
python入門機器學習,3行程式碼搞定線性迴歸
本文著重是重新梳理一下線性迴歸的概念,至於幾行程式碼實現,那個不重要,概念明確了,程式碼自然水到渠成。
“機器學習”對於普通大眾來說可能會比較陌生,但是“人工智慧”這個詞簡直是太火了,即便是風雲變化的股市中,只要是與人工智慧、大資料、雲端計算相關的概念股票都會有很好的表現。機器學習是實現人工智慧的基礎,今天早上看了美國著名演員威爾斯密斯和世界最頂級的機器人進行對話的視訊,視訊中的機器人不論從語言還是表情都表達的非常到位,深感人工智慧真的離我們越來越近了,所以學習人工智慧前沿技術的基礎學科——機器學習就非常有必要了。
首先,機器學習是一個比較容易理解的概念,就是讓機器去模擬人的大腦去學習和思考,最終得出結論。舉個栗子:某初中期末考試,有一道考題是給出直角座標系中的兩個點a(x1,y1),b(x2,y2),根據所給點求取過a,b兩點的方程。初中文化的童鞋都知道,套用數學公式y=kx+b即可求出k和b就得到方程了。如何讓計算機求出方程呢,這裡就會涉及到非常簡單的線性迴歸方法,也就是把已知的a,b點給計算機,然後告訴它用線性迴歸來擬合所給點,這時電腦也會給出你k和b的結果。也就是說電腦也會用老師告訴你的那套數學計算方法來求取方程,只不過是求取過程被編寫成了計算機程式碼來執行。
上面這個小例子簡單的介紹了一下線性迴歸方法機器學習是怎麼來執行的,當然,在我們實際採用線性迴歸來進行機器學習時會更復雜一些,首先得需要掌握一些機器學習中線性迴歸的基本知識。首先了解一下機器學習的基礎知識,機器學習通常涉及到兩個重要的引數,包括特徵和標籤,如何對這兩個名詞進行理解呢?特徵我們可以認為是輸入機器學習模型中的自變數,標籤就是機器學習模型的輸出結果。類比上面的y=kx+b,x就是特徵,y就是標籤,僅此而已。
接下來我們需要認識一下在用python進行機器學習時候需要用到的包——sklearn包。這個包非常重要,裡面有非常多的模型演算法,簡單點說你想要通過一堆特徵得到一個模型時候你就直接呼叫這個包然後把特徵丟進去好了,說的簡單,其實在做的時候特費勁。。。但是基本過程就是這樣。
下面需要了解相關性這個概念,相關性分析會在很多機器學習中遇到,也就是研究事物之間發生有沒有關係,關係有多大這麼個事情。相關性有三種:分別包括正線性相關、負線性相關、非線性相關。如下圖所示:

上圖很直觀看到了線性相關到底是咋回事,也就是說資料的趨勢可以大致用一個直線來進行描述,雖然並不是所有的資料點都會在直線上,但是趨勢就是直線。即趨勢就是個最簡單的方程y=kx+b。
說到相關性,最值得關注的有兩個引數,1協方差,2相關係數。首先說協方差就是描述兩個變數變化情況的量,如下示意圖:
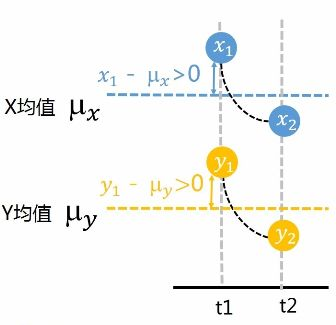
也就是你變大,我也變大,說明兩個變數是同向變化,此時協方差為正;一個變數變大一個變數變小,說明兩個變數是反向變化,協方差為負。從數值大小看,協方差數值越大,兩個變數的同向程度也就越大,反之亦然。但是有的時候協方差會差上萬倍,我們看到兩個數的變化程度仍然相似,這時協方差就不適合來描述兩個變數的相關性了。這時候我們需要用先關係數來描述兩個數的相關性。計算公式如下圖:
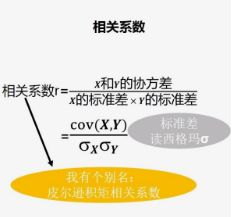
那麼如何理解相關係數呢?首先標準差描述了變數在整體變化過程中偏離平均值的幅度。協方差除以標準差也就是把協方差中的變數變化幅度對協方差的影響剔除掉了,這樣協方差也就標準化了,它反映的就是兩個變數每單位變化的情況。
接下來就是邏輯迴歸的套路問題了,如下圖:
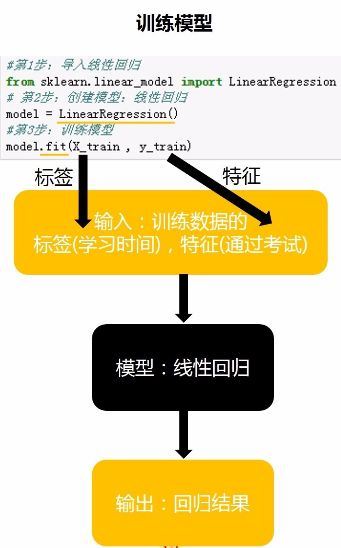
程式碼都很簡單,但是功能很強大,通過上述這三行程式碼就可以像上文舉的小栗子那樣直接求出k和b了,然後直線方程就出來了。雖然模型出來了,但是並不是所有的資料點都是完全在模型中,這時我們需要評估這個模型到底咋樣,靠不靠譜,就用如下公式來計算:
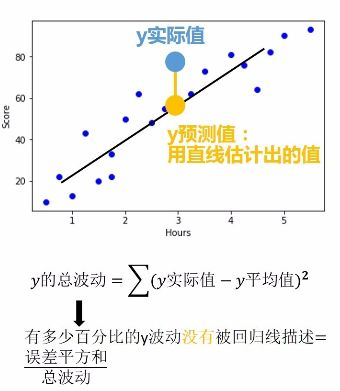
決定係數R平方有兩個功能:1、迴歸線擬合程度2、r平方越高,迴歸模型越精確。
以上就是線性迴歸的基本知識,相信你只要有一點點基本的統計知識加上一點點高中數學知識最後再有點耐心就會明白線性迴歸的原理。