
python學習3(轉載)
主要內容:
列表 和 元組和字典
列表
一、列表介紹
列表是一種能儲存大量資料的資料結構,是能裝物件的物件。由方括號 [] 括起來,能放任意型別的資料,資料之間用逗號隔開
列表儲存資料是有順序的
二、增刪改查
lis = []
1、增加 (三種)
lis.append() 在末尾追加,一次只能加一個
lis.insert(index, 元素) 在指定位置插入元素,這種方法由於會改變列表中其他索引,“牽一髮而動全身”,所以執行效率會低一些
lis.extend(可迭代物件) 迭代新增
2、刪除
lis.pop() “彈出一個” 刪除末尾的元素,並返回刪除的元素值,也可以指定索引刪除指定元素(通過索引刪除)
lis.remove(元素) 移除一個某個元素(通過值刪除元素)
lis.clear() 清空列表
切片刪除
del lis[1:3] # 刪除索引是1,2的元素

索引切片修改
# 修改
lst = ["太白", "太", "五", "銀王", "日天"]
lst[1] = "太汙" # 把1號元素修改成太汙
print(lst)
lst[1:4:3] = ["麻花藤", "哇靠"] # 切片修改也OK. 如果步長不是1, 要注意. 元素的個數
print(lst)
lst[1:4] = ["李嘉誠很厲害"] # 如果切片沒有步長或者步長是1. 則不用關心個數
print(lst)
結果:
['太白', '太汙', '五', '銀王', '日天']
['太白', '麻花藤', '五', '哇靠', '日天']
['太白', '李嘉誠很厲害', '日天']
3、修改
只能根據索引值修改
即
lis[index] = " new"
4、查詢
、根據索引和切片查詢某個或某些元素
lis = ["列","表","與","元組"]
# 迴圈輸出列表中元素
for c in lis :
print(c) # 代表列表中每個元素
# 迴圈輸列表中元素 帶索引
for n in rang(len(lis)):
print(n, lis[n])
、列表迴圈遍歷
三、列表常用功能
lis.count(元素) 統計某個元素在列表出現次數
lis.index(元素) 返回元素的索引 沒有時報錯 ValueError: 5 is not in list
lis.sort() 列表排序,對於純數字元素的列表,從小到大排序(升序)
lis.sort(reverse = True) 從大到小排序(逆序)
注意: 字串不要用這個方法排序,不是不能排,而是用這個方法排完也沒有什麼價值,因為用的是預設的字串比較大小的方式
"xxx".join(lis) 用"xxx"將列表元素連成字串, 和split()功能相反 兩個可以一起記
四、列表巢狀
想要找某個元素是,用降維的方法,一層一層的找,一定要注意每一層對應的是什麼資料
元組
元組由括號()括起來。可以存任意型別資料
元組是不可變資料型別,所以,增刪改查中只有查能進行,所以也被稱為“只讀列表”
對元組不可變性的理解:
它的不可變性體現在元組在建立時第一層元素的記憶體地址就是固定的了,所以如果元素是不可變資料型別,比如字串,那麼是無法對其有修改操作的,但如果元素是可變資料型別,比如列表,是可以對其進行一些修改操作的。參考圖解
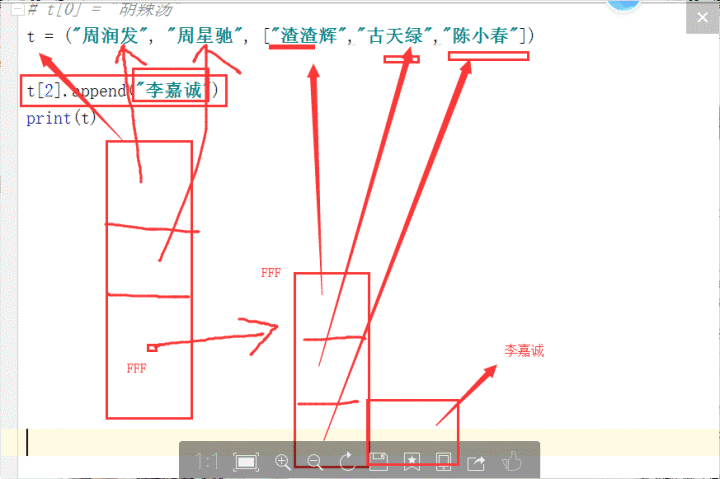
注意坑:元組如果只有一個元素,要加逗號,不然會將括號算作運算子
t1 = (2)
t2 = (2,)
t3 = (1,2,3,)
print(t1) # 2
print(type(t1)) #<class 'int'>
print(t2) #(2,)
print(type(t2)) #<class 'tuple'>
print(t3) #(1,2,3)
print(type(t3) #<class 'tuple'>
code
常用操作:
t = (1,2,2,4,5,"張")
t.index() 查詢指定索引元素 元素不存在時報錯 ValueError: tuple.index(x): x not in tuple
t.count() 統計某個元素出現次數
補充知識:
range()函式
range(n) 遍歷[0,n)的元素
range(m,n) 遍歷[m,n)的元素
range(m,n,p) 從m到n, 每隔p個取一個 p為負數可以倒序遍歷 如range(100,0,-1) 遍歷[100,0)的元素
列表刪除
切片刪除
del lis[1:3] # 刪除索引是1,2的元素
修改

索引切片修改 # 修改 lst = ["太白", "太", "五", "銀王", "日天"] lst[1] = "太汙" # 把1號元素修改成太汙 print(lst) lst[1:4:3] = ["麻花藤", "哇靠"] # 切片修改也OK. 如果步長不是1, 要注意. 元素的個數 print(lst) lst[1:4] = ["李嘉誠個⻳⼉⼦"] # 如果切片沒有步長或者步長是1. 則不用關心個數 print(lst)
字典
字典由花括號表示{ },元素是key:value的鍵值對,元素之間用逗號隔開
特點:1、字典中key是不能重複的 且是不可變的資料型別,因為字典是使用hash演算法來計算key的雜湊值,然後用雜湊值來儲存鍵值對資料
2、字典中元素是無序的
3、value值可以是任意型別的資料
注:字典中的key是可hash的,可hash的資料的都是不可變的資料型別
已知的可雜湊(不可變)的資料型別: int, str, tuple(元組), bool
不可雜湊(可變)的資料型別: list(列表), dict(字典), set(集合)
增刪改查
建立一個空字典---兩種方式:
dic ={}
dic = dict()
新增(兩種方式)
dic[key] = value # 可以新增也可修改已有key的value值
dic.setdefault(key, value) # 如果key是沒有的,新增;如果key已存在 保持原值(這個方法是分兩步的 在查詢會細說)
刪除(四種方式)
pop(key) # 必須指定一個key 刪除指定元素
popitems( ) # 隨機刪除一個值(字典是無序的) 但是在3.6版本里效果是刪除字典最後一個元素--->原因 3.5之前字典列印輸出是無序的,但在3.6之後字典列印輸出是按照元素添 加的順序的,所以感覺用這個方法時是刪除的最後一個元素,但是這個方法的原始碼裡還是隨機刪除的
del dic[key] # 刪除指定元素
dic.clear() # 清空字典
修改(兩種)
dic[key] = new value #賦一個新值
dic.update(dic2) #將dic2更新到dic中
查詢(三種)
dic[key] #查詢指定元素 key不存在時報錯
dic.get(key,[xxx]) # 查詢key的value key不存在時返回xxx,如果不寫xxx,預設返回None
dic.setdefault(key,[value]) # 執行邏輯 第一步,看key是否存在,key存在, 不新增也不修改value;不存在,新增key:value鍵值對,value沒有時預設為None
第二步,返回key對應的value值
常用操作
dic.keys() 返回所有的鍵 返回的是一個可迭代物件,形式像列表但又不是列表
1 dic = {"義大利":"西西里的美麗傳說", "義大利2":"天堂電影院", "美國":'美國往事', "美國電視劇":"越獄"}
2
3 print(dic.keys()) #dict_keys(['義大利', '義大利2', '美國', '美國電視劇'])
4
5 for k in dic.keys(): # 可以迭代。 拿到的是每一個key
6 print(k)
dic.values() 返回所有的值
dic = {"義大利":"西西里的美麗傳說", "義大利2":"天堂電影院", "美國":'美國往事', "美國電視劇":"越獄"}
print(dic.values()) #dict_values(['西西里的美麗傳說', '天堂電影院', '美國往事', '越獄'])
for value in dic.values():
print(value)
dic.items() 返回所有的鍵值對
1 dic = {"義大利":"西西里的美麗傳說", "義大利2":"天堂電影院", "美國":'美國往事', "美國電視劇":"越獄"}
2
3 print(dic.items()) #dict_items([('義大利', '西西里的美麗傳說'), ('義大利2', '天堂電影院'), ('美國', '美國往事'), ('美國電視劇', '越獄')])
4 for k ,v in dic.items():
5 print(k ,v)
6
7 #遍歷字典最好的方案
8 for k, v in dic.items(): # 拿到的是元組(key, value) 這是解包操作
9 print(k,v) #直接拿到key和value