
Python併發程式設計與IO模型
事件驅動
通常,我們寫伺服器處理模型的程式時,有以下幾種模型:- 每收到一個請求,建立一個新的程序,來處理該請求;
- 每收到一個請求,建立一個新的執行緒,來處理該請求;
- 每收到一個請求,放入一個事件列表,讓主程序通過非阻塞I/O方式來處理請求,通常也可以理解為協程模式。
事件驅動模型
1. 有一個事件(訊息)佇列;
2. 滑鼠按下時,往這個佇列中增加一個點選事件(訊息);
3. 有個迴圈,不斷從佇列取出事件,根據不同的事件,呼叫不同的函式,如onClick()、onKeyDown()等;
4. 事件(訊息)一般都各自儲存各自的處理函式指標,這樣,每個訊息都有獨立的處理函式;

事件驅動程式設計是一種程式設計正規化,這裡程式的執行流由外部事件來決定。它的特點是包含一個事件迴圈,當外部事件發生時使用回撥機制來觸發相應的處理。另外兩種常見的程式設計正規化是(單執行緒)同步以及多執行緒程式設計。
用例子來比較和對比一下單執行緒、多執行緒以及事件驅動程式設計模型。下圖展示了隨著時間的推移,這三種模式下程式所做的工作。這個程式有3個任務需要完成,每個任務都在等待I/O操作時阻塞自身。阻塞在I/O操作上所花費的時間已經用灰色框標示出來了。
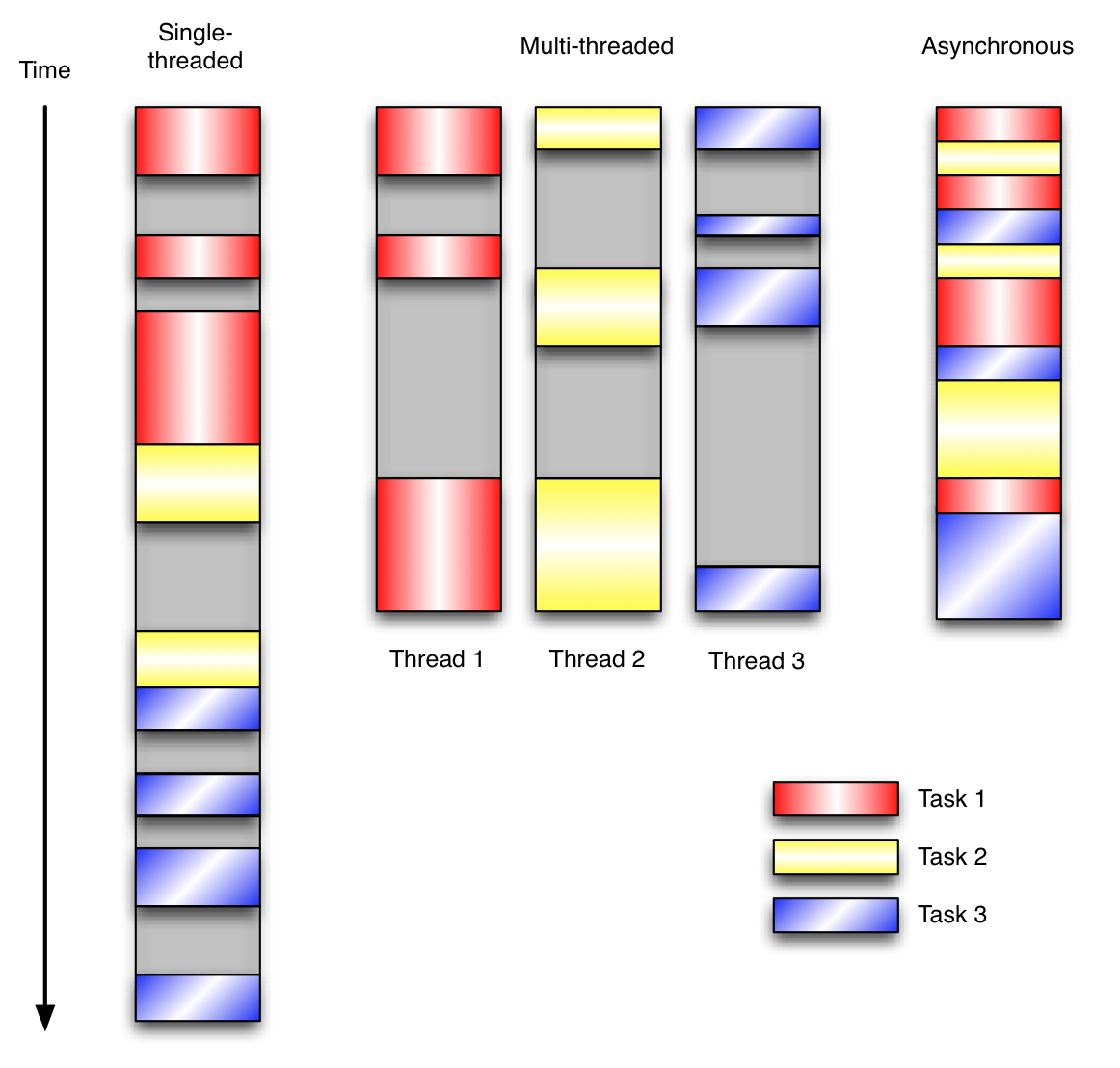
在單執行緒同步模型中,任務按照順序執行。如果某個任務因為I/O而阻塞,其他所有的任務都必須等待,直到它完成之後它們才能依次執行。這種明確的執行順序和序列化處理的行為是很容易推斷得出的。如果任務之間並沒有互相依賴的關係,但仍然需要互相等待的話這就使得程式不必要的降低了執行速度。
在多執行緒版本中,這3個任務分別在獨立的執行緒中執行。這些執行緒由作業系統來管理,在多處理器系統上可以並行處理。這使得當某個執行緒阻塞在某個資源的同時其他執行緒得以繼續執行。與完成類似功能的同步程式相比,這種方式更有效率,但程式設計師必須寫程式碼來保護共享資源,防止其被多個執行緒同時訪問。
在事件驅動版本的程式中,3個任務交錯執行,但仍然在一個單獨的執行緒控制中。當處理I/O操作時,註冊一個回撥函式到事件迴圈中,然後當I/O操作完成時繼續執行。回撥函式描述了該如何處理某個事件。事件迴圈輪詢所有的事件,當事件到來時將它們分配給等待處理事件的回撥函式。這種方式讓程式儘可能的得以執行而不需要用到額外的執行緒。
當我們面對如下的環境時,事件驅動模型通常是一個好的選擇:
- 程式中有許多工。
- 任務之間高度獨立(因此它們不需要互相通訊,或者等待彼此)。
- 在等待事件到來時,某些任務會阻塞。
本文討論的背景是Linux環境下的network IO。
概念說明
使用者空間和核心空間
現在作業系統都是採用虛擬儲存器,那麼對32位作業系統而言,它的定址空間(虛擬儲存空間)為4G(2的32次方)。作業系統的核心是核心,獨立於普通的應用程式,可以訪問受保護的記憶體空間,也有訪問底層硬體裝置的所有許可權。為了保證使用者程序不能直接操作核心(kernel),保證核心的安全,操心繫統將虛擬空間劃分為兩部分,一部分為核心空間,一部分為使用者空間。針對linux作業系統而言,將最高的1G位元組(從虛擬地址0xC0000000到0xFFFFFFFF),供核心使用,稱為核心空間,而將較低的3G位元組(從虛擬地址0x00000000到0xBFFFFFFF),供各個程序使用,稱為使用者空間。程序切換
為了控制程序的執行,核心必須有能力掛起正在CPU上執行的程序,並恢復以前掛起的某個程序的執行。這種行為被稱為程序切換。因此可以說,任何程序都是在作業系統核心的支援下執行的,是與核心緊密相關的。程序阻塞
正在執行的程序,由於期待的某些事件未發生,如請求系統資源失敗、等待某種操作的完成、新資料尚未到達或無新工作做等,則由系統自動執行阻塞原語(Block),使自己由執行狀態變為阻塞狀態。可見,程序的阻塞是程序自身的一種主動行為,也因此只有處於執行態的程序(獲得CPU),才可能將其轉為阻塞狀態。當程序進入阻塞狀態,是不佔用CPU資源的。檔案描述符
檔案描述符(File descriptor)是電腦科學中的一個術語,是一個用於表述指向檔案的引用的抽象化概念。檔案描述符在形式上是一個非負整數。實際上,它是一個索引值,指向核心為每一個程序所維護的該程序開啟檔案的記錄表。當程式開啟一個現有檔案或者建立一個新檔案時,核心向程序返回一個檔案描述符。在程式設計中,一些涉及底層的程式編寫往往會圍繞著檔案描述符展開。但是檔案描述符這一概念往往只適用於UNIX、Linux這樣的作業系統。快取I/O
快取 I/O 又被稱作標準 I/O,大多數檔案系統的預設 I/O 操作都是快取 I/O。在 Linux 的快取 I/O 機制中,作業系統會將 I/O 的資料快取在檔案系統的頁快取中,也就是說, 資料會先被拷貝到作業系統核心的緩衝區中,然後才會從作業系統核心的緩衝區拷貝到應用程式的地址空間。快取 I/O 的缺點:資料在傳輸過程中需要在應用程式地址空間和核心進行多次資料拷貝操作,這些資料拷貝操作所帶來的 CPU 以及記憶體開銷是非常大的。I/O模式
剛才說了,對於一次IO訪問(以read舉例),資料會先被拷貝到作業系統核心的緩衝區中,然後才會從作業系統核心的緩衝區拷貝到應用程式的地址空間。所以說,當一個read操作發生時,它會經歷兩個階段:
1. 等待資料準備 (Waiting for the data to be ready)
2. 將資料從核心拷貝到程序中 (Copying the data from the kernel to the process)
正式因為這兩個階段,linux系統產生了下面五種網路模式的方案。
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路複用( IO multiplexing)
- 訊號驅動 I/O( signal driven IO)
- 非同步 I/O(asynchronous IO)
注:由於signal driven IO在實際中並不常用,所以這隻提及剩下的四種IO Model。
阻塞 I/O(blocking IO)
在linux中,預設情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣:

當用戶程序呼叫了recvfrom這個系統呼叫,kernel就開始了IO的第一個階段:準備資料(對於網路IO來說,很多時候資料在一開始還沒有到達。比如,還沒有收到一個完整的UDP包。這個時候kernel就要等待足夠的資料到來)。這個過程需要等待,也就是說資料被拷貝到作業系統核心的緩衝區中是需要一個過程的。而在使用者程序這邊,整個程序會被阻塞(當然,是程序自己選擇的阻塞)。當kernel一直等到資料準備好了,它就會將資料從kernel中拷貝到使用者記憶體,然後kernel返回結果,使用者程序才解除block的狀態,重新執行起來。
所以,blocking IO的特點就是在IO執行的兩個階段都被block了。
非阻塞 I/O(nonblocking IO)
linux下,可以通過設定socket使其變為non-blocking。當對一個non-blocking socket執行讀操作時,流程是這個樣子:

當用戶程序發出read操作時,如果kernel中的資料還沒有準備好,那麼它並不會block使用者程序,而是立刻返回一個error。從使用者程序角度講 ,它發起一個read操作後,並不需要等待,而是馬上就得到了一個結果。使用者程序判斷結果是一個error時,它就知道資料還沒有準備好,於是它可以再次傳送read操作。一旦kernel中的資料準備好了,並且又再次收到了使用者程序的system call,那麼它馬上就將資料拷貝到了使用者記憶體,然後返回。
所以,nonblocking IO的特點是使用者程序需要不斷的主動詢問kernel資料好了沒有。
I/O 多路複用( IO multiplexing)
IO multiplexing就是我們說的select,poll,epoll,有些地方也稱這種IO方式為event driven IO。select/epoll的好處就在於單個process就可以同時處理多個網路連線的IO。它的基本原理就是select,poll,epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有資料到達了,就通知使用者程序。

當用戶程序呼叫了select,整個程序就會被block,而同時,kernel會“監視”所有select負責的socket,當任何一個socket中的資料準備好了,select就會返回。這個時候使用者程序再呼叫read操作,將資料從kernel拷貝到使用者程序。
所以,I/O 多路複用的特點是通過一種機制一個程序能同時等待多個檔案描述符,而這些檔案描述符(套接字描述符)其中的任意一個進入讀就緒狀態,select()函式就可以返回。
這個圖和blocking IO的圖其實並沒有太大的不同,但是,用select的優勢在於它可以同時處理多個connection。所以,如果處理的連線數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server效能更好,可能延遲還更大。select/epoll的優勢並不是對於單個連線能處理得更快,而是在於能處理更多的連線。在IO multiplexing Model中,實際中,對於每一個socket,一般都設定成為non-blocking,但是,如上圖所示,整個使用者的process其實是一直被block的。只不過process是被select這個函式block,而不是被socket IO給block。
非同步 I/O(asynchronous IO)
Linux下的asynchronous IO其實用得很少。先看一下它的流程:

使用者程序發起read操作之後,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之後,首先它會立刻返回,所以不會對使用者程序產生任何block。然後,kernel會等待資料準備完成,然後將資料拷貝到使用者記憶體,當這一切都完成之後,kernel會給使用者程序傳送一個signal,告訴它read操作完成了。
總結
各個IO Model的比較如圖所示:

通過上面的圖片,可以發現non-blocking IO和asynchronous IO的區別還是很明顯的。在non-blocking IO中,雖然程序大部分時間都不會被block,但是它仍然要求程序去主動的check,並且當資料準備完成以後,也需要程序主動的再次呼叫recvfrom來將資料拷貝到使用者記憶體。而asynchronous IO則完全不同。它就像是使用者程序將整個IO操作交給了他人(kernel)完成,然後他人做完後發訊號通知。在此期間,使用者程序不需要去檢查IO操作的狀態,也不需要主動的去拷貝資料。