
spark搭建
阿新 • • 發佈:2018-11-30
參考博文:
https://blog.csdn.net/weixin_42001089/article/details/82346367
Hadoop
在安裝和配置spark之前,先安裝並配置好hadoop,安裝過程請看博主另一篇文章ubuntu18.04搭建hadoop
安裝scala
下載scala-2.11.8.tgz

下載好後解壓:
$ tar -zxvf scala-2.11.8.tgz
移動檔案到/usr/local/scala路徑下:
$ sudo mkdir /usr/local/scala $ sudo mv -v scala-2.11.8.tgz /usr/local/scala

配置scala環境變數
$ sudo gedit /etc/profile
新增:
SCALA_HOME=/usr/local/scala/scala-2.11.12
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$SCALA_HOME/bin
export SCALA_HOME=/usr/local/scala/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
更新環境變數
$ source /etc/profile
測試:

scala安裝成功!
安裝spark
下載地址

下載好後解壓到/usr/local/spark
$ tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
$ sudo mkdir /usr/local/spark
$ sudo mv spark-2.4.0-bin-hadoop2.7.tgz /usr/local/spark

配置spark環境變數
$ sudo vi /etc/profile
新增:
SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7 PATH=$PATH:$HOME/bin:JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin export SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7 export path=$PATH:$SPARK_HOME/bin
更新環境變數:
$ source /etc /profile
配置spark-env.sh
進入路徑:
/usr/local/spark/spark-2.4.0-bin-hadoop2.7/conf
$ sudo cp -v spark-env.sh.template spark-env.sh
sudo vi spark-env.sh
新增以下內容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.2
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.9.2/etc/hadoop
export SCALA_HOME=/usr/local/scala/scala-2.11.12
export SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=3
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=5G
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1G
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
配置Slave
$ cp slaves.template slaves
$ vi slaves

預設為localhost
啟動
在/sbin下啟動start-master.sh和start-slaves.sh
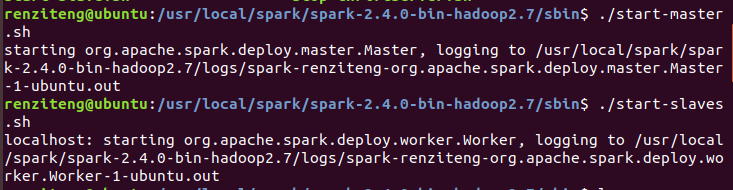
在/bin目錄下啟動spark-shell

這樣就進入scala環境了,可以在這編寫程式碼了。
Spark Web介面 http://127.0.0.1:4040

spark安裝成功!!!