考。
Goroutine 的啟動
在構建 model 的時候,很多邏輯其實相互之間沒有依賴是可以併發執行的。這時候,啟動多個 goroutine 併發獲取資料可以極大降低響應時間。
不過,剛使用 Golang 的人很容易踩到的一個 goroutine 坑點是,一個 goroutine 如果 panic 了,在它的父 goroutine 是無法 recover 的——嚴格來講,並沒有父子 goroutine 的概念,一旦啟動,就是一個獨立的 goroutine 了。
所以這裡一定要非常注意,如果你新啟動的 goroutine 可能 panic,一定需要本 goroutine 內 recover。當然,更好的方式是做一層封裝,而不是在業務程式碼裸啟動 goroutine。
因此我們參考了 Java 裡面的 Future 功能,做了簡單的封裝。在需要啟動 goroutine 的地方,通過封裝的 Future 來啟動,Future 來處理 panic 等各種狀況。
http.Response Body 沒有 close 導致 goroutine 洩露
一段時間內,我們發現服務 goroutine 數量隨著時間不斷上漲,並會隨著重啟容器立刻掉下來。因此我們猜測程式碼存在 goroutine 洩露。
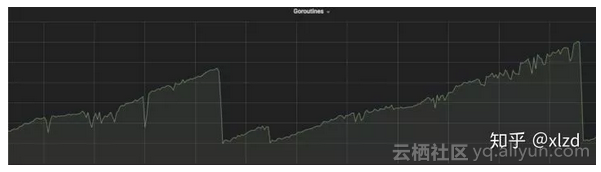
Goroutine 數量隨執行時間逐漸增長,並在重啟後掉下來
通過 goroutine stack 和在依賴庫列印日誌,最終定位到的問題是某個內部的基礎庫使用了 http.Client,但是沒有 `resp.Body.Close()`,導致發生 goroutine 洩露。
這裡的一個經驗教訓是生產環境不要直接用 http.Get,自己生成一個 http client 的例項並設定 timeout 會更好。
修復這個問題後就正常了:
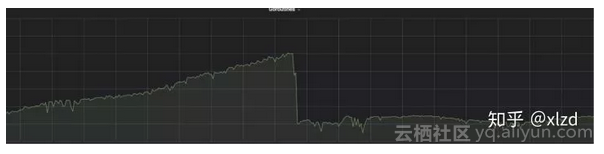
resp.Body.Close()
雖然簡單幾句話介紹了這個問題,但實際定位問題的步驟耗費了我們不少時間,後面可以新起一篇文章專門介紹下 goroutine 洩露的排查過程。
最後
核心業務的 Golang 化重構是由社群業務架構團隊與社群內容技術團隊的同學一起,經過 2018 年 Q2/Q3 的努力達成的目標。以下是兩個團隊的部分成員:
@姚鋼強 @Adam Wen @萬其平 @陳錚 @yetingsky @王志召 @柴小喵 @xlzd
社群業務架構團隊負責解決知乎社群後端的業務複雜度和併發規模快速提升帶來的問題和挑戰。隨著知乎業務規模和使用者的快速增長,以及業務複雜度的持續增加,我們團隊面臨的技術挑戰也越來越大。目前我們正在實施知乎社群的多機房異地多活架構,同時也在努力保障和提升知乎後端的質量和穩定性。
原文釋出時間為: 2018-11-30
本文作者:xlzd
本文來自雲棲社群合作伙伴“ 碼洞”,瞭解相關資訊可以關注“碼洞”。