
【c語言】帶你真正走進指標的世界——指標的特性
當你看到這篇文章時,請忘掉你之前對指標的所有認知,什麼地址什麼的統統忘掉。
我來給你們重新構造一個全新的指標世界。

首先,我們知道,c語言中有很多種變數型別
int a ;
short b;
char c;
.
.
.而c語言中還有一種,可以在變數後加一個符號 “ *
int* a;
short* b;
char* c;這個變數就是c語言中的指標變數,指標的定義就是這麼簡單,不像網上或者某些書本上故弄玄虛地說著指標的定義
![]()
![]()
好像故意把我們往錯誤的道路使勁推似的......,其實指標並不難理解,下面由我來給大家解釋下指標的特性~

我們經常以這樣的方式給變數賦值

而事實上,我們這樣的賦值寫法只是一個簡略寫法

然而,雖然我們用的是簡略寫法,但是編譯器是允許我們這樣做的,然而,在給指標賦值時,就必須用完整的賦值方法。

如上圖為使用簡略寫法賦值,編譯器報錯

圖上為使用詳細寫法後的賦值,編譯通過
既然在變數之後加上 “ * ” 可以變成一個新的變數,那麼就可以2個或者無數個 “ * ” 來宣告更多的新變量了~

編譯安全通過~~



討論完如何給指標賦值之後我們討論下指標的寬度
#include <stdio.h>
#include <string.h>
int main()
{
char* a;
short* b;
int* c;
a = (char*)1;
b = (short*)2;
c = (int*)3;
return 0;
}
我們以上面程式碼為例
眾所周知,當圖上的變數 a、b、c 分別為char、short、int 時,所佔據的位元組數分別是1byte、2byte、4byte,而當我們在這些變數之後加上 “ * ” 時,所佔據的位元組數是否有所變化?

我們把c語言轉換成組合語言可以看出,三個指標變數雖然宣告不同,但是都是同樣佔據4位元組!
那麼我們的符號 “ * ” 如果不止一個的話搜佔據的位元組也是一樣的嗎?

我們以此程式碼為例
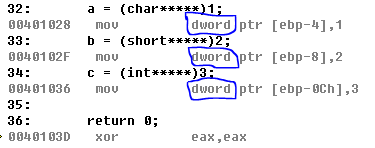
由c語言轉匯編語言可得知,帶 “ * ” 型別的變數寬度永遠都是4位元組,無論什麼型別,無論有多少個 “ * ”

當我們看到這樣的一個程式時
#include <stdio.h>
#include <string.h>
int main()
{
char a;
short b;
int c;
a = 100;
b = 100;
c = 100;
a++;
b++;
c++;
printf("%d %d %d",a,b,c);
return 0;
}
很容易就可以得出這樣的結果

而當代碼改為 指標 自增一時
#include <stdio.h>
#include <string.h>
int main()
{
char* a;
short* b;
int* c;
a = (char*)100;
b = (short*)100;
c = (int*)100;
a++;
b++;
c++;
printf("%d %d %d\n",a,b,c);
return 0;
}
得出的結果卻是這樣的

原因是因為:指標和常變數的計數方法不同,指標的加減法原則如下

所以,圖上程式碼中的 a 為char* 型別的變數,其值為 100 ,當自增一時,去掉符號 “*” 後剩下 char 型別,而 char 型別是 1位元組 的,所以是 100+1 = 101;
再者,圖上程式碼中的 c 為 int* 型別的變數,其值為 100 ,當自增一時,去掉符號 “*” 後剩下 int 型別,而 int 型別是 4位元組 的,所以是 100+4 = 104;
而當代碼是下面這個樣子的話
#include <stdio.h>
#include <string.h>
int main()
{
char** a;
short** b;
int** c;
a = (char**)100;
b = (short**)100;
c = (int**)100;
a++;
b++;
c++;
printf("%d %d %d\n",a,b,c);
return 0;
}
得到的結果是這樣的

這是因為程式碼中的 a 為char** 型別的變數,其值為 100 ,當自增一時,去掉符號 “*” 後剩下 char* 型別,而 char 型別是 4位元組 的,所以是 100+4 = 104;
另外兩個變數推理類似,所以,當是指標加上其他整數時
#include <stdio.h>
#include <string.h>
int main()
{
char* a;
short* b;
int* c;
a = (char*)100;
b = (short*)100;
c = (int*)100;
a = a+5;
b = b+5;
c = c+5;
printf("%d %d %d\n",a,b,c);
return 0;
}
其結果為:

由上面的推理可得知:程式碼中的 c 為int* 型別的變數,其值為 100 ,當+5時,去掉符號 “*” 後剩下 int 型別,而 int 型別是 4位元組 的,所以是 100+(5X4) = 120;
其他推理類似......

———————————————取值 “ * ” 和取址“ & ”————————————————
當我的程式碼是在這個樣子的時候
#include <stdio.h>
int main()
{
int x = 100;
int* p1 = &x;
printf("%d\n",p1);
return 0;
}得到的結果是這樣的

顯而易見,p1裡面儲存的是 X 的地址。然而,我為什麼不可以直接這樣寫呢?
#include <stdio.h>
int main()
{
int x = 100;
int* p1 = x;
printf("%d\n",p1);
return 0;
}編譯器尷尬又不失禮貌地回答說
![]()
根據編譯器所給出的原因,我們可以理解到,是因為賦值符號 ” = “ 兩邊的型別不相等(一個是 int 型,一個是 int * 型別)造成的,那麼為什麼加了 ” & “ 就可以了呢? 其實在編譯器裡面 , ” & “ 有個專業名字 ,叫做取址運算子,它的作用是在型別後面自動加上一顆 ” * “ ,使得變數看起來更高大上一點~~ ,所以如果是直接的 int* p1 = x,由於 x 是 int 型別的 ,而 p1 是 int* 型別的,所以不能把 x 的值賦值給 p1 ,這個時候就需要用到 ” & “ ,在 x 的型別 int 後面加上一顆 ” * “,使得兩者型別相同,有點類似於強制轉換。
和 “ & ” 相反的是 “ * ”,它在宣告變數時代表的是指標,但是在其他地方使用時是和 “ & ” 反過來的,它的作用是去掉一顆 “ * ” ,比如以下程式碼
#include <stdio.h>
int main()
{
int x = 100;
int* p1 = &x;
printf("%d\n",*p1);
return 0;
}得到的結果是

“ * ” 在程式碼的作用是,去掉 &x 的一顆星,也就相當於去掉 “ & ” 給加上來的那顆星,就會得到 int 型別的 x ,即int 型別的 100。