
Spring Cloud 資料庫篇----MySQL架構
阿新 • • 發佈:2018-11-30
MySQL資料是關係型資料庫,在不同的OLTP場景中有著很廣泛的應用,使用的方式也是有很多種。從資料庫的業務需求、架構設計、運營維護、遷移擴容,不同的應用場景有著不同的側重點,這些側重點適應於業務的場景或者是解決業務的問題。
首先會從MySQL的架構層面整理,具體的MySQL業務實踐處理後面會繼續提供出來。
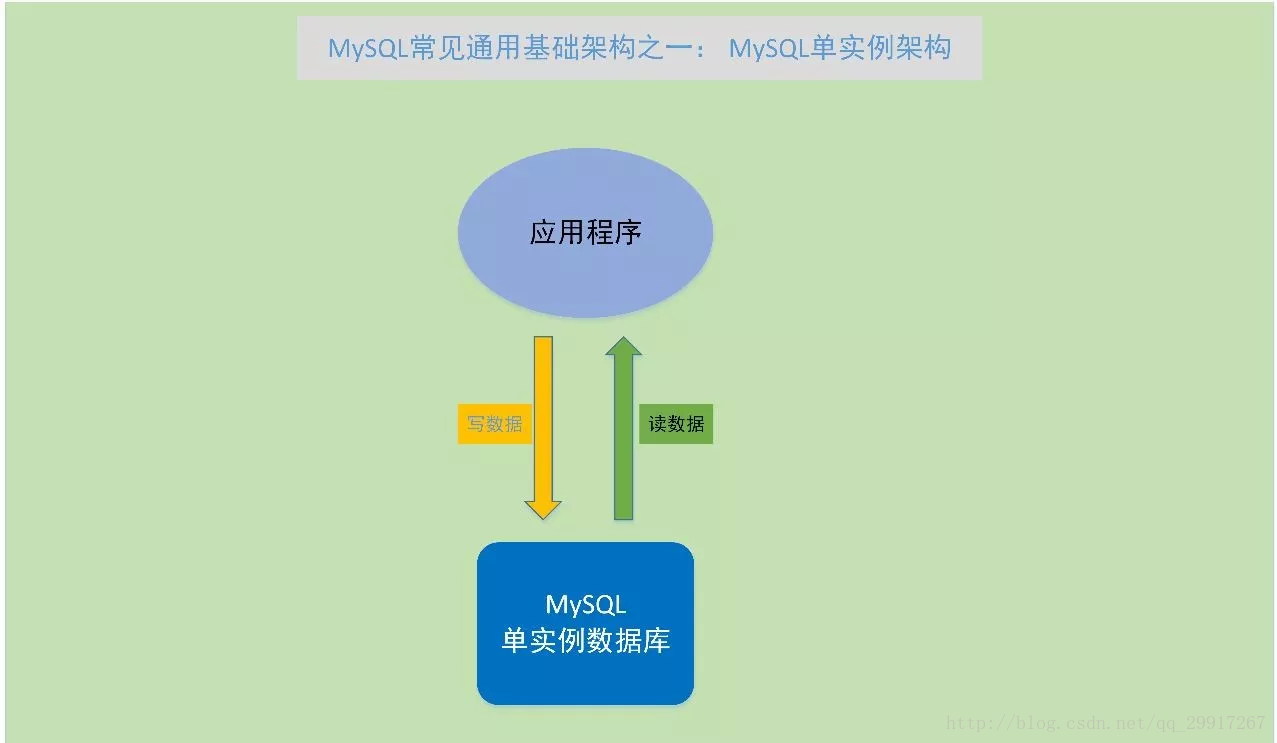
MySQL單例項,就是在伺服器上部署一個MySQL例項來對外提供服務,這是最開始接觸MySQL資料庫會使用的方式,也是常見學習、研究MySQL資料庫的使用方式。
Mysql的單例模式是Mysql使用的第一階段,通常這種情況下Mysql資料可和應用程式在同一個伺服器中。這種方式的好處就是部署和使用簡單,之間通過編譯安裝或者二進位制包解壓安裝,很快可以使用一個Mysql資料庫環境。這種方式依賴性少不需要依賴其他第三方工具或者軟體,維護也比較簡單。 這種方式使用起來比較簡單,只是適合學習和開發環境使用,涉及到業務的使用就要考慮備份和災備。
(2) MySql 主從架構(Master---slave)
MySQL master-slave主從環境,是在MySQL單例項環境的基礎上,將MySQL進行全庫備份,再恢復出一個或多個MySQL例項,通過change master命令,指定新恢復出的MySQL例項,從那個MySQL節點上讀取變化日誌,並在本地應用,使新恢復的例項與原來的MySQL例項資料一致保持一致。所以,原來的資料一致變化的例項,叫master主節點;從master節點獲取日誌,並在本地應用,使資料與master階段保持一致的節點,叫slave從節點;這樣的架構環境,就叫 master-slave主從環境。
Mysql的Master--slave資料庫的架構,可使用線上資料有多份,實現了一定的資料備份功能,提高了資料庫的效能、可用性和擴充套件性。Slave從庫的資料只通過日誌應用日誌變化,一般不會主動更改資料,但是可以對外提供資料讀取功能。Mysql的主從架構可以非常靈活,1個Master節點可以有1個或者多個slave節點;而一個slave節點,也可以當做其他節點的slave節點。如果一個slave節點後面還有其他節點作為這個節點的slave從節點,就叫級聯複製
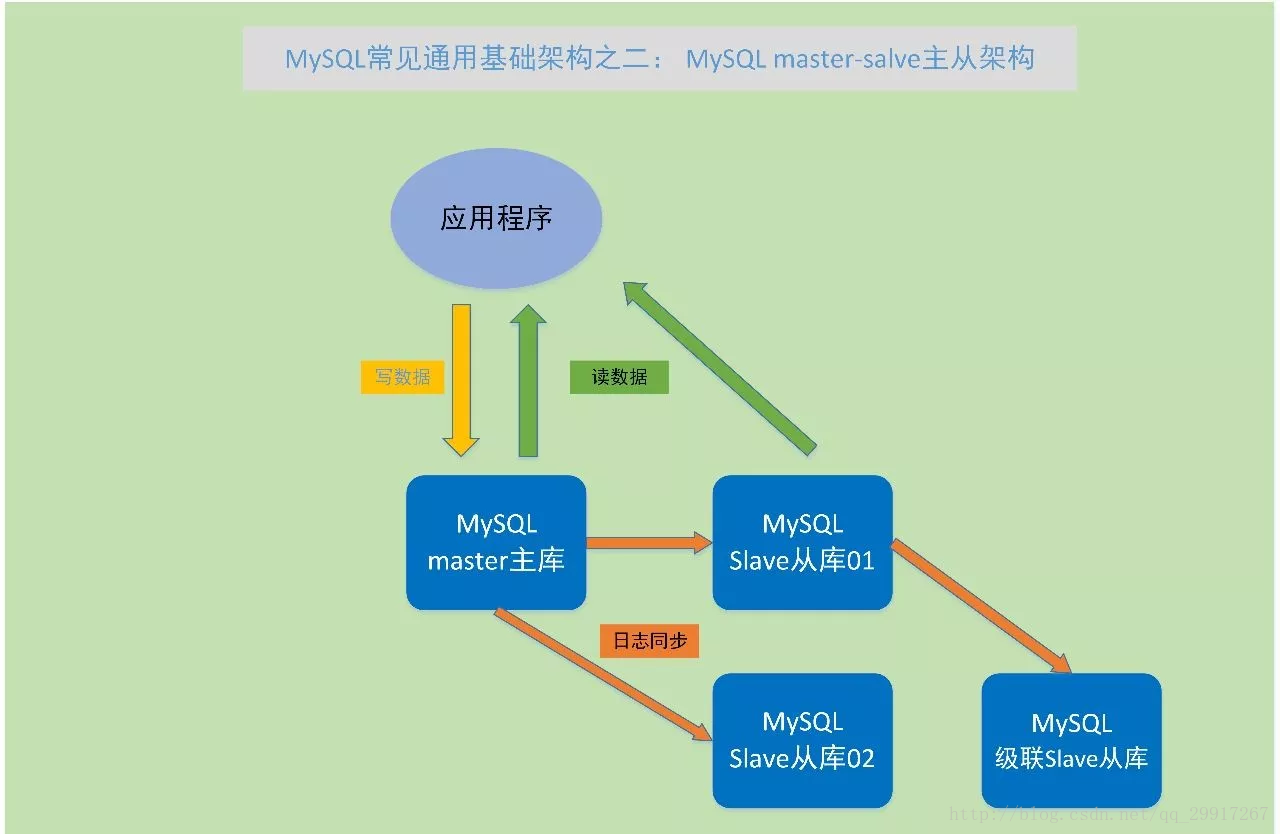
主從架構的拓展:讀寫分離
原理:1個Master配1個或者多個slave,使用的過程中寫、更新、刪除等資料操作全部在Master主資料庫中,讀資料則在slave從資料庫中, 這樣加大了資料的吞吐量,提高了資料操作效率。
常用的讀寫分離元件:Atlas、amoeba、cobar、MaxScale、Mysql-Proxy等
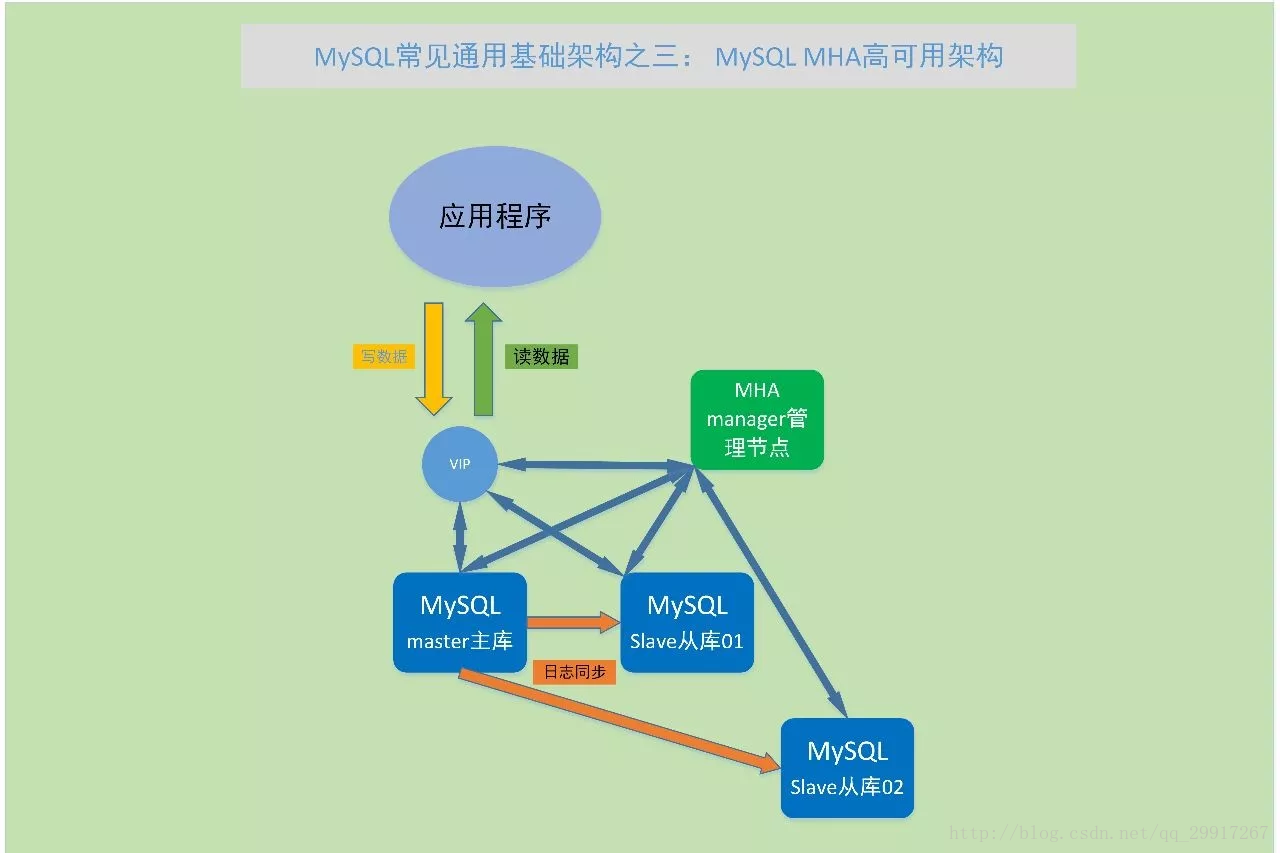
主從架構雖然可以實現資料的多機備份,但是每個資料之間還是獨立分開的。當Master主資料出現故障的時候,整個架構就癱瘓了。因此需要高可用 (內部元件故障仍可用) 的資料庫叢集MHA。
資料庫的高可用MHA建立在主從架構基礎上,Master的固定IP,改為虛擬的VIP。應用通過VIP地址來操作資料庫,當Master資料庫宕機的時候,高可用元件會檢測到宕機故障,這個時候就會找到含有最新binlog位置點的slave,通過中繼日誌將資料恢復到其他的slave,將包含最新binlog位置點的slave提升為master,將其他從庫slave指向新的master原slave01 並開啟主從複製,將儲存下來的binlog恢復到新的master上提供資料庫服務
前三種基礎架構就已經能解決絕大數MySql場景和問題,但是隨著業務需求的變化資料庫的設計也逐漸不能滿足。所以需要在基礎架構上新增特殊業務的架構設計。
場景:如果業務規模進一步擴大,讀寫量級尤其是寫的量級達到非常大的地步,比如每秒資料寫入幾十萬,甚至幾百萬,每天的資料量有幾億甚至幾十億的規模,這樣的讀寫就遠遠不是一個master節點可以支撐的,這時就必須要進行擴充套件了。
一般Mysql 的擴充套件分為:

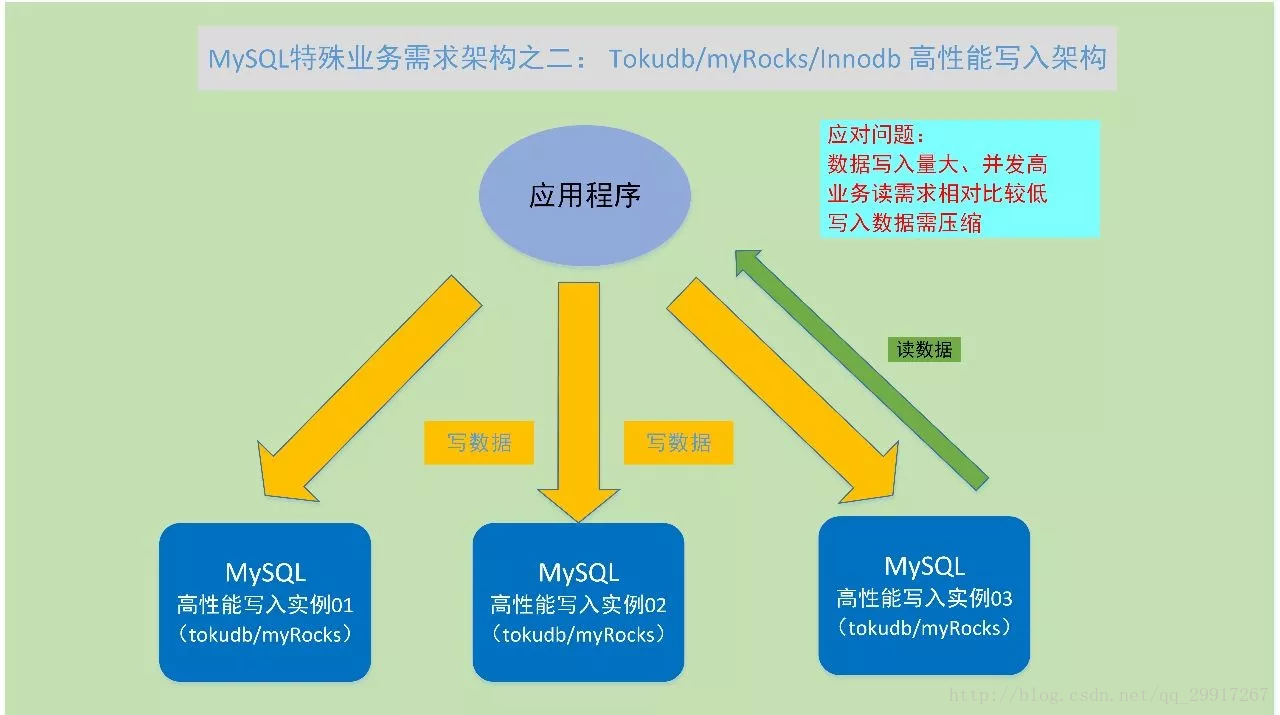
業務資料寫入量非常大,讀取量非常高的情況,一般主要對資料insert寫入效能,同時對資料壓縮效率有特別高的要求。這種特殊的寫入要求,需要對資料寫入有特殊的優化和設計,並且有比較好的壓縮效率和演算法,能夠將寫入的大量資料進行壓縮,節省空間。這種寫入架構, 通常可以看做是MySQL資料庫的一種特殊的儲存引擎
具體到實現而言,MySQL的高效能寫入叢集,可以使用TokuDB儲存引擎。近幾年Facebook也開源了其內部實現的MyRocks,可以作為高效能寫入的儲存引擎。MySQL預設的InnoDB儲存引擎,在新的5.7及以後版本優化後,寫入效能和壓縮效能也有了更高的效能,也可以作為資料寫入的一種選擇。
場景:MySQL資料庫水平拆分,可以對於大資料量的讀寫進行線性擴充套件,但相應地底層伺服器數量也需要比較多;但對於資料寫入量非常大,資料讀很少,資料總量大的情況,使用高效能寫入架構,會更合適一些。
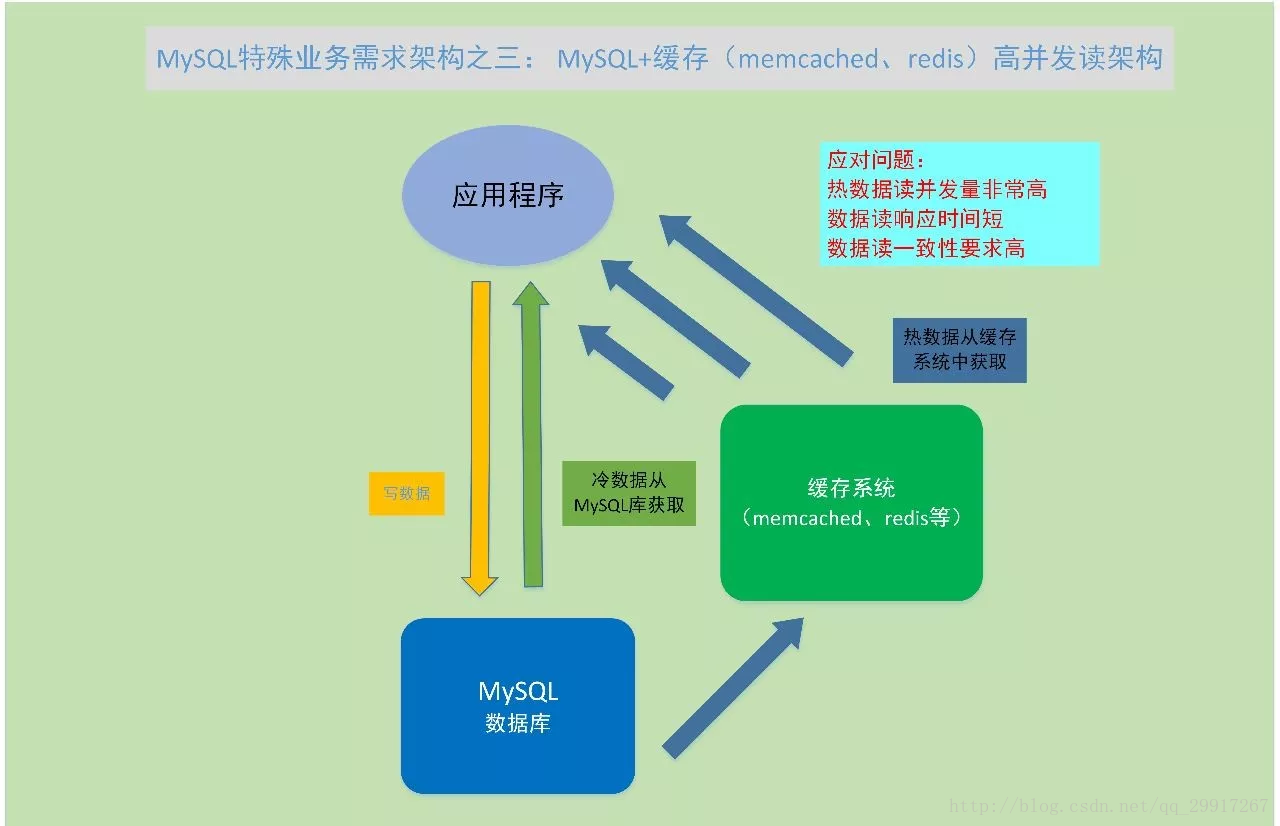
資料庫快取框架,適用於將少量的熱資料放到記憶體中以此來提高訪問的效率。因為從記憶體中的讀取速度,遠大於IO讀取資料,cpu的消耗也會少很多。在業務場景中,使用者請求資料,先在快取中讀取資料,魂村中有資料就直接響應。沒有資料,則去資料庫中獲取資料,並將資料提交到快取,以供下次訪問。
快取系統常用的技術架構有Memcached 和Redis。Memcached是比較經典的快取系統,在之前常與LAMP、LNMP流行架構結合使用。Redis是幾年新興的Key-Value鍵值型NoSQL資料庫,除了作為快取,還可以持久化作為Key-Value資料庫使用。
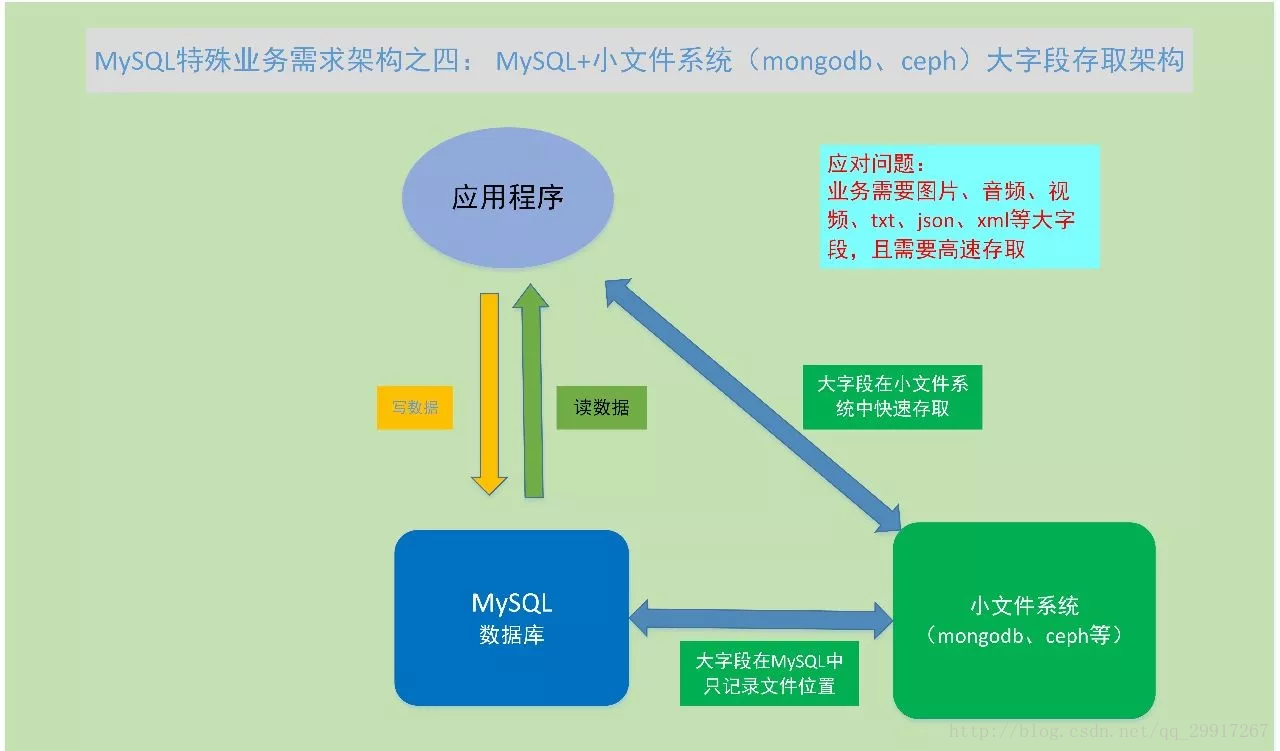
場景:在MySQL資料庫中,通常是儲存符合關係型資料庫原理的小欄位,比如數值型、字元型資料;但在實際環境中,除了這些常用欄位,還會有一些大欄位,比如使用者頭像這種圖片檔案、上傳的音訊、視訊檔案、帖子內容等大text欄位,另外還有一些JSON檔案、XML檔案等,這些可以以二進位制形式儲存在MySQL資料庫中,但讀取和管理都會比較麻煩。這時,就可以使用小檔案系統來結合MySQL來使用。
小檔案系統,是可以儲存並快速訪問結構化資料的系統。對於圖片、音訊、視訊、TXT檔案、JSON檔案、XML檔案等大欄位,一般就只有簡單的讀寫操作,將這些欄位存入到小檔案系統中,並將對應的訪問連結存入到MySQL資料庫的表中。這樣通過資料庫表,可以快速讀寫檔案位置資訊,在小檔案系統中,通過檔案位置資訊,可以實現對大欄位的快速讀寫訪問。
具體實現而言,小檔案系統也有很多技術軟體,比較常見的有MongoDB文件型NoSQL資料庫、Ceph分散式小檔案系統等。
場景:在MySQL資料庫上實時響應業務需要的查詢,通常是指OLTP業務,但對於已經產生的資料,場景:通常會在第二天之後,有結果彙總和統計分析需求。這類OLAP需求通常執行頻率較低,但每次執行消耗的資源很大,如果與OLTP一樣在一個系統上執行,就會造成這兩大類業務的相互影響。這時就可以使用MySQL資料庫與OLAP統計業務分類結合的架構。
MySQL產生了業務資料後,通常需要在第二天,要對前一天的資料進行各個角度、各個維度的統計、聚合、分析,以體現和反映業務的運營情況。這是讓MySQL支援線上OLTP業務,通過資料流轉程式,將每天產生的資料流轉到離線的資料倉庫系統中,在資料倉庫系統中,進行各種資料統計分析、結果彙總,並將資料統計結果再流轉到結果展示庫中。這樣就可以很好地實現線上OLTP和線下OLAP的結合使用和執行。
具體實現而言,對於MySQL資料庫可以結合的OLAP資料倉庫架構,可以選用Inforbright資料倉庫,也可以選用 Greenplum分散式MPP資料庫倉庫。相對而言,Inforbright資料倉庫比較輕量級,與MySQL使用類似;Greenplum分散式MPP資料倉庫可以支撐海量資料的統計分析,功能、效能、容量等也比Inforbright要更強一下,成本也更大一些。

總結
業務的開發,在MySQL的架構設計上來說,上面所述的是固定的架構,能應對一些普遍的業務,但是不要為了架構了而去強行的使用某些技術,按照自己的業務特性去設計會更好。 下面可以推薦一些架構的組合:
MySQL+MHA高可用架構 、MySQL分散式Proxy水平擴充套件架構、 MySQL快取高併發讀架構、 MySQL小檔案系統大欄位存取架構、MySQL Inforbright/Greenplum統計分析架構。

一 、Mysql基礎架構
(1)MySql單例架構
MySQL單例項,就是在伺服器上部署一個MySQL例項來對外提供服務,這是最開始接觸MySQL資料庫會使用的方式,也是常見學習、研究MySQL資料庫的使用方式。
Mysql的單例模式是Mysql使用的第一階段,通常這種情況下Mysql資料可和應用程式在同一個伺服器中。這種方式的好處就是部署和使用簡單,之間通過編譯安裝或者二進位制包解壓安裝,很快可以使用一個Mysql資料庫環境。這種方式依賴性少不需要依賴其他第三方工具或者軟體,維護也比較簡單。 這種方式使用起來比較簡單,只是適合學習和開發環境使用,涉及到業務的使用就要考慮備份和災備。
(2) MySql 主從架構(Master---slave)
MySQL master-slave主從環境,是在MySQL單例項環境的基礎上,將MySQL進行全庫備份,再恢復出一個或多個MySQL例項,通過change master命令,指定新恢復出的MySQL例項,從那個MySQL節點上讀取變化日誌,並在本地應用,使新恢復的例項與原來的MySQL例項資料一致保持一致。所以,原來的資料一致變化的例項,叫master主節點;從master節點獲取日誌,並在本地應用,使資料與master階段保持一致的節點,叫slave從節點;這樣的架構環境,就叫 master-slave主從環境。Mysql的Master--slave資料庫的架構,可使用線上資料有多份,實現了一定的資料備份功能,提高了資料庫的效能、可用性和擴充套件性。Slave從庫的資料只通過日誌應用日誌變化,一般不會主動更改資料,但是可以對外提供資料讀取功能。Mysql的主從架構可以非常靈活,1個Master節點可以有1個或者多個slave節點;而一個slave節點,也可以當做其他節點的slave節點。如果一個slave節點後面還有其他節點作為這個節點的slave從節點,就叫級聯複製
主從架構的拓展:讀寫分離
原理:1個Master配1個或者多個slave,使用的過程中寫、更新、刪除等資料操作全部在Master主資料庫中,讀資料則在slave從資料庫中, 這樣加大了資料的吞吐量,提高了資料操作效率。
常用的讀寫分離元件:Atlas、amoeba、cobar、MaxScale、Mysql-Proxy等
(3)Mysql MHA高可用架構
主從架構雖然可以實現資料的多機備份,但是每個資料之間還是獨立分開的。當Master主資料出現故障的時候,整個架構就癱瘓了。因此需要高可用 (內部元件故障仍可用) 的資料庫叢集MHA。
資料庫的高可用MHA建立在主從架構基礎上,Master的固定IP,改為虛擬的VIP。應用通過VIP地址來操作資料庫,當Master資料庫宕機的時候,高可用元件會檢測到宕機故障,這個時候就會找到含有最新binlog位置點的slave,通過中繼日誌將資料恢復到其他的slave,將包含最新binlog位置點的slave提升為master,將其他從庫slave指向新的master原slave01 並開啟主從複製,將儲存下來的binlog恢復到新的master上提供資料庫服務
二、業務需求架構
前三種基礎架構就已經能解決絕大數MySql場景和問題,但是隨著業務需求的變化資料庫的設計也逐漸不能滿足。所以需要在基礎架構上新增特殊業務的架構設計。
(1)MySQL+分散式Proxy 水平擴充套件
場景:如果業務規模進一步擴大,讀寫量級尤其是寫的量級達到非常大的地步,比如每秒資料寫入幾十萬,甚至幾百萬,每天的資料量有幾億甚至幾十億的規模,這樣的讀寫就遠遠不是一個master節點可以支撐的,這時就必須要進行擴充套件了。
一般Mysql 的擴充套件分為:
- 橫向擴充套件(水平擴充套件) 不修改資料庫的庫表結構,而是對整體資料拆分不同分片,用更多的分片支撐更大量的請求
- 縱向擴充套件(垂直擴充套件) 將表和表分離或者是修改表的結構,按照訪問的差異性將列拆分
- 分庫分表 通過策略分配將請求分配到不同資料庫的相同表
(2) TokuDB、MyRocks、InnoDB 高效能寫入
場景:MySQL資料庫水平拆分,可以對於大資料量的讀寫進行線性擴充套件,但相應地底層伺服器數量也需要比較多;但對於資料寫入量非常大,資料讀很少,資料總量大的情況,使用高效能寫入架構,會更合適一些。業務資料寫入量非常大,讀取量非常高的情況,一般主要對資料insert寫入效能,同時對資料壓縮效率有特別高的要求。這種特殊的寫入要求,需要對資料寫入有特殊的優化和設計,並且有比較好的壓縮效率和演算法,能夠將寫入的大量資料進行壓縮,節省空間。這種寫入架構, 通常可以看做是MySQL資料庫的一種特殊的儲存引擎
具體到實現而言,MySQL的高效能寫入叢集,可以使用TokuDB儲存引擎。近幾年Facebook也開源了其內部實現的MyRocks,可以作為高效能寫入的儲存引擎。MySQL預設的InnoDB儲存引擎,在新的5.7及以後版本優化後,寫入效能和壓縮效能也有了更高的效能,也可以作為資料寫入的一種選擇。
(3)MySQL + 快取(Memcached、Redis等)
場景:MySQL資料庫水平拆分,可以對於大資料量的讀寫進行線性擴充套件,但相應地底層伺服器數量也需要比較多;但對於資料寫入量非常大,資料讀很少,資料總量大的情況,使用高效能寫入架構,會更合適一些。
資料庫快取框架,適用於將少量的熱資料放到記憶體中以此來提高訪問的效率。因為從記憶體中的讀取速度,遠大於IO讀取資料,cpu的消耗也會少很多。在業務場景中,使用者請求資料,先在快取中讀取資料,魂村中有資料就直接響應。沒有資料,則去資料庫中獲取資料,並將資料提交到快取,以供下次訪問。
快取系統常用的技術架構有Memcached 和Redis。Memcached是比較經典的快取系統,在之前常與LAMP、LNMP流行架構結合使用。Redis是幾年新興的Key-Value鍵值型NoSQL資料庫,除了作為快取,還可以持久化作為Key-Value資料庫使用。
(4)MySQL + 小檔案系統(MongoDB、Ceph等) 大欄位存取架構
場景:在MySQL資料庫中,通常是儲存符合關係型資料庫原理的小欄位,比如數值型、字元型資料;但在實際環境中,除了這些常用欄位,還會有一些大欄位,比如使用者頭像這種圖片檔案、上傳的音訊、視訊檔案、帖子內容等大text欄位,另外還有一些JSON檔案、XML檔案等,這些可以以二進位制形式儲存在MySQL資料庫中,但讀取和管理都會比較麻煩。這時,就可以使用小檔案系統來結合MySQL來使用。
小檔案系統,是可以儲存並快速訪問結構化資料的系統。對於圖片、音訊、視訊、TXT檔案、JSON檔案、XML檔案等大欄位,一般就只有簡單的讀寫操作,將這些欄位存入到小檔案系統中,並將對應的訪問連結存入到MySQL資料庫的表中。這樣通過資料庫表,可以快速讀寫檔案位置資訊,在小檔案系統中,通過檔案位置資訊,可以實現對大欄位的快速讀寫訪問。
具體實現而言,小檔案系統也有很多技術軟體,比較常見的有MongoDB文件型NoSQL資料庫、Ceph分散式小檔案系統等。
(5)MySQL + Inforbright/Greenplum 統計分析架構
場景:在MySQL資料庫上實時響應業務需要的查詢,通常是指OLTP業務,但對於已經產生的資料,場景:通常會在第二天之後,有結果彙總和統計分析需求。這類OLAP需求通常執行頻率較低,但每次執行消耗的資源很大,如果與OLTP一樣在一個系統上執行,就會造成這兩大類業務的相互影響。這時就可以使用MySQL資料庫與OLAP統計業務分類結合的架構。
MySQL產生了業務資料後,通常需要在第二天,要對前一天的資料進行各個角度、各個維度的統計、聚合、分析,以體現和反映業務的運營情況。這是讓MySQL支援線上OLTP業務,通過資料流轉程式,將每天產生的資料流轉到離線的資料倉庫系統中,在資料倉庫系統中,進行各種資料統計分析、結果彙總,並將資料統計結果再流轉到結果展示庫中。這樣就可以很好地實現線上OLTP和線下OLAP的結合使用和執行。
具體實現而言,對於MySQL資料庫可以結合的OLAP資料倉庫架構,可以選用Inforbright資料倉庫,也可以選用 Greenplum分散式MPP資料庫倉庫。相對而言,Inforbright資料倉庫比較輕量級,與MySQL使用類似;Greenplum分散式MPP資料倉庫可以支撐海量資料的統計分析,功能、效能、容量等也比Inforbright要更強一下,成本也更大一些。
總結
業務的開發,在MySQL的架構設計上來說,上面所述的是固定的架構,能應對一些普遍的業務,但是不要為了架構了而去強行的使用某些技術,按照自己的業務特性去設計會更好。 下面可以推薦一些架構的組合:
- MySQL+MHA高可用架構 與 MySQL分散式Proxy水平擴充套件架構 組合
- MySQL+MHA高可用架構 與 MySQL小檔案系統大欄位存取架構 組合
- MySQL+MHA高可用架構 與 MySQL快取高併發讀架構 組合
- MySQL分散式Proxy水平擴充套件架構 與 MySQL小檔案系統大欄位存取架構 組合
- MySQL分散式Proxy水平擴充套件架構 與 MySQL快取高併發讀架構 組合
- MySQL高效能寫入架構 與 MySQL Inforbright/Greenplum統計分析架構 組合
MySQL+MHA高可用架構 、MySQL分散式Proxy水平擴充套件架構、 MySQL快取高併發讀架構、 MySQL小檔案系統大欄位存取架構、MySQL Inforbright/Greenplum統計分析架構。