
一文讓你完全弄懂Stegosaurus
一文讓你完全弄懂Stegosaurus
國內關於 Stegosaurus 的介紹少之又少,一般只是單純的工具使用的講解之類的,並且本人在學習過程中也是遇到了很多的問題,基於此種情況下寫下此文,也是為我逝去的青春時光留個念想吧~
Stegosaurus是什麼?
在瞭解 Stegosaurus 是什麼之前,我們首先需要弄清楚的一個問題是:什麼是隱寫術?
隱寫術,從字面上來理解,隱是隱藏,所以我們從字面上可以知道,隱寫術是一類可以隱藏自己寫的一些東西的方法,可能我們所寫的這些東西是一些比較重要的資訊,不想讓別人看到,我們會考慮採取一些辦法去隱藏它,比如對所寫的檔案加解密,用一些特殊的紙張(比如紙張遇到水後,上面的字才會顯示出來)之類的。隱寫術這種手段在日常生活中用的十分廣泛,我相信部分小夥伴們小時候曾經有過寫日記的習慣,寫完的日記可能不想讓爸爸媽媽知道(青春期萌動的內心,咱們都是過來人,都懂這個2333),所以以前常常會買那種上了把鎖的那種日記本,這樣就不怕自己的小祕密被爸爸媽媽知道啦。
事實上,隱寫術是一門關於資訊隱藏的技巧與科學,專業一點的講,就是指的是採取一些不讓除預期的接收者之外的任何人知曉資訊的傳遞事件或者資訊的內容的方法。隱寫術的英文叫做 Steganography ,根據維基百科的解釋,這個英文來源於特里特米烏斯的一本講述密碼學與隱寫術的著作 Steganographia ,該書書名源於希臘語,意為“隱祕書寫”。(這個不是重點)
所以今天呢,我們要給大家介紹的是隱寫術的其中一個分支(也就是其中一種隱寫的方法),也就是 Stegosaurus , Stegosaurus 是一款隱寫工具,它允許我們在 Python
pyc 或 pyo )中嵌入任意 Payload 。由於編碼密度較低,因此我們嵌入 Payload 的過程既不會改變原始碼的執行行為,也不會改變原始檔的檔案大小。 Payload 程式碼會被分散嵌入到位元組碼之中,所以類似 strings 這樣的程式碼工具無法查詢到實際的 Payload 。 Python 的 dis 模組會返回原始檔的位元組碼,然後我們就可以使用 StegosaurusPayload 了。
為了方便維護,我將此專案移至 Github 上:https://github.com/AngelKitty/stegosaurus
首先講到一個工具,不可避免的,我們需要講解它的用法,我並不會像文件一樣工整的把用法羅列在一起,如果需要了解更加細節的部分請參考 Github上的詳細文件,我會拿一些實際的案例去給大家講解一些常見命令的用法,在後續的文章中,我會大家深入理解 python 反編譯的一些東西。
Stegosaurus僅支援Python3.6及其以下版本
拿到一個工具,我們一般會看看它的基本用法:
python3 stegosaurus.py -h$ python3 -m stegosaurus -h
usage: stegosaurus.py [-h] [-p PAYLOAD] [-r] [-s] [-v] [-x] carrier
positional arguments:
carrier Carrier py, pyc or pyo file
optional arguments:
-h, --help show this help message and exit
-p PAYLOAD, --payload PAYLOAD
Embed payload in carrier file
-r, --report Report max available payload size carrier supports
-s, --side-by-side Do not overwrite carrier file, install side by side
instead.
-v, --verbose Increase verbosity once per use
-x, --extract Extract payload from carrier file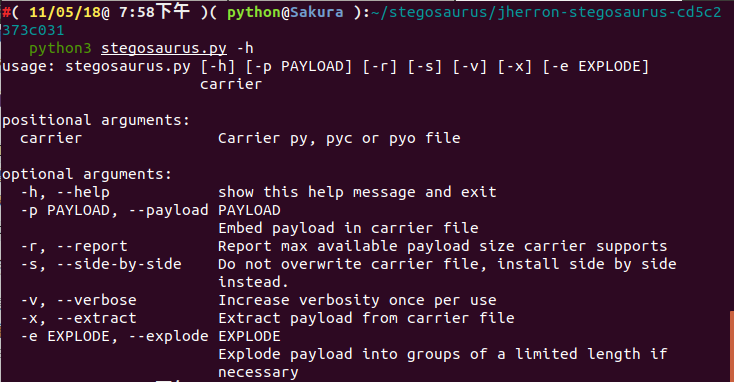
我們可以看到有很多引數選項,我們就以一道賽題來講解部分引數命令吧~
我們此次要講解的這道題是來自 Bugku 的 QAQ
賽題連結如下:
http://ctf.bugku.com/files/447e4b626f2d2481809b8690613c1613/QAQ
http://ctf.bugku.com/files/5c02892cd05a9dcd1c5a34ef22dd9c5e/cipher.txt首先拿到這道題,用 010Editor 乍一眼看過去,我們可以看到一些特徵資訊:
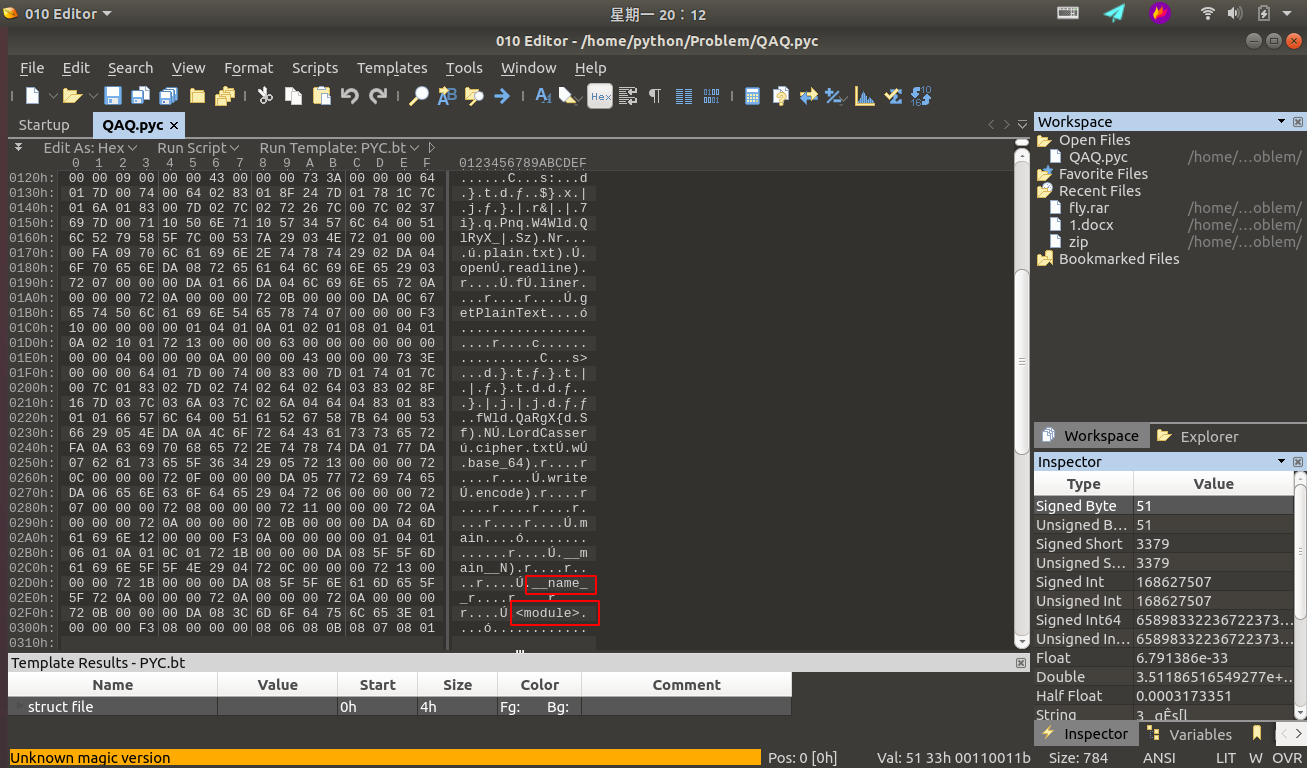
可以判斷這是個跟 python 有關的東西,通過查閱相關資料可以判斷這是個 python 經編譯過後的 pyc 檔案。這裡可能很多小夥伴們可能不理解了,什麼是 pyc 檔案呢?為什麼會生成 pyc 檔案? pyc 檔案又是何時生成的呢?下面我將一一解答這些問題。
簡單來說, pyc 檔案就是 Python 的位元組碼檔案,是個二進位制檔案。我們都知道 Python 是一種全平臺的解釋性語言,全平臺其實就是 Python 檔案在經過直譯器解釋之後(或者稱為編譯)生成的 pyc 檔案可以在多個平臺下執行,這樣同樣也可以隱藏原始碼。其實, Python 是完全面向物件的語言, Python 檔案在經過直譯器解釋後生成位元組碼物件 PyCodeObject , pyc 檔案可以理解為是 PyCodeObject 物件的持久化儲存方式。而 pyc 檔案只有在檔案被當成模組匯入時才會生成。也就是說, Python 直譯器認為,只有 import 進行的模組才需要被重用。 生成 pyc 檔案的好處顯而易見,當我們多次執行程式時,不需要重新對該模組進行重新的解釋。主檔案一般只需要載入一次,不會被其他模組匯入,所以一般主檔案不會生成 pyc 檔案。
我們舉個例子來說明這個問題:
為了方便起見,我們事先建立一個test資料夾作為此次實驗的測試:
mkdir test && cd test/假設我們現在有個 test.py 檔案,檔案內容如下:
def print_test():
print('Hello,Kitty!')
print_test()我們執行以下命令:
python3 test.py不用說,想必大家都知道打印出的結果是下面這個:
Hello,Kitty!我們通過下面命令檢視下當前資料夾下有哪些檔案:
ls -alh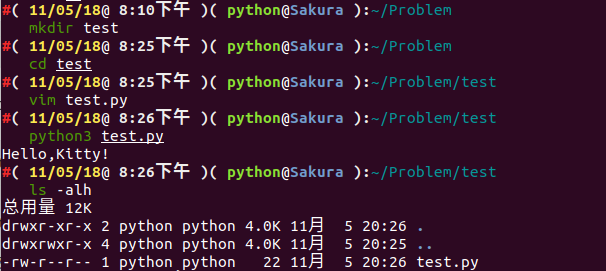
我們可以發現,並沒有 pyc 檔案生成。
‘我們再去建立一個檔案為 import_test.py 檔案,檔案內容如下:
注:
test.py和import_test.py應當放在同一資料夾下
import test
test.print_test()我們執行以下命令:
python3 import_test.py結果如下:
Hello,Kitty!
Hello,Kitty!誒,為啥會打印出兩句相同的話呢?我們再往下看,我們通過下面命令檢視下當前資料夾下有哪些檔案:
ls -alh結果如下:
總用量 20K
drwxr-xr-x 3 python python 4.0K 11月 5 20:38 .
drwxrwxr-x 4 python python 4.0K 11月 5 20:25 ..
-rw-r--r-- 1 python python 31 11月 5 20:38 import_test.py
drwxr-xr-x 2 python python 4.0K 11月 5 20:38 __pycache__
-rw-r--r-- 1 python python 58 11月 5 20:28 test.py誒,多了個 __pycache__ 資料夾,我們進入資料夾下看看有什麼?
cd __pycache__ && ls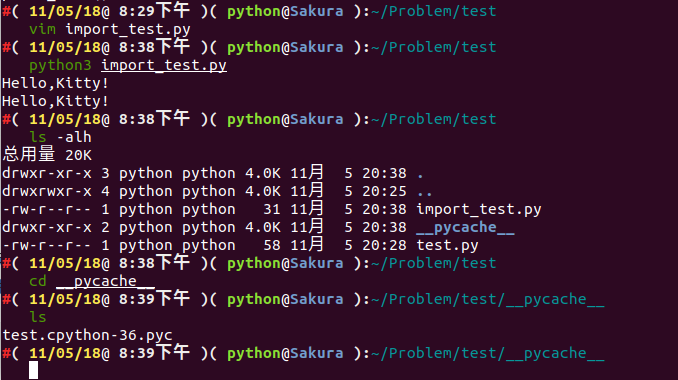
我們可以看到生成了一個 test.cpython-36.pyc 。為什麼是這樣子呢?
我們可以看到,我們在執行 python3 import_test.py 命令的時候,首先開始執行的是 import test ,即匯入 test 模組,而一個模組被匯入時, PVM(Python Virtual Machine) 會在後臺從一系列路徑中搜索該模組,其搜尋過程如下:
- 在當前目錄下搜尋該模組
- 在環境變數
PYTHONPATH中指定的路徑列表中依次搜尋 - 在
python安裝路徑中搜索
事實上, PVM 通過變數 sys.path 中包含的路徑來搜尋,這個變數裡面包含的路徑列表就是上面提到的這些路徑資訊。
模組的搜尋路徑都放在了 sys.path 列表中,如果預設的 sys.path 中沒有含有自己的模組或包的路徑,可以動態的加入 (sys.path.apend) 即可。
事實上, Python 中所有載入到記憶體的模組都放在 sys.modules 。當 import 一個模組時首先會在這個列表中查詢是否已經載入了此模組,如果載入了則只是將模組的名字加入到正在呼叫 import 的模組的 Local 名字空間中。如果沒有載入則從 sys.path目錄中按照模組名稱查詢模組檔案,模組檔案可以是 py 、 pyc 、 pyd ,找到後將模組載入記憶體,並加入到 sys.modules中,並將名稱匯入到當前的 Local 名字空間。
可以看出來,一個模組不會重複載入。多個不同的模組都可以用 import 引入同一個模組到自己的 Local 名字空間,其實背後的 PyModuleObject 物件只有一個。
在這裡,我還要說明一個問題,import 只能匯入模組,不能匯入模組中的物件(類、函式、變數等)。例如像上面這個例子,我在 test.py 裡面定義了一個函式 print_test() ,我在另外一個模組檔案 import_test.py不能直接通過 import test.print_test 將 print_test 匯入到本模組檔案中,只能用 import test 進行匯入。如果我想只匯入特定的類、函式、變數,用 from test import print_test 即可。

既然說到了 import 匯入機制,再提一提巢狀匯入和 Package 匯入。
import 巢狀匯入
巢狀,不難理解,就是一個套著一個。小時候我們都玩過俄羅斯套娃吧,俄羅斯套娃就是一個大娃娃裡面套著一個小娃娃,小娃娃裡面還有更小的娃娃,而這個巢狀匯入也是同一個意思。假如我們現在有一個模組,我們想要匯入模組 A ,而模組 A 中有含有其他模組需要匯入,比如模組 B ,模組 B 中又含有模組 C ,一直這樣延續下去,這種方式我們稱之為 import 巢狀匯入。
對這種巢狀比較容易理解,我們需要注意的一點就是各個模組的 Local 名字空間是獨立的,所以上面的例子,本模組 import A 完了後,本模組只能訪問模組 A ,不能訪問 B 及其它模組。雖然模組 B 已經載入到記憶體了,如果要訪問,還必須明確在本模組中匯入 import B 。
那如果我們有以下巢狀這種情況,我們該怎麼處理呢?
比如我們現在有個模組 A :
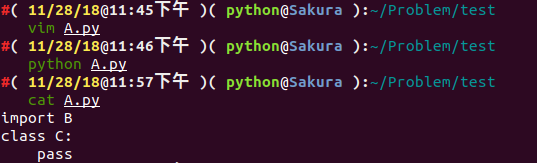
# A.py
from B import D
class C:
pass還有個模組 B :
# B.py
from A import C
class D:
pass我們簡單分析一下程式,如果程式執行,應該會去從模組B中呼叫物件D。
我們嘗試執行一下 python A.py :
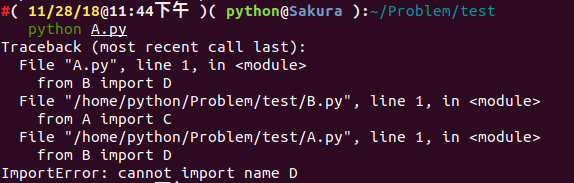
報 ImportError 的錯誤,似乎是沒有載入到物件 D ,而我們將 from B import D 改成 import B ,我們似乎就能執行成功了。
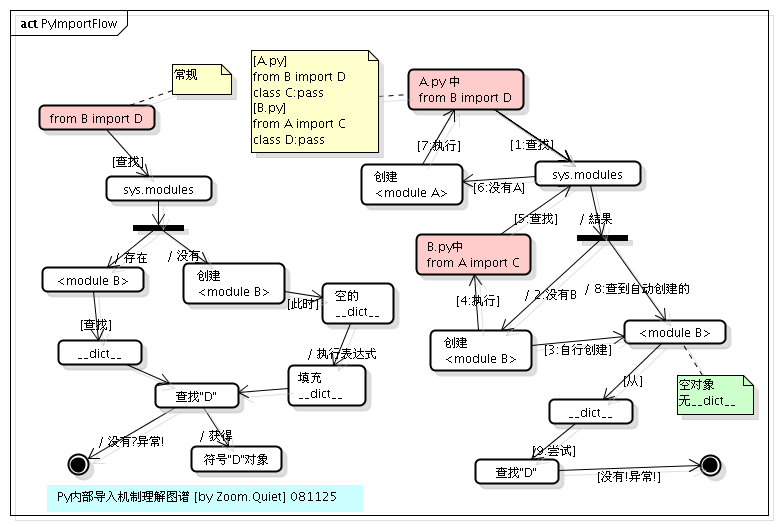
這是怎麼回事呢?這其實是跟 Python 內部 import 的機制是有關的,具體到 from B import D , Python 內部會分成以下幾個步驟:
- 在
sys.modules中查詢符號B - 如果符號
B存在,則獲得符號B對應的module物件<module B>。從<module B>的__dict__中獲得符號D對應的物件,如果D不存在,則丟擲異常 - 如果符號
B不存在,則建立一個新的module物件<module B>,注意,此時module物件的__dict__為空。執行B.py中的表示式,填充<module B>的__dict__。從<module B>的__dict__中獲得D對應的物件。如果D不存在,則丟擲異常。
所以,這個例子的執行順序如下:
1、執行 A.py 中的 from B import D
注:由於是執行的
python A.py,所以在sys.modules中並沒有<module B>存在,首先為B.py建立一個module物件(<module B>),注意,這時建立的這個module物件是空的,裡邊啥也沒有,在Python內部建立了這個module物件之後,就會解析執行B.py,其目的是填充<module B>這個dict。
2、執行 B.py 中的 from A import C
注:在執行
B.py的過程中,會碰到這一句,首先檢查sys.modules這個module快取中是否已經存在<module A>了,由於這時快取還沒有快取<module A>,所以類似的,Python內部會為A.py建立一個module物件(<module A>),然後,同樣地,執行A.py中的語句。
3、再次執行 A.py 中的 from B import D
注:這時,由於在第
1步時,建立的<module B>物件已經快取在了sys.modules中,所以直接就得到了<module B>,但是,注意,從整個過程來看,我們知道,這時<module B>還是一個空的物件,裡面啥也沒有,所以從這個module中獲得符號D的操作就會丟擲異常。如果這裡只是import B,由於B這個符號在sys.modules中已經存在,所以是不會丟擲異常的。
我們可以從下圖很清楚的看到 import 巢狀匯入的過程:
Package 匯入
包 (Package) 可以看成模組的集合,只要一個資料夾下面有個 __init__.py 檔案,那麼這個資料夾就可以看做是一個包。包下面的資料夾還可以成為包(子包)。更進一步的講,多個較小的包可以聚合成一個較大的包。通過包這種結構,我們可以很方便的進行類的管理和維護,也方便了使用者的使用。比如 SQLAlchemy 等都是以包的形式釋出給使用者的。
包和模組其實是很類似的東西,如果檢視包的型別: import SQLAlchemy type(SQLAlchemy) ,可以看到其實也是 <type 'module'> 。 import 包的時候查詢的路徑也是 sys.path。
包匯入的過程和模組的基本一致,只是匯入包的時候會執行此包目錄下的 __init__.py ,而不是模組裡面的語句了。另外,如果只是單純的匯入包,而包的 __init__.py 中又沒有明確的其他初始化操作,那麼此包下面的模組是不會自動匯入的。
假設我們有如下檔案結構:
.
└── PA
├── __init__.py
├── PB1
│ ├── __init__.py
│ └── pb1_m.py
├── PB2
│ ├── __init__.py
│ └── pb2_m.py
└── wave.py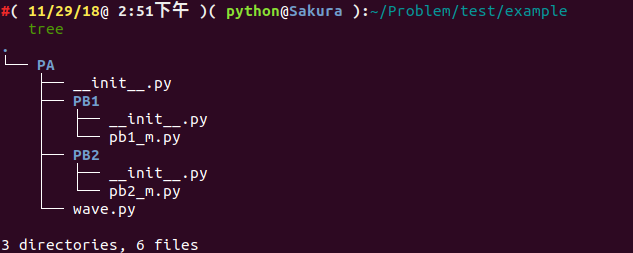
wave.py , pb1_m.py , pb2_m.py 檔案中我們均定義瞭如下函式:
def getName():
pass__init__.py 檔案內容均為空。
我們新建一個 test.py ,內容如下:
import sys
import PA.wave #1
import PA.PB1 #2
import PA.PB1.pb1_m as m1 #3
import PA.PB2.pb2_m #4
PA.wave.getName() #5
m1.getName() #6
PA.PB2.pb2_m.getName() #7我們執行以後,可以看出是成功執行成功了,我們再看看目錄結構:
.
├── PA
│ ├── __init__.py
│ ├── __init__.pyc
│ ├── PB1
│ │ ├── __init__.py
│ │ ├── __init__.pyc
│ │ ├── pb1_m.py
│ │ └── pb1_m.pyc
│ ├── PB2
│ │ ├── __init__.py
│ │ ├── __init__.pyc
│ │ ├── pb2_m.py
│ │ └── pb2_m.pyc
│ ├── wave.py
│ └── wave.pyc
└── test.py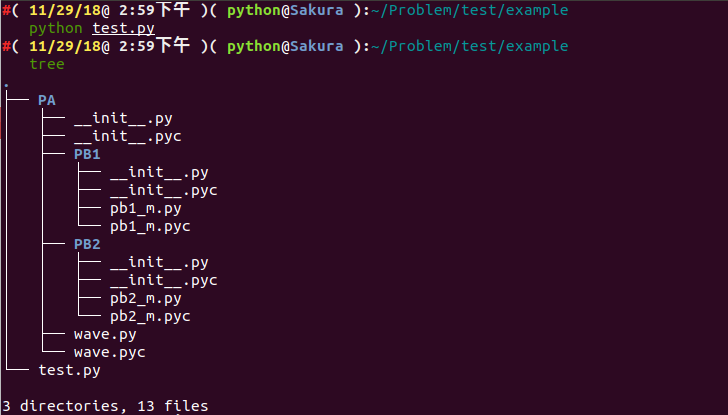
我們來分析一下這個過程:
- 當執行
#1後,sys.modules會同時存在PA、PA.wave兩個模組,此時可以呼叫PA.wave的任何類或函數了。但不能呼叫PA.PB1(2)下的任何模組。當前Local中有了PA名字。 - 當執行
#2後,只是將PA.PB1載入記憶體,sys.modules中會有PA、PA.wave、PA.PB1三個模組,但是PA.PB1下的任何模組都沒有自動載入記憶體,此時如果直接執行PA.PB1.pb1_m.getName()則會出錯,因為PA.PB1中並沒有pb1_m。當前Local中還是隻有PA名字,並沒有PA.PB1名字。 - 當執行
#3後,會將PA.PB1下的pb1_m載入記憶體,sys.modules中會有PA、PA.wave、PA.PB1、PA.PB1.pb1_m四個模組,此時可以執行PA.PB1.pb1_m.getName()了。由於使用了as,當前Local中除了PA名字,另外添加了m1作為PA.PB1.pb1_m的別名。 - 當執行
#4後,會將PA.PB2、PA.PB2.pb2_m載入記憶體,sys.modules中會有PA、PA.wave、PA.PB1、PA.PB1.pb1_m、PA.PB2、PA.PB2.pb2_m六個模組。當前Local中還是隻有PA、m1。 - 下面的
#5,#6,#7都是可以正確執行的。
注:需要注意的問題是如果
PA.PB2.pb2_m想匯入PA.PB1.pb1_m、PA.wave是可以直接成功的。最好是採用明確的匯入路徑,對於../..相對匯入路徑還是不推薦使用。
既然我們已經知道 pyc 檔案的產生,再回到那道賽題,我們嘗試將 pyc 檔案反編譯回 python 原始碼。我們使用線上的開源工具進行嘗試:
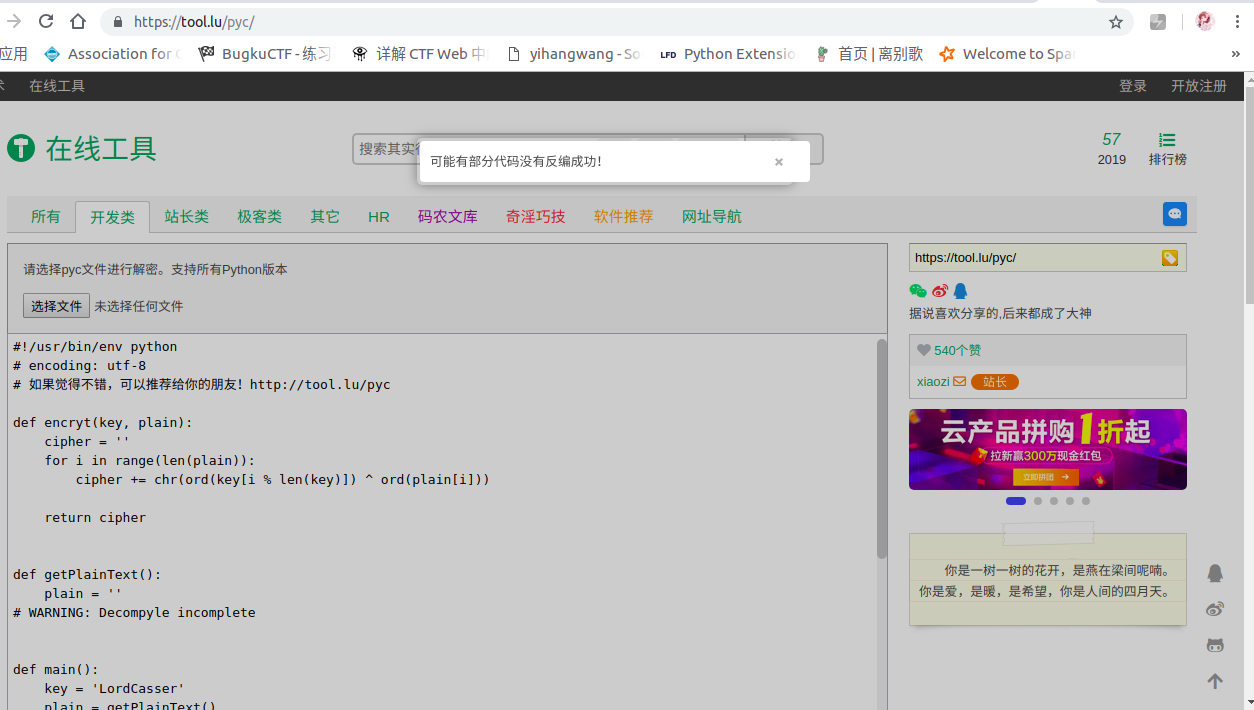
部分程式碼沒有反編譯成功???我們可以嘗試分析一下,大概意思就是讀取 cipher.txt 那個檔案,將那個檔案內容是通過 base64編碼的,我們的目的是將檔案內容解碼,然後又已知 key ,通過 encryt 函式進行加密的,我們可以嘗試將程式碼補全:
def encryt(key, plain):
cipher = ''
for i in range(len(plain)):
cipher += chr(ord(key[i % len(key)]) ^ ord(plain[i]))
return cipher
def getPlainText():
plain = ''
with open('cipher.txt') as (f):
while True:
line = f.readline()
if line:
plain += line
else:
break
return plain.decode('base_64')
def main():
key = 'LordCasser'
plain = getPlainText()
cipher = encryt(key, plain)
with open('xxx.txt', 'w') as (f):
f.write(cipher)
if __name__ == '__main__':
main()結果如下:
YOU ARE FOOLED
THIS IS NOT THAT YOU WANT
GO ON DUDE
CATCH THAT STEGOSAURUS提示告訴我們用 STEGOSAURUS 工具進行隱寫的,我們直接將隱藏的payload分離出來即可。
python3 stegosaurus.py -x QAQ.pyc
我們得到了最終的 flag 為:flag{fin4lly_z3r0_d34d}
既然都說到這個份子上了,我們就來分析一下我們是如何通過 Stegosaurus 來嵌入 Payload 。
我們仍然以上面這個程式碼為例子,我們設定指令碼名稱為 encode.py 。
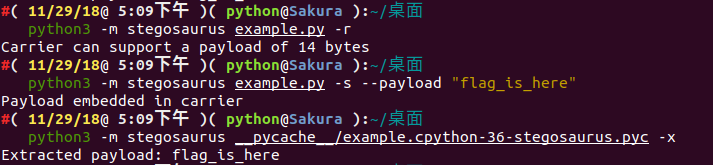
第一步,我們使用 Stegosaurus 來檢視在不改變原始檔 (Carrier) 大小的情況下,我們的 Payload 能攜帶多少位元組的資料:
python3 -m stegosaurus encode.py -r
現在,我們可以安全地嵌入最多24個位元組的 Payload 了。如果不想覆蓋原始檔的話,我們可以使用 -s 引數來單獨生成一個嵌入了 Payload 的 py 檔案:
python3 -m stegosaurus encode.py -s --payload "flag{fin4lly_z3r0_d34d}"
現在我們可以用 ls 命令檢視磁碟目錄,嵌入了 Payload 的檔案( carrier 檔案)和原始的位元組碼檔案兩者大小是完全相同的:

注:如果沒有使用
-s引數,那麼原始的位元組碼檔案將會被覆蓋。
我們可以通過向 Stegosaurus 傳遞 -x 引數來提取出 Payload :
python3 -m stegosaurus __pycache__/encode.cpython-36-stegosaurus.pyc -x
我們構造的 Payload 不一定要是一個 ASCII 字串, shellcode 也是可以的:

我們重新編寫一個 example.py 模組,程式碼如下:
import sys
import os
import math
def add(a,b):
return int(a)+int(b)
def sum1(result):
return int(result)*3
def sum2(result):
return int(result)/3
def sum3(result):
return int(result)-3
def main():
a = 1
b = 2
result = add(a,b)
print(sum1(result))
print(sum2(result))
print(sum3(result))
if __name__ == "__main__":
main()我們讓它攜帶 Payload 為 flag_is_here。
我們可以檢視嵌入 Payload 之前和之後的 Python 程式碼執行情況:
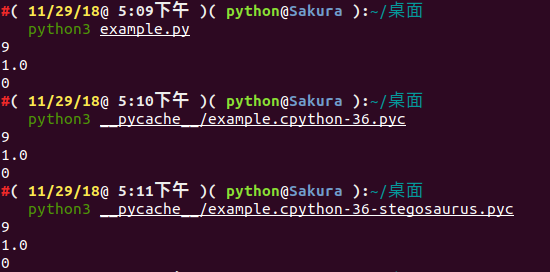
通過 strings 檢視 Stegosaurus 嵌入了 Payload 之後的檔案輸出情況( payload 並沒有顯示出來):
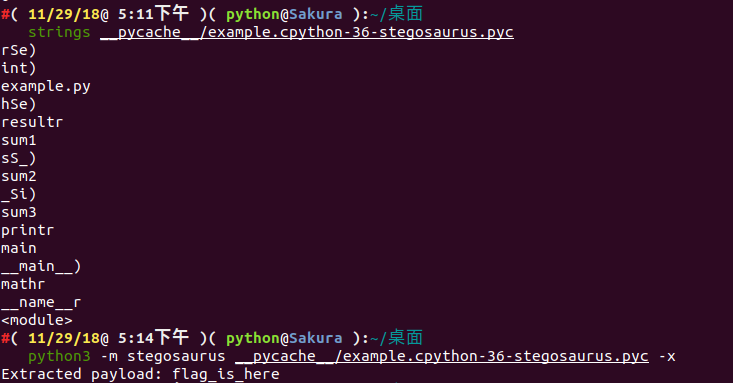
接下來使用 Python 的 dis 模組來檢視 Stegosaurus 嵌入 Payload 之前和之後的檔案位元組碼變化情況:
嵌入payload之前:
#( 11/29/[email protected] 5:14下午 )( [email protected] ):~/桌面
python3 -m dis example.py
1 0 LOAD_CONST 0 (0)
2 LOAD_CONST 1 (None)
4 IMPORT_NAME 0 (sys)
6 STORE_NAME 0 (sys)
2 8 LOAD_CONST 0 (0)
10 LOAD_CONST 1 (None)
12 IMPORT_NAME 1 (os)
14 STORE_NAME 1 (os)
3 16 LOAD_CONST 0 (0)
18 LOAD_CONST 1 (None)
20 IMPORT_NAME 2 (math)
22 STORE_NAME 2 (math)
4 24 LOAD_CONST 2 (<code object add at 0x7f90479778a0, file "example.py", line 4>)
26 LOAD_CONST 3 ('add')
28 MAKE_FUNCTION 0
30 STORE_NAME 3 (add)
6 32 LOAD_CONST 4 (<code object sum1 at 0x7f9047977810, file "example.py", line 6>)
34 LOAD_CONST 5 ('sum1')
36 MAKE_FUNCTION 0
38 STORE_NAME 4 (sum1)
9 40 LOAD_CONST 6 (<code object sum2 at 0x7f9047977ae0, file "example.py", line 9>)
42 LOAD_CONST 7 ('sum2')
44 MAKE_FUNCTION 0
46 STORE_NAME 5 (sum2)
12 48 LOAD_CONST 8 (<code object sum3 at 0x7f9047977f60, file "example.py", line 12>)
50 LOAD_CONST 9 ('sum3')
52 MAKE_FUNCTION 0
54 STORE_NAME 6 (sum3)
15 56 LOAD_CONST 10 (<code object main at 0x7f904798c300, file "example.py", line 15>)
58 LOAD_CONST 11 ('main')
60 MAKE_FUNCTION 0
62 STORE_NAME 7 (main)
23 64 LOAD_NAME 8 (__name__)
66 LOAD_CONST 12 ('__main__')
68 COMPARE_OP 2 (==)
70 POP_JUMP_IF_FALSE 78
24 72 LOAD_NAME 7 (main)
74 CALL_FUNCTION 0
76 POP_TOP
>> 78 LOAD_CONST 1 (None)
80 RETURN_VALUE嵌入 payload 之後:
#( 11/29/[email protected] 5:31下午 )( [email protected] ):~/桌面
python3 -m dis example.py
1 0 LOAD_CONST 0 (0)
2 LOAD_CONST 1 (None)
4 IMPORT_NAME 0 (sys)
6 STORE_NAME 0 (sys)
2 8 LOAD_CONST 0 (0)
10 LOAD_CONST 1 (None)
12 IMPORT_NAME 1 (os)
14 STORE_NAME 1 (os)
3 16 LOAD_CONST 0 (0)
18 LOAD_CONST 1 (None)
20 IMPORT_NAME 2 (math)
22 STORE_NAME 2 (math)
4 24 LOAD_CONST 2 (<code object add at 0x7f146e7038a0, file "example.py", line 4>)
26 LOAD_CONST 3 ('add')
28 MAKE_FUNCTION 0
30 STORE_NAME 3 (add)
6 32 LOAD_CONST 4 (<code object sum1 at 0x7f146e703810, file "example.py", line 6>)
34 LOAD_CONST 5 ('sum1')
36 MAKE_FUNCTION 0
38 STORE_NAME 4 (sum1)
9 40 LOAD_CONST 6 (<code object sum2 at 0x7f146e703ae0, file "example.py", line 9>)
42 LOAD_CONST 7 ('sum2')
44 MAKE_FUNCTION 0
46 STORE_NAME 5 (sum2)
12 48 LOAD_CONST 8 (<code object sum3 at 0x7f146e703f60, file "example.py", line 12>)
50 LOAD_CONST 9 ('sum3')
52 MAKE_FUNCTION 0
54 STORE_NAME 6 (sum3)
15 56 LOAD_CONST 10 (<code object main at 0x7f146e718300, file "example.py", line 15>)
58 LOAD_CONST 11 ('main')
60 MAKE_FUNCTION 0
62 STORE_NAME 7 (main)
23 64 LOAD_NAME 8 (__name__)
66 LOAD_CONST 12 ('__main__')
68 COMPARE_OP 2 (==)
70 POP_JUMP_IF_FALSE 78
24 72 LOAD_NAME 7 (main)
74 CALL_FUNCTION 0
76 POP_TOP
>> 78 LOAD_CONST 1 (None)
80 RETURN_VALUE注:
Payload的傳送和接受方法完全取決於使用者個人喜好,Stegosaurus只提供了一種向Python位元組碼檔案嵌入或提取Payload的方法。但是為了保證嵌入之後的程式碼檔案大小不會發生變化,因此Stegosaurus所支援嵌入的Payload位元組長度十分有限。因此 ,如果你需要嵌入一個很大的Payload,那麼你可能要將其分散儲存於多個位元組碼檔案中了。
為了在不改變原始檔大小的情況下向其嵌入 Payload ,我們需要識別出位元組碼中的無效空間( Dead Zone )。這裡所謂的無效空間指的是那些即使被修改也不會改變原 Python 指令碼正常行為的那些位元組資料。
需要注意的是,我們可以輕而易舉地找出 Python3.6 程式碼中的無效空間。 Python 的引用直譯器 CPython 有兩種型別的操作碼:即無引數的和有引數的。在版本號低於 3.5 的 Python 版本中,根據操作碼是否帶參,位元組碼中的操作指令將需要佔用 1 個位元組或 3 個位元組。在 Python3.6 中就不一樣了, Python3.6 中所有的指令都佔用 2 個位元組,並會將無引數指令的第二個位元組設定為 0 ,這個位元組在其執行過程中將會被直譯器忽略。這也就意味著,對於位元組碼中每一個不帶引數的操作指令, Stegosaurus 都可以安全地嵌入長度為 1 個位元組的 Payload 程式碼。
我們可以通過 Stegosaurus 的 -vv 選項來檢視 Payload 是如何嵌入到這些無效空間之中的:
#( 11/29/[email protected]:35下午 )( [email protected] ):~/桌面
python3 -m stegosaurus example.py -s -p "ABCDE" -vv
2018-11-29 22:36:26,795 - stegosaurus - DEBUG - Validated args
2018-11-29 22:36:26,797 - stegosaurus - INFO - Compiled example.py as __pycache__/example.cpython-36.pyc for use as carrier
2018-11-29 22:36:26,797 - stegosaurus - DEBUG - Read header and bytecode from carrier
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - POP_TOP (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - POP_TOP (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - POP_TOP (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - BINARY_SUBTRACT (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - BINARY_TRUE_DIVIDE (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - BINARY_MULTIPLY (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - BINARY_ADD (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - POP_TOP (0)
2018-11-29 22:36:26,798 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,798 - stegosaurus - INFO - Found 14 bytes available for payload
Payload embedded in carrier
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - POP_TOP (65) ----A
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - POP_TOP (66) ----B
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - POP_TOP (67) ----C
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - RETURN_VALUE (68) ----D
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - BINARY_SUBTRACT (69) ----E
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - BINARY_TRUE_DIVIDE (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - BINARY_MULTIPLY (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - BINARY_ADD (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - POP_TOP (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - RETURN_VALUE (0)
2018-11-29 22:36:26,799 - stegosaurus - DEBUG - Creating new carrier file name for side-by-side install
2018-11-29 22:36:26,799 - stegosaurus - INFO - Wrote carrier file as __pycache__/example.cpython-36-stegosaurus.pyc參考文獻
- https://bitbucket.org/jherron/stegosaurus/src
- https://github.com/AngelKitty/stegosaurus
- https://www.freebuf.com/sectool/129357.html