
HDFS之檔案讀過程
阿新 • • 發佈:2018-12-01
HDFS 在檔案的增刪查操作上封裝的很好,我們只要寫幾行程式碼就可以解決問題,這操作每個大資料開發者都會。不過,作為一個程式設計師(其他職業也應如此),我認為應該培養自己的核心競爭力,會一點別人不會的東西,而不是侷限於 API 的使用上,將底層原理搞通才能越走越遠。那我們就開始吧!本篇主要闡述 HDFS 讀取檔案的流程。
整個流程分為以下幾個步驟:
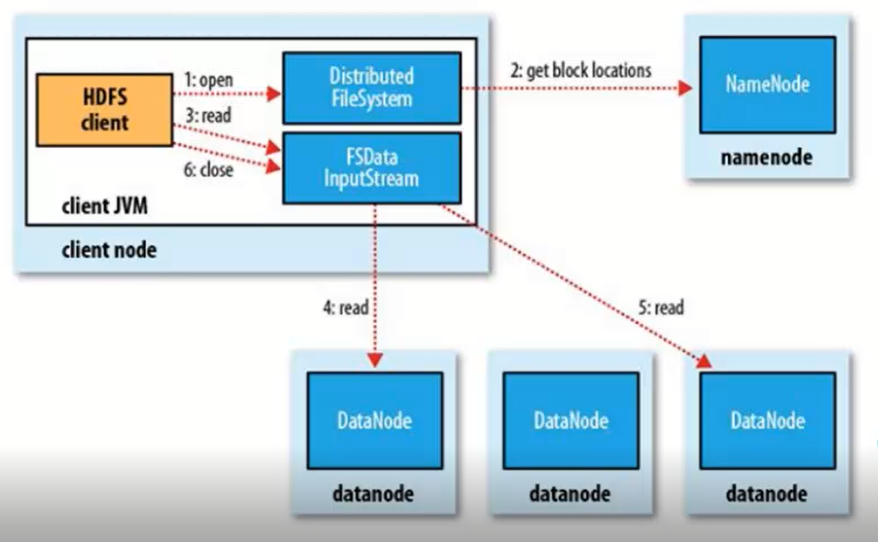
- 獲取檔案系統 FileSystem,在 HDFS,不同的檔案系統有不同的實現類,HDFS 使用的是分佈是檔案系統,其實現類為
DistributedFileSystem。 - 這個 FileSystem 通過 RPC 呼叫元資料節點的服務,獲取檔案的塊資訊,每一個塊資料都有一定數量的副本,返回結果根據資料節點與客戶端的距離進行排序,節省 map reduce 操作的時間,這個方法返回一個 FSDataInputStream 物件。
- 呼叫 FSDataInputStream 的 read 方法,FSDataInputStream 連線儲存第一個塊資料的節點,讀取塊檔案。第一個塊檔案讀取完成之後,連線下一個塊資料的節點。
- 傳輸完成之後呼叫 close 方法結束讀取檔案的過程。
在讀取的時候,如果客戶端在與資料節點通訊時遇到錯誤,那麼它就去嘗試對這個塊資料來說下一個最近的塊。它也會記住那個故障的資料節點,以保證不會再對之後的塊進行徒勞無益的嘗試。整個流程可以用這張圖來表示:
讀取檔案的程式碼如下。通過對照上面的流程,就可以更好的理解程式碼的含義。這裡再說明一下,為了獲取 FileSystem 物件,我們需要獲取伺服器的檔案系統型別,這個型別可以通過 Configuration 物件設定,也可以通過 core-site.xml 進行配置,如果這兩個地方都沒有進行設定的話,那麼預設返回 FileSystem 的例項是 LocalFileSystem 物件,即本地的檔案系統。
public void download() throws IOException{ Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://localhost:9000/"); FileSystem fs = FileSystem.get(conf); Path src = new Path("hdfs://localhost:9000/xxx.gz"); FSDataInputStream in = fs.open(src); FileOutputStream os = new FileOutputStream("xxx.gz"); IOUtils.copy(in, os); }
讀原始碼可以讓我們在 debug 時更快的定位到錯誤的來源,了整體流程可以讓我們更好的去分析原始碼,這種思維跟我在 發現了一種不錯的學習方法 中闡述的一致,對於想要學習的知識有一個巨集觀的認識,再根據需要對於各個部分進行深入,繼續堅持下去,希望自己早日轉到大資料行業,filghting !