
感受野 深度理解
知乎是個好東西,深入理解一些理念,靠部落格是不行的。
感受野計算和理解的內容參考自:https://zhuanlan.zhihu.com/p/44106492 / https://zhuanlan.zhihu.com/p/40267131
後兩個卷積的內容參考自: https://www.zhihu.com/question/54149221
目錄
五、從 感受野 分析 典型網路(vgg、resnet、rpn結構)
一、卷積後特徵圖維度的公式
首先,補充下計算卷積後特徵圖維度的公式:
N = (W − F + 2P )/S+1 (原圖大小-kenal+2pad)/步長 +1
- 輸出圖片大小為 N×N
- 輸入圖片大小 W×W
- Filter大小 F×F
- padding: P
- 步長 S
二:感受野介紹:
stride : 網路中的每一個層有一個strides,該strides是之前所有層stride的乘積,即:
感受野:cnn中的特徵圖上一點,相對於原圖的大小。
三、感受野的直觀感受 和 作用
下圖(該圖為了方便,將二維簡化為一維),這個三層的神經卷積神經網路,每一層卷積核的 ,
,那麼最上層特徵所對應的感受野就為如圖所示的7x7。*(看箭頭的時候從上往下反著看)
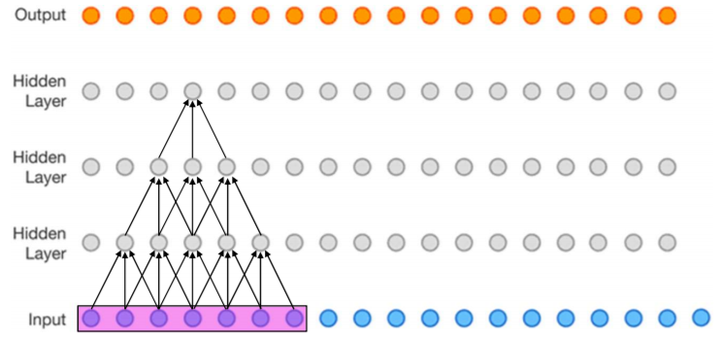
作用:這個重要的思想是在VGG的主要contribution( 3 個 3 x 3 的卷積層的疊加可以替代7*7的卷積,而這樣的設計不僅可以大幅度的減少引數,其本身帶有多次正則性質的 convolution map 能夠更容易學一個 generlisable, expressive feature space。這也是現在絕大部分基於卷積的深層網路都在用小卷積核的原因。)
- 小卷積可以代替大卷積層
- 密集預測task要求輸出畫素的感受野足夠的大,確保做出決策時沒有忽略重要資訊,一般也是越深越好
- 一般task要求感受野越大越好,如影象分類中最後卷積層的感受野要大於輸入影象,網路深度越深感受野越大效能越好
- 目標檢測task中設定anchor要嚴格對應感受野,anchor太大或偏離感受野都會嚴重影響檢測效能
用這種等效的思想從感受野上看:兩個堆疊的conv3x3感受野可以等於一個conv5x5,推廣之,一個多層卷積構成的FCN感受野等於一個conv r*r,即一個卷積核很大的單層卷積,其kernelsize=r,padding=P,stride=S。cnn從gap劃開,看成是FCN (全卷積網路)+MLP (多層感知機),前面提取特徵後面加個分類器,可以理解成sobel+svm唄~CNN是不是就沒那麼神祕了~)
再來一個二維的圖:

這裡面有兩個 3 x 3的的卷積,可以替代一個5*5的卷積。
四、感受野大小計算方式
其中 表示特徵感受野大小,
表示層數,
,
輸入層的: ,
,
。
- 第一層特徵,感受野為3

第1層感受野[1]
- 第二層特徵,感受野為5

第2層感受野[1]
- 第三層特徵,感受野為7
第3層感受野[1]
如果有dilated conv的話,計算公式為
五、從 感受野 分析 典型網路(vgg、resnet、rpn結構)
計算Faster R-CNN(vgg16)中conv5-3+RPN的感受野,RPN的結構是一個conv3x3+兩個並列conv1x1:

宣告: 輸入圖片224*224, r表示感受野 , S表示stride, P表示padding, P的計算可以通過反推 N = (W − F + 2P )/S+1
r = 1 +2 +2 )x2 +2+2 )x2 +2+2+2 )x2 +2+2+2 )x2 +2 = 156
S = 2x2x2x2 = 16
P = ((14-1)x16-224+228)/2 = 106
分佈方式為在paddding=106的輸入224x224影象上,大小為156x156的正方形感受野區域以stride=16平鋪。
接下來是Faster R-CNN+++和R-FCN等採用的重要backbone的ResNet,常見ResNet-50和ResNet-101,結構特點是block由conv1x1+conv3x3+conv1x1構成,下采樣block中conv3x3 s2影響感受野。先計算ResNet-50在conv4-6 + RPN的感受野 (為了寫起來簡單堆疊卷積層合併在一起):
r = 1 +2 +2x5 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 299
S = 2x2x2x2 = 16
P = ((14-1)x16-224+299)/2 = 141.5
P不是整數,表示conv7x7 s2卷積有多餘部分。分佈方式為在paddding=142的輸入224x224影象上,大小為299x299的正方形感受野區域以stride=16平鋪。
ResNet-101在conv4-23 + RPN的感受野:
r = 1 +2 +2x22 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 843
S = 2x2x2x2 = 16
P = ((14-1)x16-224+843)/2 = 413.5
分佈方式為在paddding=414的輸入224x224影象上,大小為843x843的正方形感受野區域以stride=16平鋪。
以上結果都可以反推驗證,並且與後一種方法結果一致。從以上計算可以發現一些的結論:
- 步進1的卷積層線性增加感受野,深度網路可以通過堆疊多層卷積增加感受野
- 步進2的下采樣層乘性增加感受野,但受限於輸入解析度不能隨意增加
- 步進1的卷積層加在網路後面位置,會比加在前面位置增加更多感受野,如stage4加捲積層比stage3的感受野增加更多
- 深度CNN的感受野往往是大於輸入解析度的,如上面ResNet-101的843比輸入解析度大3.7倍
- 深度CNN為保持解析度每個conv都要加padding,所以等效到輸入影象的padding非常大
六、 有效感受野
NIPS 2016論文Understanding the Effective Receptive Field in Deep Convolutional Neural Networks提出了有效感受野(Effective Receptive Field, ERF)理論,論文發現並不是感受野內所有畫素對輸出向量的貢獻相同,在很多情況下感受野區域內畫素的影響分佈是高斯,有效感受野僅佔理論感受野的一部分,且高斯分佈從中心到邊緣快速衰減,下圖第二個是訓練後CNN的典型有效感受野。



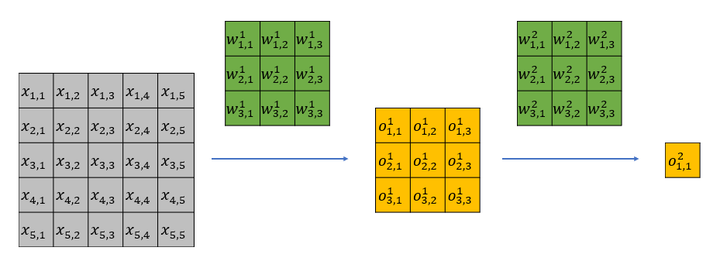
下面我從直觀上解釋一下有效感受野背後的原因。以一個兩層 ,
的網路為例,該網路的理論感受野為5,計算流程可以參加下圖。其中
為輸入,
為卷積權重,
為經過卷積後的輸出特徵。
很容易可以發現, 隻影響第一層feature map中的
;而
會影響第一層feature map中的所有特徵,即
。
第一層的輸出全部會影響第二層的 。
於是 只能通過
來影響
;而
能通過
來影響
。顯而易見,雖然
和
都位於第二層特徵感受野內,但是二者對最後的特徵
的影響卻大不相同,輸入中越靠感受野中間的元素對特徵的貢獻越大。
七、 論文中用法
ECCV2016的SSD論文指出更好的anchar的設定應該依據感受野:

ICCV2017的SFD依據有效感受野設定anchor並使其密集化,這一做法在RefineNet中延續:


DeepLab提出Atrous conv (帶孔卷積)高效控制感受野,而不增加引數數量和計算量:
- 分類
Xudong Cao寫過一篇叫《A practical theory for designing very deep convolutional neural networks》的technical report,裡面講設計基於深度卷積神經網路的影象分類器時,為了保證得到不錯的效果,需要滿足兩個條件:
Firstly, for each convolutional layer, its capacity of learning more complex patterns should be guaranteed; Secondly, the receptive field of the top most layer should be no larger than the image region.
其中第二個條件就是對卷積神經網路最高層網路特徵感受野大小的限制。
- 目標檢測
現在流行的目標檢測網路大部分都是基於anchor的,比如SSD系列,v2以後的yolo,還有faster rcnn系列。
基於anchor的目標檢測網路會預設一組大小不同的anchor,比如32x32、64x64、128x128、256x256,這麼多anchor,我們應該放置在哪幾層比較合適呢?這個時候感受野的大小是一個重要的考慮因素。
放置anchor層的特徵感受野應該跟anchor大小相匹配,感受野比anchor大太多不好,小太多也不好。如果感受野比anchor小很多,就好比只給你一隻腳,讓你說出這是什麼鳥一樣。如果感受野比anchor大很多,則好比給你一張世界地圖,讓你指出故宮在哪兒一樣。
《S3FD: Single Shot Scale-invariant Face Detector》這篇人臉檢測器論文就是依據感受野來設計anchor的大小的一個例子,文中的原話是
we design anchor scales based on the effective receptive field
《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》這篇論文在設計多尺度anchor的時候,依據同樣是感受野,文章的一個貢獻為
We introduce the Multiple Scale Convolutional Layers
(MSCL) to handle various scales of face via enriching
receptive fields and discretizing anchors over layers

