
第8章:Python計算生態
阿新 • • 發佈:2018-11-30
註明:本系列課程專為全國計算機等級考試二級 Python 語言程式設計考試服務
目錄
考綱考點
- 基本的Python內建函式
- 瞭解Python計算生態
知識導圖
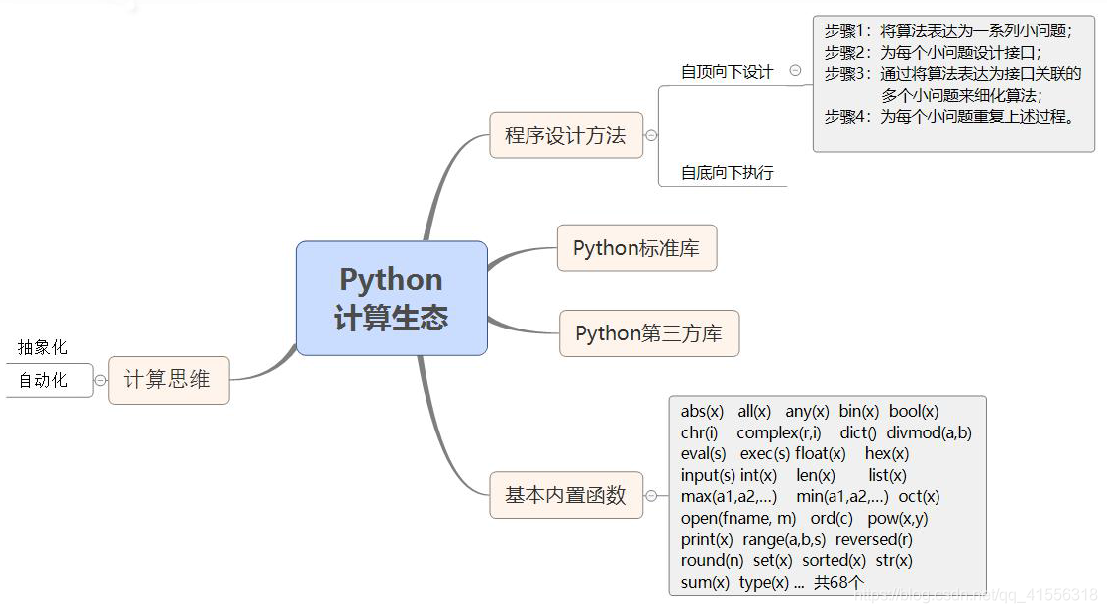
1、計算思維
- 人類在認識世界、改造世界過程中表現出三種基本的思維特徵:以實驗和驗證為特徵的實證思維,以物理學科為代表;以推理和演繹為特徵的邏輯思維,以數學學科為代表;以設計和構造為特徵的計算思維,以計算機學科為代表。
- 計算思維的本質是抽象(Abstraction)和自動化(Automation)
2、程式設計方法論
- 一個解決複雜問題行之有效的方法被稱作自頂而下的設計方法,其基本思想是以一個總問題開始,試圖把它表達為很多小問題組成的解決方案。再用同樣的技術依次攻破每個小問題,最終問題變得非常小,以至於可以很容易解決。然後只需把所有的碎片組合起來,就可以得到一個程式。
“體育競技分析”例項
- 兩個球員在一個有四面邊界的場地上用球拍擊球。開始比賽時,其中一個球員首先發球。接下來球員交替擊球,直到可以判定得分為止,這個過程稱為回合。當一名球員未能進行一次合法擊打時,回合結束。
- 未能打中球的球員輸掉這個回合。如果輸掉這個回合的是發球方,那麼發球權交給另一方;如果輸掉的是接球方,則仍然由這個回合的發球方繼續發球。
- 總之,每回合結束,由贏得該回合的一方發球。球員只能在他們自己的發球局中得分。首先達到15分的球員贏得一局比賽。
自頂向下設計
- 自頂向下設計中最重要的是頂層設計。體育競技分析從使用者處得到模擬引數,最後輸出結果。下面是一個基礎設計:
• 步驟1: 列印程式的介紹性資訊;
• 步驟2:獲得程式執行需要的引數:probA, probB, n;
• 步驟3:利用球員A和B的能力值probA和probB,模擬n次比賽;
• 步驟4:輸出球員A和B獲勝比賽的場次及概率。
- 步驟1 輸出一些介紹資訊,針對提升使用者體驗十分有益。下面是這個步驟的Python程式碼,頂層設計一般不寫出具體程式碼,僅給出函式定義,其中,printIntro()函式列印一些必要的說明。
def main():
printIntro()- 步驟2 獲得使用者輸入。通過函式將輸入語句及輸入格式等細節封裝或隱藏,只需要假設程式如果呼叫了getInputs()函式即可獲取變數probA,probB和n的值。這個函式必須為主程式返回這些值,截止第2步,全部程式碼如下。
def main():
printIntro()
probA, probB, n = getInputs()- 步驟3 需要使用probA、probB模擬n場比賽。此時,可以採用解決步驟2的類似方法,設計一個simNGames()函式來模擬n場比賽
def main():
printIntro()
probA, probB, n = getInputs()
winsA, winsB = simNGames(n, probA, probB)- 步驟4 輸出結果,設計思想類似,仍然只規劃功能和函式,程式碼如下。
def main():
printIntro()
probA, probB, n = getInputs()
winsA, winsB = simNGames(n, probA, probB)
printSummary(winsA, winsB)- 原問題被劃分為了4個獨立的函式:printIntro(),getInputs(),simNGames()和printSummary()。
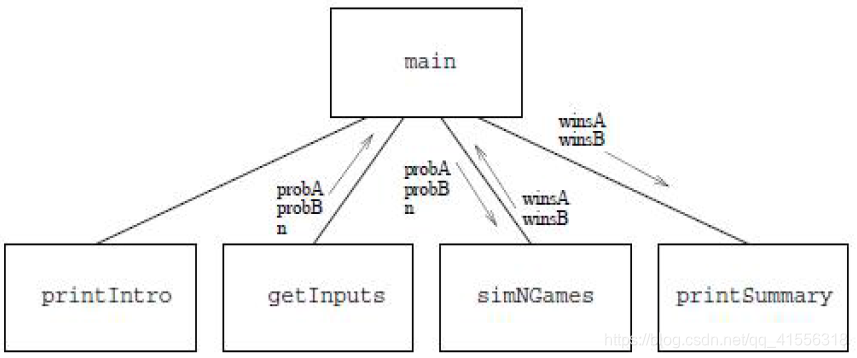
- 每層設計中,引數和返回值如何設計是重點,其他細節可以暫時忽略。確定事件的重要特徵而忽略其它細節過程稱為抽象。抽象是一種基本設計方法,自頂向下的設計過程可以看作是發現功能並抽象功能的過程。
- printIntro()函式應該輸出一個程式介紹,這個功能的Python程式碼如下,這個函式由Python基本表示式組合,不增加或改變程式結構。
def printIntro():
print("這個程式模擬兩個選手A和B的某種競技比賽")
print("程式執行需要A和B的能力值(以0到1之間的小數表示)")- getInputs()函式根據提示得到三個需要返回主程式的值,程式碼如下。
def getInputs():
a = eval(input("請輸入選手A的能力值(0-1): "))
b = eval(input("請輸入選手B的能力值(0-1): "))
n = eval(input("模擬比賽的場次: "))
return a, b, n- simNGames()函式是整個程式的核心,其基本思路是模擬n場比賽,並跟蹤記錄每個球員贏得了多少比賽。
def simNGames(n, probA, probB):
winsA, winsB = 0, 0
for i in range(n):
scoreA, scoreB = simOneGame(probA, probB)
if scoreA > scoreB:
winsA += 1
else:
winsB += 1
return winsA, winsB- 程式碼中設計了simOneGame()函式,用於模擬一場比賽,這個函式需要知道每個球員的概率,返回兩個球員的最終得分

- 接下來需要實現simOneGame()函式。
- 為了模擬一場比賽,需要根據比賽規則來編寫程式碼,兩個球員A和B持續對攻直至比賽結束。可以採用無限迴圈結構直到比賽結束條件成立。同時,需要跟蹤記錄比賽得分,保留髮球局標記,
- 在模擬比賽的迴圈中,需要考慮單一的發球權和比分問題,通過隨機數和概率,可以確定發球方是否贏得了比分(random() < prob)。如果球員A發球,那麼需要使用A的概率,接著根據發球結果,更新球員A得分或是將球權交給球員B。
def simOneGame(probA, probB):
scoreA, scoreB = 0, 0
serving = "A"
while not gameOver(scoreA, scoreB):
if serving == "A":
if random() < probA:
scoreA += 1
else:
serving="B"
else:
if random() < probB:
scoreB += 1
else:
serving="A"
return scoreA, scoreB
- 根據比賽規則,當任意一個球員分數達到15分時比賽結束。gameOver()函式實現程式碼如下。
def gameOver(a,b):
return a==15 or b==15- 最後是printSummary()函式,其Python程式碼如下。
def printSummary(winsA, winsB):
n = winsA + winsB
print("競技分析開始,共模擬{}場比賽".format(n))
print("選手A獲勝{}場比賽,佔比{:0.1%}".format(winsA, winsA/n))
print("選手B獲勝{}場比賽,佔比{:0.1%}".format(winsB, winsB/n))- 將上述所有程式碼放在一起,形成了例項全部程式碼。執行結果如下:
>>>
這個程式模擬兩個選手A和B的某種競技比賽
程式執行需要A和B的能力值(以0到1之間的小數表示)
請輸入選手A的能力值(0-1): 0.45
請輸入選手B的能力值(0-1): 0.5
模擬比賽的場次: 1000
競技分析開始,共模擬1000場比賽
選手A獲勝371場比賽,佔比37.1%
選手B獲勝629場比賽,佔比62.9%- 結合體育競技例項介紹了自頂向下的設計過程。從問題輸入輸出確定開始,整體設計逐漸向下進行。每一層以大體演算法描述開始,然後逐步細化成程式碼,細節被函式封裝
整個過程可以概括為四個步驟:
- 步驟1:將演算法表達為一系列小問題;
- 步驟2:為每個小問題設計介面;
- 步驟3:通過將演算法表達為介面關聯的多個小問題來細化演算法;
- 步驟4:為每個小問題重複上述過程。
3、自底向上執行
- 開展測試的更好辦法也是將程式分成小部分逐個測試
- 執行中等規模程式的最好方法是從結構圖最底層開始,而不是從頂部開始,然後逐步上升。或者說,先執行和測試每一個基本函式,再測試由基礎函式組成的整體函式,這樣有助於定位錯誤
- 可以從gameOver()函式開始測試。Python 直譯器提供import 保留字輔助開展單元測試,語法格式如下:
import <原始檔名稱>
>>>import MatchAnalysis
>>>MatchAnalysis.gameOver(15, 10)
True
>>>MatchAnalysis.gameOver(10, 1)
False- 初步測試說明gameOver()函式是正確的。進一步測試simOneGame()函式,如下:
>>>import e151MatchAnalysis
>>>e151MatchAnalysis.simOneGame(.45, .5)
(9, 15)
>>>e151MatchAnalysis.simOneGame(.45, .5)
(15, 13)- 通過繼續進行這樣的單元測試可以檢測程式中的每個函式。獨立檢驗每個函式更容易發現錯誤。通過模組化設計可以分解問題使編寫複雜程式成為可能,通過單元測試方法分解問題使執行和除錯複雜程式成為可能。
- 自頂向下和自底向上貫穿程式設計和執行的整個過程。
4、計算生態
- 近20年的開源運動產生了深植於各資訊科技領域的大量可重用資源,直接且有力的支撐了資訊科技超越其他技術領域的發展速度,形成了“計算生態”。
- Python語言從誕生之初致力於開源開放,建立了全球最大的程式設計計算生態。
- Python官方網站提供了第三方庫索引功能(PyPI,the Python Package Index),網址如下:
- 該頁面列出了Python語言超過12萬個第三方庫的基本資訊,這些函式庫覆蓋資訊領域技術所有技術方向。
- 由於Python有非常簡單靈活的程式設計方式,很多采用C、C++等語言編寫的專業庫可以經過簡單的介面封裝供Python語言程式呼叫。這樣的粘性功能使得Python語言成為了各類程式語言之間的介面,Python語言也被稱為“膠水語言”。
Python標準庫
- 有一部分Python計算生態隨Python安裝包一起釋出,使用者可以隨時使用,被稱為Python標準庫。
- 受限於Python安裝包的設定大小,標準庫數量270個左右。
Python第三方庫
- 更廣泛的Python計算生態採用額外安裝方式服務使用者,被稱為Python第三方庫。這些第三方庫由全球各行業專家、工程師和愛好者開發,沒有頂層設計,由開發者採用“盡力而為”的方式維護。Python通過新一代安裝工具pip管理大部分Python第三方庫的安裝。
5、基本的Python內建函式
- 官方教材上使用的版本說Python直譯器提供了68個內建函式(下面介紹31個)
- 所有內建函式的詳細介紹以及舉例請查閱 -> Python內建函式查詢
| 函式名稱 | 函式說明 |
| abs(x) | x的絕對值,如果x是複數,返回複數的模 |
| all(x) | 組合型別變數x中所有元素都為真時返回True,否則返回False;若x為空,返回True |
| any(x) | 組合型別變數x中任一元素都為真時返回True,否則返回False;若x為空,返回False |
| bin(x) | 將整數x轉換為等值的二進位制字串,bin(1010)的結果是'0b1111110010' |
| bool(x) | 將x轉換為Boolean型別,即True或False,bool('') 的結果是False |
| chr(i) | 返回Unicode為i的字元,chr(9996)的結果是'✌' |
| complex(r,i) | 建立一個複數 r + i*1j,其中i可以省略,complex(10,10)的結果是10+10j |
| dict() | 建立字典型別,dict()的結果是一個空字典{} |
| divmod(a,b) | 返回a和b的商及餘數,divmod(10,3)結果是一個(3,1) |
| eval(s) | 計算字串s作為Python表示式的值,eval('1+99')的結果是100 |
| exec(s) | 計算字串s作為Python語句的值,exec('a = 1+999')執行後,變數a的值為1000 |
| float(x) | 將x轉換成浮點數,float(1010)的結果是1010.0 |
| hex(x) | 將整數轉換為16進位制字串,hex(1010)的結果是'0x3f2' |
| input(s) | 獲取使用者輸入,其中s是字串,作為提示資訊,s可選 |
| int(x) | 將x轉換成整數,int(9.9)的結果是9 |
| list(x) | 建立或將變數x轉換成一個列表型別,list({10,9,8})的結果是[8,9,10] |
| max(a1,a2,…) | 返回引數的最大值,max(1,2,3,4,5)的結果是5 |
| min(a1,a2,…) | 返回引數的最小值,min(1,2,3,4,5)的結果是1 |
| oct(x) | 將整數x轉換成等值的八進位制字串形式,oct(1010)的結果是'0o1762' |
| open(fname, m) | 開啟檔案,包括文字方式和二進位制方式等,其中,m部分可以省略,預設是以文字可讀形式開啟 |
| ord(c) | 返回一個字元的Unicode編碼值,ord('字')的結果是23383 |
| pow(x,y) | 返回x的y次冪,pow(2,pow(2,2))的結果是16 |
| print(x) | 列印變數或字串x,print()的end引數用來表示輸出的結尾字元 |
| range(a,b,s) | 從a到b(不含)以s為步長產生一個序列,list(range(1,10,3))的結果是[1, 4, 7] |
| reversed(r) | 返回組合型別r的逆序迭代形式,for i in reversed([1,2,3])將逆序遍歷列表 |
| round(n) | 四捨五入方式計算n,round(10.6)的結果是11 |
| set(x) | 將組合資料型別x轉換成集合型別,set([1,1,1,1])的結果是{1} |
| sorted(x) | 對組合資料型別x進行排序,預設從小到大,sorted([1,3,5,2,4])的結果是[1,2,3,4,5] |
| str(x) | 將x轉換為等值的字串型別,str(0x1010)的結果是'4112' |
| sum(x) | 對組合資料型別x計算求和結果,sum([1,3,5,2,4])的結果是15 |
| type(x) | 返回變數x的資料型別,type({1:2})的結果是<class 'dict'> |
6、例項解析:Web頁面元素提取
- Web頁面,一般是HTML頁面,是Internet組織資訊的基礎元素。Web頁面元素提取是一類常見問題,在網路爬蟲、瀏覽器等程式中有著不可或缺的重要作用。
- HTML指超文字標記語言,嚴格來說,HTML不是一種程式語言,而是一種對資訊的標記語言,對Web的內容、格式進行描述。
- 自動地從一個連結獲取HTML頁面是網路爬蟲的功能,本例項功能可以整體分成如下4個步驟:
• 步驟1: 讀取儲存在本地的html檔案;
• 步驟2:解析並提取其中的圖片連結;
• 步驟3:輸出提取結果到螢幕;
• 步驟4:儲存提取結果為檔案。
- 根據上述步驟,可以寫出主程式如下。其中設定了4個函式getHTMLlines()、extractImageUrls()、showResults()和saveResults()分別對應上述4個步驟。
def main():
inputfile = 'nationalgeographic.html'
outputfile = 'nationalgeographic-urls.txt'
htmlLines = getHTMLlines(inputfile)
imageUrls = extractImageUrls(htmlLines)
showResults(imageUrls)
saveResults(outputfile, imageUrls)- 定義main()函式的目的是為了讓程式碼更加清晰,作為主程式,也可以不採用函式形式而直接編寫。main()前兩行分別制定了擬獲取HTML檔案的路徑和結果輸出路徑。
- 主函式設計完成後,逐一編寫各函式功能。
- getHTMLlines()函式讀取HTML檔案並內容,並將結果轉換為一個分行列表,為了相容不同編碼,建議在open()函式中增加encoding欄位,設定採用UTF-8編碼開啟檔案。程式碼如下。
def getHTMLlines(htmlpath):
f = open(htmlpath, "r", encoding='utf-8')
ls = f.readlines()
f.close()
return ls- extractImageUrls()是程式的核心,用於解析檔案並提取影象的URL。觀察HTML可以發現,影象採用img標籤表示,例如:
<img title="photo story"
src="http://image.nationalgeographic.com.cn/2018/0122/20
180122042251164.jpg" width="968px" />
- 其中,<img開頭是影象標籤的特點,其中由src=所引導的URL是這個影象的真實位置。每個URL都以http開頭。因此,可以通過字串操作提取其中的影象連結。
def extractImageUrls(htmllist):
urls = []
for line in htmllist:
if 'img' in line:
url = line.split('src=')[-1].split('"')[1]
if 'http' in url:
urls.append(url)
return urls- showResults()函式將獲取的連結輸出到螢幕上,增加一個計數變數提供更好使用者體驗,程式碼如下。
def showResults(urls):
count = 0
for url in urls:
print('第{:2}個URL:{}'.format(count, url))
count += 1- saveResults()儲存結果到檔案,程式碼如下。
def saveResults(filepath, urls):
f = open(filepath, "w")
for url in urls:
f.write(url+"\n")
f.close()- 各部分函式程式碼編寫後,全部程式碼功能具備,需要額外呼叫main()函式
def getHTMLlines(htmlpath):
f = open(htmlpath, "r", encoding='utf-8')
ls = f.readlines()
f.close()
return ls
def extractImageUrls(htmllist):
urls = []
for line in htmllist:
if 'img' in line:
url = line.split('src=')[-1].split('"')[1]
if 'http' in url:
urls.append(url)
return urls
def showResults(urls):
count = 0
for url in urls:
print('第{:2}個URL:{}'.format(count, url))
count += 1
def saveResults(filepath, urls):
f = open(filepath, "w")
for url in urls:
f.write(url+"\n")
f.close()
def main():
inputfile = 'nationalgeographic.html'
outputfile = 'nationalgeographic-urls.txt'
htmlLines = getHTMLlines(inputfile)
imageUrls = extractImageUrls(htmlLines)
showResults(imageUrls)
saveResults(outputfile, imageUrls)
main()>>>
第 0個URL:http://image.nationalgeographic.com.cn/2018/0122/20180122042251164.jpg
第 1個URL:http://image.nationalgeographic.com.cn/2018/0122/20180122120753804.jpg
第 2個URL:http://image.nationalgeographic.com.cn/2018/0122/20180122102058707.jpg
第 3個URL:http://image.nationalgeographic.com.cn/2018/0118/20180118124326995.jpg
第 4個URL:http://image.nationalgeographic.com.cn/2018/0116/20180116112407593.jpg
第 5個URL:http://image.nationalgeographic.com.cn/2018/0122/20180122035438691.jpg
第 6個URL:http://image.nationalgeographic.com.cn/2018/0118/20180118040311659.jpg
第 7個URL:http://image.nationalgeographic.com.cn/2018/0117/20180117022633730.jpg
第 8個URL:http://image.nationalgeographic.com.cn/2018/0115/20180115024334826.jpg
第 9個URL:http://image.nationalgeographic.com.cn/2018/0112/20180112025424524.png
第10個URL:http://image.nationalgeographic.com.cn/2018/0122/20180122105741158.jpg
#下面省去40個URL本章小結
本章主要講解程式設計方法學,包括計算思維、自頂向下設計和自底向上執行等,進一步本章介紹了計算生態的概念及Python標準庫和第三方庫的劃分。通過Web頁面元素提取的例項幫助讀者理解自頂向下設計的基本方法。
從最基本的IPO到自頂向下設計,是否感受到了函數語言程式設計的優勢?