
Deep Learning(Ian Goodfellow) — Chapter1 Introduction
Deep Learning是大神Ian GoodFellow, Yoshua Bengio 和 Aaron Courville合著的深度學習的武功祕籍,涵蓋深度學習各個領域,從基礎到前沿研究。因為封面上有人工智慧生成的鮮花影象,人送外號“花書” 。該書系統地介紹了深度學習的基礎知識和後續發展,是一本值得反覆讀的好書。
這裡根據書的框架做筆記如下,方便以後回顧閱讀,加油!!!
1.0 引言
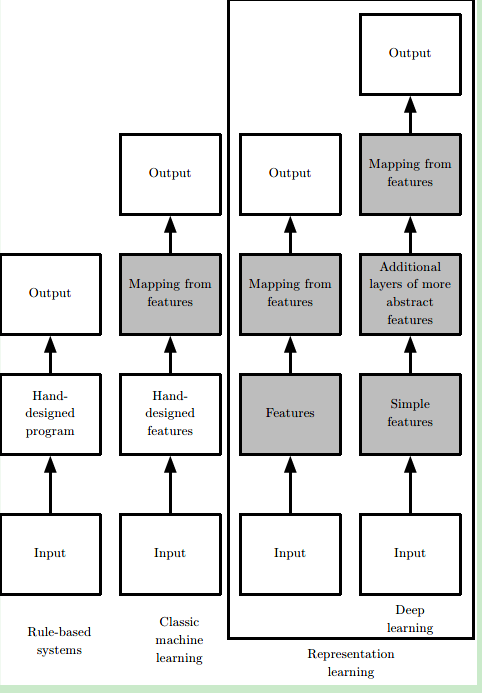
什麼是machine learning?在原始的AI系統中,定義不同的case使用不同的解決方法,這稱為“hard code”。進一步的AI系統需要一種去獲取知識的能力,也就是從原始資料中發現模(“Pattern”),這種能力就是machine learning
但是,一般的machine learning演算法嚴重依賴於資料的表示(representation),表示中包含的每份資訊又稱為feature。這又引發了一個新的問題,對於很多task,我們不知道應該提取什麼樣的特徵(只能經驗主義)。機器學習早期的時候十分依賴於已有的知識庫和人為的邏輯規則,需要人們花大量的時間去制定合理的邏輯判定,可以說是有多少人工,就有多少智慧。後來逐漸發展出一些簡單的機器學習方法例如logistic regression、naive bayes等,機器可以通過一些特徵來學習一定的模式出來,但這非常依賴於可靠的特徵,比如對於logistic regression用來輔助醫療診斷,我們無法將核磁共振影象直接輸入機器來作出診斷,而是醫生需要先做一份報告總結一些特徵
於是又有了representation learning,即使用machine learning不光光是學習reprsentation到output的對映(mapping),還要學習data到representation的對映。使用機器學習來發掘表示本身,而不僅僅把表示對映到輸出。人們發展出了表徵學習(representation learning),希望機器自己能夠提取出有意義的特徵而無需人為干預。
典型的表示學習演算法是autoencoder。encoder函式是將輸入資料對映成表示;decoder函式將表示映射回原始資料的格式。我們期望當輸入資料經過編碼器和解碼器之後儘可能多地保留資訊,同時希望新的表示有各種好的特性,這也是自編碼器的訓練目標。
representation learning的難點:表示是多種多樣的,一種表示學習演算法很難覆蓋多種層次和不同型別的表示。也就是多個因素同時影響觀察到的資料,從原始資料中提取如此高層次、抽象的特徵是非常困難的。
Deep Learning:使用多層次的結構,用簡單的表示來獲取高層的表示。這樣,解決了上面的問題(一種方法)。讓計算機通過較簡單概念構建複雜的概念。
這些表徵很有可能是隱含的、抽象的,比如影象識別中單個畫素可能沒有有效的資訊,更有意義的是若干畫素組成的邊,由邊組成的輪廓,進而由輪廓組成的物體。深度學習就是通過一層層的表徵學習,每層可能邏輯很簡單,但之後的層可以通過對前面簡單的層的組合來構建更復雜的表徵。經典的例子如多層感知機(multilayer perceptron),就是每個感知機的數理邏輯都很簡單,層內可以並行執行,層間順序執行,通過層層疊加實現更復雜的邏輯。深度學習的“深”可以理解為通過更多層來結合出更復雜的邏輯,這就完成了從輸入到內在層層表徵再由內在表徵到輸出的對映。
花書總體結構
花書可以大致分為三大部分:
- 機器學習基礎知識:涵蓋線性代數,概率論,數值計算和傳統機器學習基礎等知識。如果之前學過Andrew Ng的CS229的話基本可以跳過。
- 深度神經網路核心知識:屬於本書必讀部分,涵蓋前饋神經網路,卷積神經網路(CNN),遞迴神經網路(RNN) 等。
- 深度學習前沿:有一些前沿研究領域的介紹,如線性因子模型,表徵學習,生成模型等。
1.1 深度學習的歷史趨勢
目前為止深度學習已經經歷了三次發展浪潮:
1、20 世紀40 年代到60 年代深度學習的雛形出現在控制論(cybernetics)中,是從神經科學的角度出發的簡單線性模型,但侷限是無法學習非線性的異或函式。不過,這個時期為後來的深度學習打下基礎,我們現在訓練常用的隨機梯度下降演算法(stochastic gradient descent)就是源自處理這個時期的一種線性模型——自適應線性單元(Adaptive Linear Neuron)。雖然現在仍有媒體經常將深度學習與神經科學類比,但是由於我們對大腦工作機制的研究進展緩慢,所以實際上現在深度學習從業者已很少從神經科學中尋找靈感。;
2、20 世紀80 年代到90 年代深度學習表現為聯結主義(connectionism)或並行分佈處理,主要是強調很多的簡單的計算單位可以通過互聯進行更復雜的計算。這個時期成果很多,比如現在常用的反向傳播演算法(back propagation)還有自然語言處理中常用的LSTM(第十章講遞迴神經網路時詳談)都來自與這個時期。之後由於很多AI產品期望過高而又無法落地,研究熱潮逐漸退去。
3、直到2006 年,才真正以深度學習之名復興。由於軟硬體效能的提高,深度學習逐漸應用在各個領域,深度學習研究重整旗鼓。“深度”學習的名字成為主流,意在強調可以訓練更多層次更復雜的神經網路,“深”幫助我們開發更復雜的模型,解決更復雜的問題。
深度學習火起來的原因,主要是由於兩點:1.我們有更大量的資料進行訓練 2.我們有更好的軟硬體可以支援更復雜的模型。
隨著模型準確度的提高,深度學習也逐漸得到更廣泛的實際應用,比如影象識別,語音識別,機器翻譯等領域。像DeepMind AlphaGo這種強化學習方面的應用更是掀起了全民AI熱潮。與此同時,各種深度學習框架的出現如Caffe,Torch,Tensorflow等也方便更多人學習或利用深度學習模型。這些反過來又促進了深度學習行業的發展。
參考文獻:
https://zhuanlan.zhihu.com/p/38431213
http://www.deeplearningbook.org/
https://applenob.github.io/deep_learning_1.html