
26.A Model of Saliency-Based Visual Attention for Rapid Scene Analysis
A Model of Saliency-Based Visual Attention for Rapid Scene Analysis
基於顯著性的快速場景分析視覺注意模型
摘要
受到對早期靈長類動物的視覺系統的表現和其神經元結構的啟發,提出了一個新的視覺注意力機制。把多個特徵點影象組合成一個標誌其特點的顯著圖。然後為了減少顯著特徵的數量,神經網路只會選擇有明顯特徵的地點。這個系統解決了快速選擇中複雜的場景感應問題,僅僅顯著的地方會被仔細分析。
關鍵字:視覺注意,場景分析,特徵提取,目標檢測,視覺搜尋
1 引言
靈長類動物擁有一個重要的能力,即實時分析複雜的場景,儘管負責這種任務的神經元硬體條件在速度方面有一定的侷限。媒介和更高階的視覺處理流程在後續處理上對場景資訊進行了選擇,只保留了他們的一部分。這樣做大大減少了場景分析的複雜程度。這種選擇是通過視覺領域的空間區域性區域的形式實現的,這就是所謂的“注意力焦點”,這種方法不僅快速、由下向上、基於顯著特點,而且還能較慢的、自上向下的、意志控制的、和取決任務目標的方式掃描場景影象。
注意力模型包括“動態路由”模型,在此模型中大腦皮層的視覺層次結構處理的僅僅是視覺領域中的一部分割槽域的資訊。這個注意力區域的選擇取決於大腦皮層連通的動態改變、或者是活動的特殊暫時模式的建立,它們都是在自上向下(任務獨立)和自下向上(場景依賴)的控制之中的。
這裡使用的模型建立在Koch 和Ullman等基於幾個模型提出的第二生物合理框架結構上的(圖一)。它和用來解釋人類視覺搜尋策略的所謂的“特徵整合理論”是相關聯的。視覺輸入首先分解成一組地形圖。然後,不同的空間位置在每個圖譜內競爭顯著性,使得只有區域性從其周圍突出的位置才能持續存在。所有的特徵圖以一個純粹的自下向上的方式的處理成為一個主要的“顯著圖”,它在整個視覺場景中對區域性醒目性進行編碼。在靈長類動物中,這樣的特徵圖被認為放置在頂葉皮層中,還有各種視覺特徵圖位於丘腦的核心處。這個模型的顯著圖被賦予了內部動態,而這種內部動態形成了注意力偏移。因此這個模型描繪了完整一列自下向上的顯著特徵,並且沒有為了轉移注意要求任何一個自上向下的引導。在快速篩選中,這個框架結構針對少數感興趣的影象目標進行更復雜和耗時的目標識別流程。聽過了大量的對比方法。這種方法還可以拓展為“引導式搜尋”,這是一種來自更高階皮層區域的反饋(比如關於被尋找的目標的知識)被用來權衡不同特徵的重要性,高權值的特徵才會被接納進入更高處理
水平的流程。

2 模型
模型以靜態的彩色影象、解析度通常為640×480的形式作為輸入。運用二元高斯金字塔建立了九個空間區域,它們依次地通過低通濾波器。對輸入影象進行二次取樣,形成排列為1:1(0級)到1:256(8級)的8°的水平和垂直的影象取樣。
每個特徵都通過一系列的線性“中心周圍”來計算,類似於視覺能容納的區域(圖一):典型神經元最敏感的會是整個視覺空間的一個小區域(中心),然而呈現在與中心點同軸的邊界和弱對抗區域(邊界)的刺激物抑制了神經元響應。這樣的一個對區域性空間不連續性十分敏感的結構非常適合檢測與周圍有明顯差異的區域性空間,而且這也是視網膜、外側膝狀體核和靈長類動物大腦視覺皮層的常規計演算法則。中心周圍是通過在精細和粗糙級別中的不同點的模型來實現的:這個中心點是一個在等級c∈{2,3,4}之中的畫素,並且周圍的畫素點等級在s = c + δ, δ ∈{3, 4}中。兩個圖譜之間的跨尺度差異,在下面表示為“ϴ”,通過內插到更精細的尺度和逐點減法來獲得。使用幾個尺度不僅對c而且對d = s - c產生真正的多尺度特徵提取,通過包括中心和周圍區域之間的不同大小比率(與以前使用的固定比率[5]相反)。
2.1早期視覺特徵的抽樣
在輸入影象中,用r、g、b分別表示紅、綠和藍的顏色通道,並且影象亮度I是通過I=(r+g+b)/3得到的。這裡的I用來建立高斯金字塔I(σ),其中σ∈[0..8]表示等級。為了從亮度中減弱色度,r、g、b通過I進行歸一化。然而,由於色調變化在非常低的亮度下是不可察覺的(因此不是顯著的),因此歸一化僅應用於I大於其整個影象的最大值的1/10的位置(其他位置產生零r,g ,和b)。四個廣泛調整的顏色通道被建立:
紅色:R = r-(g+b)/2;
綠色:G = g-(r+b)/2;
藍色:B = b-(r+g)/2;
黃色:Y = (r+g)/2 - |r-g|/2 - b(負數清零)。四個高斯金字塔R(σ),G(σ),B(σ),Y(σ)通過這些顏色通道被建立。
“中心”精細等級c和“周圍”粗糙等級s的差異產生特徵圖。第一個特徵集合關係到亮度對比度,這在哺乳動物中通過神經元的敏感檢測到亮環境中的黑中心、或者黑環境中的亮中心。這裡,兩種型別的敏感度在一組六個圖中同時被計算(運用一次矯正),其中,I(c,s),c∈{2,3,4},s=c+δ,δ∈{3,4}:
I(c,s)=|I(c)ϴI(s)| (1)
第二組圖譜用類似的方法構造顏色通道,這在視覺皮層中描繪了所謂的“color-double-opponent”(CDO)系統:在它們可接收到範圍內的中心,神經元被一種顏色刺激(例如,紅色)並且被另外一種顏色抑制(例如,綠色),然而在中心之外卻會體現出相反的現象。這樣的空間和色彩的對立在人類視覺大腦皮層中有以下組合中:紅/綠、綠/紅、藍/黃、黃/藍。據此,表RG(c,s)在這個模型同時計算出來紅/綠、綠/紅兩個對立組(2),同理表BY(c,s)表示藍/黃、黃
/藍兩個對立組合(3):
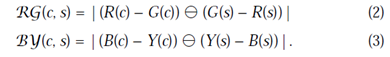
影象中區域性位置的方向資訊是通過利用方向Gabor金字塔從I中獲得(I即為第一個特徵圖Intensity),其中σ∈[0..8]表示引數範圍,θ∈{0°,45°,90°,135°}表示涉及到的方向。(Gabor濾波器是餘弦柵格和2D高斯包絡的產物,這個可部分可以約等於在靈長動物的定位選擇神經系統中,視覺皮層接收資訊的敏感度(脈衝響應))。方向特徵圖,O(c,s,θ),編碼為一個組,方向資訊在中心區域和周邊區域形成強烈對比:
O(c,s,θ)=|O(c,θ)ϴO(s,θ)| (4)
總之,我們計算出了42特徵圖:六個表示亮度,12個表示顏色,還有24個表示方向
2.2 顯著圖
顯著性圖的目的是通過顯著性的空間分佈來表示醒目度(conspicuity-saliency)或顯著度:在視野中每個位置用一個定量向量表示,引導注意位置的選擇。通過一個動態神經網路模型,特徵圖的組合可以向顯著性圖提供自下而上的輸入。
對不同的的特徵圖表示了不可比較的模態的先驗資訊,有不同的動態範圍和提取機制。42個特徵圖結合時,在一些特徵圖中表現非常強的顯著目標可能被其它更多的特徵圖的噪聲或不顯著的目標所掩蓋,被標記為噪聲、或者較弱顯著特徵的物體。
在缺少自上而下監督的情況下,採用一個歸一化操作運算元N(.),整體提升那些有部分強刺激峰值(醒目位置)的特徵圖,而整體抑制那些包含大量可比峰值響應,(圖二):

- 將所有圖的取值固定為[0,M],消除依賴於模態的幅值差異;
②計算圖中最大值M的位置和其他所有區域性極大值的平均值m;
- 整幅影象乘以(M-m)* (M-m)。
只考慮活動的區域性最大值,例如N(.)比較與對映圖譜中有意義的“活動點”相關的響應,而忽略同構區域。將整個對映圖譜中的最大活動與平均總體啟用相比較,可以衡量最活躍的位置與平均值之間的差異。當這種差異很大時,最活躍的位置就會脫穎而出,對映圖譜也會得到大力推廣。當差異很小時,對映圖譜不包含任何唯一的內容,並且被抑制。N(.)的設計背後的生物學動機是,它粗略地複製了皮質側抑制機制,在這種機制中,相鄰的相似特徵通過特定的、解剖學上定義的連線[15]相互抑制。
所有特徵圖聯合成為三個“顯著圖”,在顯著圖的等級(σ=4)時,表示`I亮度(5),表示`C顏色(6),表示`O方向(7)。它們是通過跨尺度加法“Å”獲得的,“Å”包括將每個對映圖譜縮小到第4級並逐點新增:

對於方向,首先通過組合給定θ的六個特徵圖建立四個中間圖,然後將它們組合成一個單一方向顯著性對映圖譜:

三個不同通道的建立,和他們的個體歸一化的動機是類似特徵為顯著性而激烈的競爭,不同的形式獨立的貢獻給顯著特徵圖。這三個顯著特徵圖歸一化並總結作為顯著圖的輸入S:
![]()
在任何所給的時間,顯著圖的最大值定義了最顯著的影象位置,該位置注意力的焦點具有指向作用。我們現在能夠簡單地把最活躍的位置作為模型下一次出現的點。但是,在神經元的實現過程中,我們在第四級把顯著性圖譜建模成2D層次結構的整合和解散的神經元。這些模型神經元由單個電容組成,其整合由突觸輸入,洩漏電導和電壓閾值提供的電荷。達到閾值時,會產生原型尖峰,電容電荷被分流到零[14]。顯著性圖譜以規模s = 4進入生物可信的2D“贏者通吃”(WTA)神經網路[4],[1],其中單位之間的突觸相互作用確保僅保留最活躍的位置,而所有其他地點被壓制。
在顯著性圖譜中的每個神經元從S中接受刺激性的輸入並且都是獨立的。電勢位於顯著性圖譜神經元最跳躍的位子上,因此增加非常快(這些神經元被用作純粹的積分器而不被釋放)。每一個神經元激發他相應的WTA神經元。所有的WTA神經元也都獨立的發展進化,直到某一個(勝者)第一個達到了閾值並且釋放。這觸發了三個同時發生的機制(圖3):
1)這個FOA轉變成為勝者神經元位置;
2) WTA的全域性抑制被觸發並完全抑制(重置)所有WTA神經元;
3)在具有FOA的大小和新位置的區域中,顯著性圖譜中的區域性抑制被瞬時啟用;這不僅通過允許下一個最突出的位置隨後成為贏家而產生FOA的動態轉變,而且還防止FOA立即返回到先前參加的位置。
這樣一個“返回抑制”已經被人類視覺心理物理學論證了。為了稍微偏向模型以隨後跳轉到空間上接近當前參加位置的顯著位置,在顯著性圖譜中,在FOA的近環境中瞬時啟用小激勵(Koch和Ullman的“接近偏好”規則[4])。
既然我們沒有模擬任何以後自上向下的注意力部分,所以FOA是一個簡單的圓盤,它的半徑修正為輸入影象的高和寬兩者之間的較小者的1/6。這個模擬神經元的時不變性、電導率和擊穿電壓被選擇,以便FOA從一個顯著特徵位置跳躍到下一個顯著特徵位置只需要大約只需要30-70ms(模擬時間),同時一個被注意的區域被抑制需要大約500-900ms(圖三),正如研究心理物理學得到的結果一樣。這些延遲的差異證明他是充裕去保證徹底瀏覽影象和阻止僅僅在有限的幾個位置上發生迴圈。在我們的試驗中,所有的引數都被修正,並且在整個影象研究中這個系統是穩定的。
2.3 和空間頻率容量模型比較
Reinagel和Zador利用一個跟蹤眼睛的裝置沿著眼睛的瀏覽路徑分析區域性空間頻率干擾,其中這個路徑在人們自由檢視灰度等級影象時形成的。他們發現在修正的位置上空間頻率容量平均值意義重大的高於隨機的位置。儘管眼睛軌跡能夠不同於在意志力控制下的注意力軌跡,視覺注意力常被認為preocculomotor機制,它能強烈的影響自由視野。因此,研究我們的模型是否也能線上Reinagel和Zador的發現也變的有興趣了起來。
我們構建一個簡單的空間頻率容量(SFC)的量度:在一個給定的位置上,對每個I(2)、R(2)、G(2)、B(2)和Y(2)取樣取出來一個16×16的影象,然後對這每個小影象進行快速傅立葉變換(FFTs)。對於每個影象塊兒,一個閾值用來計算不可忽視FFT係數;這個閾值和可感知的摩擦聲(1%對照)的FFT振幅相吻合。SFC的衡量值是這五個相應的影象塊的不可忽略係數的平均值。選擇影象塊兒的尺寸和比例使SFC量度對和我們模型的差不多的頻率和解析度比較敏感;而且,我們的SFC量度也在RGB通道和亮度中計算出來。利用這個量度,SFC表可以在4級的時候被建立,並且能夠和顯著特徵圖進行比較(圖四)。
3 結果和討論
儘管顯著特徵圖的概念在FOA模型中被廣泛的應用,微小的細節常常能夠給出解釋和提供動態效能。在這裡,我們將研究前饋特徵提取階段,對映圖譜的組合策略和顯著性對映的時間屬性如何有助於整體系統效能。
3.1總體效能
為了確保正常的執行,這個模型進行了大量圖片的測試;例如,按照對比度依次兌減的順序,展示了幾個有相同形狀的目標,但有著不同對比度的背景的圖片。這種模型被證明對於這種圖片(圖五)有著良好的魯棒性,尤其是對於噪聲的特性(比如它的顏色)沒有和目標的主特點產生直接衝突的圖片。
該模型能夠再現人類在一些突出任務[7]中的表現行為,使用圖2所示型別的影象。當一個目標從通過其獨特的性質和周圍的干擾因素區分出來(如圖2),顏色,強度或大小不同,它總是在首要顯示的位置,不管幹擾項的數目如何。反之,當目標僅僅由於特點的結合從干擾項中區分出來(例如,它是在紅色垂直柱和綠色水平柱的混合陣列中唯一一個紅色的垂直柱),找到目標的必要搜尋時間隨著干擾項的數量線性增長。這兩個結果在人類[7]得到了廣泛的觀察,接下來在第3.2節中加以討論。
我們還測試了真實影象的模型,從自然的戶外場景到藝術繪畫,使用N(.)來歸一化特徵圖(圖3和[17])。用許多這樣的影象,難以客觀地評價模型,因為沒有客觀參考可用於比較,觀察者們也許也會就哪個區域最為顯著產生分歧。然而,在所研究的所有影象中,大部分顯示出的區域都是顯著的目標,如面部,旗幟,人,建築物,或車輛。
對模型預測以本地的SFC的所述量度進行比較,以一個類似於Reinagel和Zador[18]的實驗中,使用與凸交通標誌(90張影象),一個紅色蘇打罐(104張影象),或者在車輛的緊急自然場景三角形符號(64張影象)。類似於Reinagel和扎多爾的調查結果,在參表示區域中,其SFC比平均SFC明顯高很多,通過在第八顯示區域從在首要顯示區域2.5±0.05下降至1.6±0.05的事實。雖然這個結果並不一定表示人眼的注視和模型的注意力軌跡之間的相似性,表明該模型和人類一樣,被吸引到影象中“資訊的”位置。根據普遍假設,具有越豐富的光譜內容的區域,可以提供的資訊就越多。對於大部分影象來說,SFC圖類似於顯著圖(例如,圖4.1)。然而,這兩種圖分析影象時,在照明和色彩(例如,由於斑點噪聲)方面有強烈的差異,儘管這些區域均表現出高SFC值,他們因為他們的均勻性(圖4.2和圖4.3)呈現出較低的顯著性。在這樣的影象中,顯著圖往往會與我們主觀感覺到的顯著的比例更加一致,對於258張分析的影象,所表現區域的SFC值明顯低於其最高SFC值,由第一表現區域的0.90±0.02下降到第八表現區域的0.55±0.05:雖然所顯示的模型SFC值很高,它們和最高SFC的區域相比較而言,就顯得不重要了。這大約可以結論性地說明,顯著點不只是一個區域SFC的測量方法。這種利用空間特點競爭進行計算的模型,可以主觀地抓獲明顯高於純粹的區域SFC測量。
3.2 強度和極限
我們提出了一個架構和元件模仿早期靈長類動物視覺特性的模型。儘管它結構簡單、特徵提取機制為前饋方式,該模型能夠在複雜的自然場景表現出色。例如,它可以迅速檢測各種形狀(圓形,三角形,正方形,矩形),顏色(紅,藍,白,橙,黑色),和紋理(字母標記,箭頭,條紋,圓)的顯著交通標誌,雖然它被設計的目的並非如此。這種優秀的表現更加堅固了一個想法,那就是一個獨特的著圖,從早期的視覺過程接收輸入,可以有效地引導靈長動物自下而上的注意力[4],[10],[5],[8 ]。從一個計算角度來看,這種方法的主要優勢在於它基於大規模相似的實踐,不僅在耗費計算的早期特徵提取階段,還在於注意力集中系統。比以前的基於廣泛的放鬆技巧[5]模型更進一步的是,我們的架構可以很容易地允許在專用硬體進行實時操作。
該模型預期效能的型別關鍵取決於一個因素:只有物件特徵的特徵圖中的至少一個得以表達,才能導致他的顯現,即,快速檢測獨立於干擾物件的數目[7]。沒有修改前期注意特徵提取的步驟,我們的模型無法檢測出特徵的連線性。雖然我們的系統會立即檢測出由其獨特的尺寸,強度,顏色,或方向與周圍環境區分出來的目標(我們已經實現了,因為他們已經很好地表徵初級視覺皮層的屬性),但是它無法檢測還未實現的顯著目標型別(例如,T路口或行尾字元,那些具體的神經探測器的存在仍有爭議)。為了簡單起見,我們也沒有用特徵圖實現任何復發機制,因此,不能再現輪廓填充和閉合,這對於一些型別的人眼識別[19]是至關重要的。此外,目前,我們的模型不包含任何大細胞運動通道,而這正是人類識別顯著特徵中發揮強有力作用的地方[5]。
一個鑑定的模型元件是N(.)的歸一化,它在任何情況下都為計算顯著特點提供了一種通用機制。通過模型執行所產生的顯著特徵度量,即使往往與區域SFC相關,更接近人類所分辨的顯著性,因為它執行了顯著區域之間的空間競爭。我們對N(.)前饋實現比以前提出的迭代計劃[5]更快,更簡單。從神經元上講,在條紋和紋外皮層[15]細胞非經典接受區域,空間競爭與已經觀察的N(.)具有類似的效果。
總之,我們已經提出了顯著性驅動的焦點視覺注意的一個概念簡單的計算模型。以生物洞察力作為其結構的指導,再現一些靈長類動物的視覺系統的效能被證明是非常效率的。這種方法對目標檢測的效率主要取決於實現的特徵型別。這裡提出的框架能夠通過隨後專用特徵圖的實施,很容易地適應任意任務。