
contiki之list(1)
阿新 • • 發佈:2018-12-01
/**************************************************list.c************************************/
#define NULL 0
struct list {
struct list *next;
};
一上來就搞事情,定義一個結構型別叫struct list 裡面只有一個成員,還是這個結構體型別的指標,看字面的意思是想說指向下一個結構體,可是這樣的list有啥意義,把一堆結構體串成連結串列,然後就沒然後了,什麼內容也沒有,按理說結構體裡應該得有個data才對吧。一開始的時候我還真是在這個上面費了好大功夫,才弄懂這個作者到底想幹嘛。
我們就從某一個操作list的函式說起吧,我也是從這個函式裡找到靈感,才明白上面這個結構體到底想幹嘛。光看這個函式還是不能明白的,我們再加多一些用到這個list的程式碼。
/*********************nbr_table.c******************************/
typedef struct nbr_table_key { 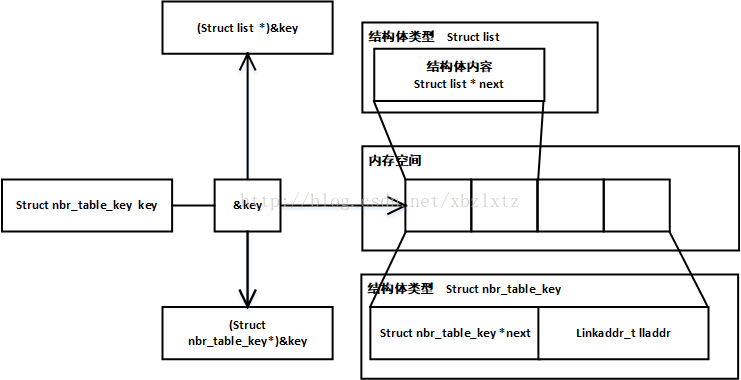
還記得我們一開始說到的怪怪的結構體麼,裡面只有一個本型別的指標,字面意思是指向下一個結構體。這裡居然把我們傳進來的nbr_table_keys_t型別結構體指標強轉成struct list結構體型別了。巧的是nbr_table_keys_t結構體的第一個成員剛好就叫next,跟struct list一樣。其實這是作者精心安排的。這裡插播一下關於這個型別強轉在記憶體裡是怎麼個原理,為什麼這樣強轉以後訪問的next成員就剛好是nbr_table_keys_t裡的next。 假設我們定義了key變數,指定了是什麼型別的,那麼就會在記憶體空間開闢一個指定型別大小的空間。如上圖的key變數。&key就是對key取址,得到的就是key變數在記憶體空間的首地址,如果這個時候你定義一個變數struct nbr_table_keys_t* key_ptr。然後 key_ptr = &key,編譯是不會錯的,因為這個指標型別跟變數型別一致,如果你定義 struct list* list_ptr = &key,編譯肯定報錯,型別不匹配。編譯器為啥要檢測型別匹配呢,因為你定義一個指標的時候是有指定型別的,這個型別就決定了指標在解引用的時候是怎麼對記憶體進行操作的,比如說int*就是把指標指向的地址開始四個位元組取出來,char*就是把指標指向地址開始一個位元組取出來。編譯器檢測型別匹配就是怕你亂來,如果你明明在記憶體中開闢了char型別的空間,然後用int*指標去解引用,這不就出事了麼。但是C語言偏偏還就允許出現型別不匹配,strcut list* list_ptr = &key不是不行麼,那我就struct list* list_ptr = (struct list *)&key,強轉,編譯通過。說了這麼多,意思就是C語言允許你用適當的手段,實現開闢記憶體時一種型別,使用記憶體時可以是各種型別,這很危險,但是也可以很強大。比如我們在討論的這個。 就如上圖中所示,我們傳進函式的是nbr_table_key_t指標,但是在用的時候是struct list,那麼就會有一段空間是訪問不到的。在一個系統裡,指標型別的變數,不管是何種型別的指標,均佔用一樣多的記憶體空間,因為指標變數存的是地址,不管何種型別的變數其地址都一樣長,所以作者就巧妙安排struct list 和nbr_table_key_t第一個成員名字一樣,而且都是指標。分析到這就明白為何strcut list結構體只有一個指標變量了,為了安全啊!list這個模組就是為了實現連結串列的各種操作,連結串列的每個單元總是會攜帶資料的嘛,為了不同的目的攜帶的資料都是不同的,但是連結串列的操作有很多都是一樣的,插入單元,刪除單元,取第一個,取最後一個等等。如何能夠讓不同連結串列單元型別的連結串列共享一樣的操作呢,作者就想出了這麼一個法子。 到此一切通順了 , ((struct list *)item)->next = NULL;意思就是說把key指標指向的nbr_table_key_t結構體變數中的next成員賦值為NULL 。接著 l = list_tail(list); 找列表的尾,假設我們這時候列表是空的,那麼就會返還NULL。接著往下看 if(l == NULL) { *list = item; } else { l->next = item; } 如果是NULL,那麼就把key指標賦值給用LIST巨集定義的那個指標變數。因為傳入函式的list是指向指標的指標,所以*list就是那個指標變量了。那麼就會是如圖的關係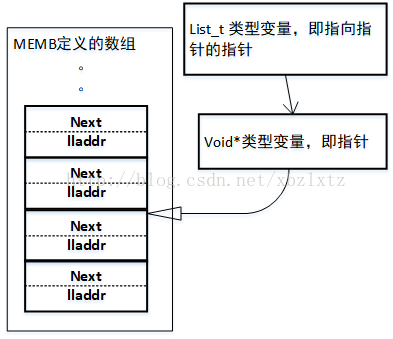
如果再一次呼叫list_add函式,把數組裡另外一個結構體地址作為item,那麼執行到if語句的時候,就會到另外一個分支 I->next = item。這裡的I就是連結串列最後一個單元。那麼就會是下圖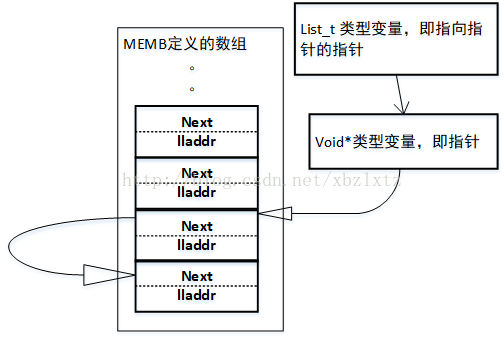
可以想象得到如果一直呼叫list_add的話就會成為一個長長的連結串列。
還記得我們一開始說到的怪怪的結構體麼,裡面只有一個本型別的指標,字面意思是指向下一個結構體。這裡居然把我們傳進來的nbr_table_keys_t型別結構體指標強轉成struct list結構體型別了。巧的是nbr_table_keys_t結構體的第一個成員剛好就叫next,跟struct list一樣。其實這是作者精心安排的。這裡插播一下關於這個型別強轉在記憶體裡是怎麼個原理,為什麼這樣強轉以後訪問的next成員就剛好是nbr_table_keys_t裡的next。 假設我們定義了key變數,指定了是什麼型別的,那麼就會在記憶體空間開闢一個指定型別大小的空間。如上圖的key變數。&key就是對key取址,得到的就是key變數在記憶體空間的首地址,如果這個時候你定義一個變數struct nbr_table_keys_t* key_ptr。然後 key_ptr = &key,編譯是不會錯的,因為這個指標型別跟變數型別一致,如果你定義 struct list* list_ptr = &key,編譯肯定報錯,型別不匹配。編譯器為啥要檢測型別匹配呢,因為你定義一個指標的時候是有指定型別的,這個型別就決定了指標在解引用的時候是怎麼對記憶體進行操作的,比如說int*就是把指標指向的地址開始四個位元組取出來,char*就是把指標指向地址開始一個位元組取出來。編譯器檢測型別匹配就是怕你亂來,如果你明明在記憶體中開闢了char型別的空間,然後用int*指標去解引用,這不就出事了麼。但是C語言偏偏還就允許出現型別不匹配,strcut list* list_ptr = &key不是不行麼,那我就struct list* list_ptr = (struct list *)&key,強轉,編譯通過。說了這麼多,意思就是C語言允許你用適當的手段,實現開闢記憶體時一種型別,使用記憶體時可以是各種型別,這很危險,但是也可以很強大。比如我們在討論的這個。 就如上圖中所示,我們傳進函式的是nbr_table_key_t指標,但是在用的時候是struct list,那麼就會有一段空間是訪問不到的。在一個系統裡,指標型別的變數,不管是何種型別的指標,均佔用一樣多的記憶體空間,因為指標變數存的是地址,不管何種型別的變數其地址都一樣長,所以作者就巧妙安排struct list 和nbr_table_key_t第一個成員名字一樣,而且都是指標。分析到這就明白為何strcut list結構體只有一個指標變量了,為了安全啊!list這個模組就是為了實現連結串列的各種操作,連結串列的每個單元總是會攜帶資料的嘛,為了不同的目的攜帶的資料都是不同的,但是連結串列的操作有很多都是一樣的,插入單元,刪除單元,取第一個,取最後一個等等。如何能夠讓不同連結串列單元型別的連結串列共享一樣的操作呢,作者就想出了這麼一個法子。 到此一切通順了 , ((struct list *)item)->next = NULL;意思就是說把key指標指向的nbr_table_key_t結構體變數中的next成員賦值為NULL 。接著 l = list_tail(list); 找列表的尾,假設我們這時候列表是空的,那麼就會返還NULL。接著往下看 if(l == NULL) { *list = item; } else { l->next = item; } 如果是NULL,那麼就把key指標賦值給用LIST巨集定義的那個指標變數。因為傳入函式的list是指向指標的指標,所以*list就是那個指標變量了。那麼就會是如圖的關係
如果再一次呼叫list_add函式,把數組裡另外一個結構體地址作為item,那麼執行到if語句的時候,就會到另外一個分支 I->next = item。這裡的I就是連結串列最後一個單元。那麼就會是下圖
可以想象得到如果一直呼叫list_add的話就會成為一個長長的連結串列。