
pytorch yolov3 構建class Darknet 腦海中過一遍
從一個大體思路角度記錄一下學習的過程。細節不寫在這裡。
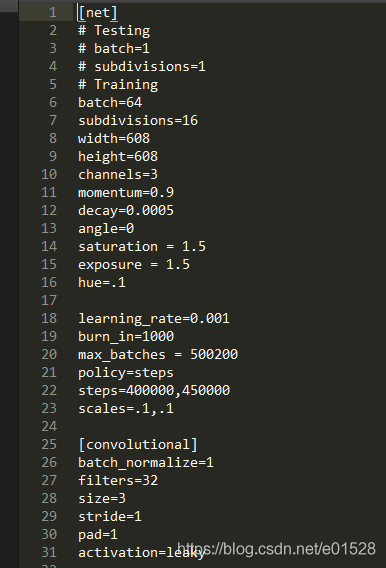
輸入檔案:只需要一個cfg檔案即可。
整體思路:先為網路定義一個Darknet類,然後裡面肯定有init,foward函式,這裡還有load_weight函式,在init初始化的時候,需要將利用cfg構建一個網路框架。具體關係在forward函式中。
更詳細的說法:
1. 轉換輸入:根據cfg檔案,先把每個block單獨儲存(作為字典),放到blocks(列表)當中。
2. 根據blocks中的block字典資訊可以建立module(nn.Sequential()),放到module_list(nn.moduleList)當中。其中涉及到不認識的層,route、shortcut和yolo層無法確定分給哪一個,我們先建立新的層,初始化在新層的init裡面,但不在新層類的forward函式。具體操作,再說。(其實是放到了實現最後一步的darknet類的forward當中)【其實還不直接寫到最初的forward裡面,這樣呼叫簡單】
為網路定義一個Darknet類
class Darknet(nn.Module): def __init__(self, cfgfile): super(Darknet, self).__init__() # 初試化self,先呼叫他的父類 nn.Module的init self.blocks = parse_cfg(cfgfile) # 存入blocks字典,呼叫blocks[i]["type"] self.net_info, self.module_list = create_modules(self.blocks) # 根據type,構建框架 def forward(self, x, CUDA): ... return detections def load_weights(self, weightfile): """ # 從下載的weight當中取出來,原本是1行,然後view_as 成 bn.裡面的維度 # 最後copy_到 bn.bias.data等 參與訓練 """ ...
一、在init的時候,需要利用cfg構建網路框架。需要建立兩個函式parse_cfg(cfgfile) 和 create_modules(self.blocks)
首先選用了cfg.txt,利用def parse_cfg(cfgfile):返回blocks。blocks _>[[{},{}...{}][{},{}...{}]...]]裡面每個dict儲存了每個的類別即block["type"],以及其他的關鍵字key,value = line.split("=") 最後blocks.append(block),然後def create_modules(blocks):
def parse_cfg(cfgfile):
...
block = {}
blocks = []
for line in lines:
if line[0] == "[":
if len(block) != 0: #
blocks.append(block) #
block = {} #
block["type"] = line[1:-1].rstrip()
else:
key,value = line.split("=")
block[key.rstrip()] = value.lstrip()
blocks.append(block)二 、 再定義forward函式: def forward(self, x, CUDA):
值得學習的有:
一、在init裡的create_module構架框架的時候。
module_list的應用,這一點在另外一篇部落格裡有寫。nn.moduleList 和Sequential由來、用法和例項 —— 寫網路模型。在迴圈前 module_list = nn.ModuleList(),構造blocks的迴圈 for index, x in enumerate(blocks[1:]):,裡面寫model=nn.Sequential()然後判斷是哪一種層,再module.add_module("conv_{0}".format(index), conv)新增進來,每次迴圈末尾,利用moduleList的方法module_list.append(module),然後迴圈。
在迴圈前還需要的是(也是構造模型值得學習的地方)需要定義輸入和輸出的filters,因為conv等層需要。總結為:看不同module的引數的需要。
# 迴圈前需要定義
module_list = nn.ModuleList() #大module列表
prev_filters = 3 #每一層輸入的filter
output_filters = [] #每一個層的輸出的filter
# 開始迴圈,不斷創造module,然後add_module進去,在append到module_list中
for index, x in enumerate(blocks[1:]):
...
module = nn.Sequential() #不斷創造新的module
if (x["type"] == "convolutional"):
filters= int(x["filters"]) #本層輸出的filter
conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias = bias)
module.add_module("conv_{0}".format(index), conv) #
module_list.append(module) #列表儲存所有module
prev_filters = filters #將下一層的輸入的filter 替換為 上一層的輸出的filter,
output_filters.append(filters) #儲存這一層的輸出,route等層需要二、是route層和yolo層以及shortcut層,如何根據nn.module新建這些層呢?
首先對於route和shortcut層只是對不同的層之間進行連線操作。所以不需要新的引數輸入。
class EmptyLayer(nn.Module):
def __init__(self):
super(EmptyLayer, self).__init__()但是yolo層用於predict每個anchor的概率涉及到了anchor。還是總結為看引數,輸入輸出。
所以yolo'層 def __init__(self, anchors):
class DetectionLayer(nn.Module):
def __init__(self, anchors):
super(DetectionLayer, self).__init__()
self.anchors = anchors具體的實現放在forward當中。通過迭代blocks(blocks是一個列表,裡面放著每一個block的字典)取出block字典,判斷如果是route需要對輸入的特徵圖x進行什麼操作,然後儲存i層輸入到output[i]。
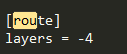
首先分析route層,兩種情況,一種是跳到倒數4層,對它進行操作; x = outputs[i -4]
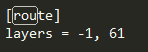
一種是對倒數1層和第61層進行合併操作,torch.cat((outputs[i -1],outputs[i + 61]),1) #nchw合併channel
其次shortcut比較簡單,就是純粹的一個把上一層和某一層相加 : x = outputs[i-1] + outputs[i+from_] #相加就好
最後是yolo層,比較複雜單開一個。
下面是forward的全部。
def forward(self, x, CUDA):
modules = self.blocks[1:]
outputs = {} #We cache the outputs for the route layer
write = 0
for i, module in enumerate(modules):
module_type = (module["type"])
if module_type == "convolutional" or module_type == "upsample":
x = self.module_list[i](x)
elif module_type == "route":
layers = module["layers"]
layers = [int(a) for a in layers]
if (layers[0]) > 0:
layers[0] = layers[0] - i
if len(layers) == 1:
x = outputs[i + (layers[0])]
else:
if (layers[1]) > 0:
layers[1] = layers[1] - i
map1 = outputs[i + layers[0]]
map2 = outputs[i + layers[1]]
x = torch.cat((map1, map2), 1)
elif module_type == "shortcut":
from_ = int(module["from"])
x = outputs[i-1] + outputs[i+from_]
elif module_type == 'yolo':
anchors = self.module_list[i][0].anchors
#Get the input dimensions
inp_dim = int (self.net_info["height"])
#Get the number of classes
num_classes = int (module["classes"])
#Transform
x = x.data
#將x由 n c w h _> n w*h*3 c
#batch_size, 3*85, grid_size, grid_size)——》(batch_size, grid_size*grid_size*3, 5+類別數量)
#在這個過程當中趁機 利用sigmod 將xywh改過來,因為需要xc和sigmod函式,迴歸嚒
x = predict_transform(x, inp_dim, anchors, num_classes, CUDA)
if not write: #if no collector has been intialised.
detections = x
write = 1
else:
detections = torch.cat((detections, x), 1)
outputs[i] = x
return detections