
PID控制器開發筆記之十三:單神經元PID控制器的實現
神經網路是模擬人腦思維方式的數學模型。神經網路是智慧控制的一個重要分支,人們針對控制過程提供了各種實現方式,在本節我們主要討論一下采用單神經元實現PID控制器的方式。
1、單神經元的基本原理
單神經元作為構成神經網路的基本單位,具有自學習和自適應能力,且結構簡單而易於計算。接下來我們討論一下單神經元模型的基本原理。
(1)、單神經元模型
所謂單神經元模型,是對人腦神經元進行抽象簡化後得到一種稱為McCulloch-Pitts模型的人工神經元,如下圖所示。
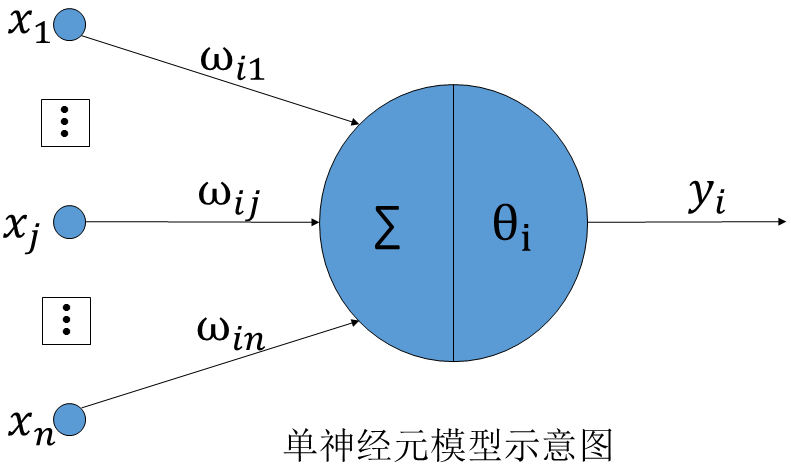
根據上圖所示,對於第i個神經元,x1、x2、……、xN是神經元接收到的資訊,ω1、ω2、……、ωN

其中,θi是神經元i的閾值。
而神經元i的輸出yi可以表示為其當前狀態的函式,這個函式我們稱之為啟用函式。一般表示如下:
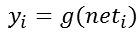
(2)、採用的學習規則
學習是神經網路的基本特徵,而學習規則是實現學習過程的基本手段。學習規則主要實現對神經元之間連線強度的修正,即修改加權值。而學習過程可分為有監督學習和無監督學習兩類。它們的區別簡單的說,就是是否引入期望輸出參與學習過程,引入了則稱之為有督導學習。較為常用的學習規則有三種:
a、無監督Hebb學習規則
Hebb學習是一類相關學習,它的基本思想是:如果神經元同時興奮,則它們之間的連線強度的增強與它們的激勵的乘積成正比。以Oi表示單元i的啟用值,以Oj表示單元j的啟用值,以ωij表示單元j到單元i的連線強度,則Hebb學習規則可用下式表示:
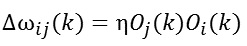
b、有監督Delta學習規則
在Hebb學習規則中,引入教師訊號,將式Oj換成網路期望目標輸出dj和網路實際輸出Oj之差,即為有監督Delta學習規則,即:
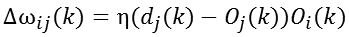
c、有監督Hebb學習規則
將無監督Hebb學習規則和有監督Delta學習規則兩者結合起來,就組成有監督Hebb學習規則,即:
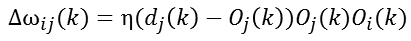
在以上各式中,η稱之為學習速度。
2、單神經元PID的基本原理
在前面我們說明了單神經元的基本原理,接下來我們討論如何將其應用的PID控制中。前面我們已經知道了神經元的輸入輸出關係,在這裡我們考慮PID演算法的增量型表示式:
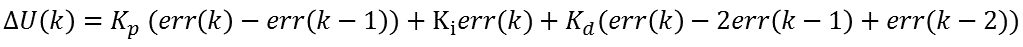
若是我們記:x1(k)=err(k),x2(k)=err(k)- err(k-1),x3(k)=err(k)- 2err(k-1)+err(k-2),同時將比例、積分、微分系數看作是它們對應的加權,並記為ωi(k)。同時我們引進一個比例係數K,則可將PID演算法的增量型公式改為:
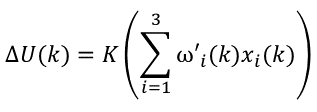
其中,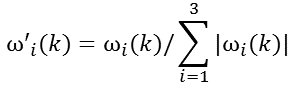
我們將PID的增量公式已經改為單神經元的輸入輸出表達形式,還需要引進相應的學習規則就可以得到單神經元PID控制器了。在這裡我們採用有監督Hebb學習規則於是可以得到學習過程:
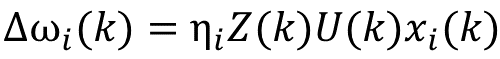
從學習規則的定義,我們知道在上式中,Z(k)= err(k)。而U(k)= U(k-1)+∆U(k),ω(k)= ω(k-1)+∆ω(k)。到這裡實際上已經得到了單神經元PID的演算法描述。
3、單神經元PID的軟體實現
有了前面的準備,我們就可以開始編寫基於單神經元的PID控制程式了。首先依然是定義一個單神經元的PID結構體:
1 /*定義結構體和公用體*/ 2 3 typedef struct 4 5 { 6 7 float setpoint; /*設定值*/ 8 9 float kcoef; /*神經元輸出比例*/ 10 11 float kp; /*比例學習速度*/ 12 13 float ki; /*積分學習速度*/ 14 15 float kd; /*微分學習速度*/ 16 17 float lasterror; /*前一拍偏差*/ 18 19 float preerror; /*前兩拍偏差*/ 20 21 float deadband; /*死區*/ 22 23 float result; /*輸出值*/ 24 25 float output; /*百分比輸出值*/ 26 27 float maximum; /*輸出值的上限*/ 28 29 float minimum; /*輸出值的下限*/ 30 31 float wp; /*比例加權係數*/ 32 33 float wi; /*積分加權係數*/ 34 35 float wd; /*微分加權係數*/ 36 37 }NEURALPID;
接下來在使用PID物件之前依然需要對它進行初始化操作,以保證在未修改引數的值之前,PID物件也是可用的。這部分初始化比較簡單,與前面的各類PID物件的初始化類似。
1 /* 單神經元PID初始化操作,需在對vPID物件的值進行修改前完成 */ 2 3 /* NEURALPID vPID,單神經元PID物件變數,實現資料交換與儲存 */ 4 5 /* float vMax,float vMin,過程變數的最大最小值(量程範圍) */ 6 7 void NeuralPIDInitialization(NEURALPID *vPID,float vMax,float vMin) 8 9 { 10 11 vPID->setpoint=vMin; /*設定值*/ 12 13 14 15 vPID->kcoef=0.12; /*神經元輸出比例*/ 16 17 vPID->kp=0.4; /*比例學習速度*/ 18 19 vPID->ki=0.35; /*積分學習速度*/ 20 21 vPID->kd=0.4; /*微分學習速度*/ 22 23 24 25 vPID->lasterror=0.0; /*前一拍偏差*/ 26 27 vPID->preerror=0.0; /*前兩拍偏差*/ 28 29 vPID->result=vMin; /*PID控制器結果*/ 30 31 vPID->output=0.0; /*輸出值,百分比*/ 32 33 34 35 vPID->maximum=vMax; /*輸出值上限*/ 36 37 vPID->minimum=vMin; /*輸出值下限*/ 38 39 vPID->deadband=(vMax-vMin)*0.0005; /*死區*/ 40 41 42 43 vPID->wp=0.10; /*比例加權係數*/ 44 45 vPID->wi=0.10; /*積分加權係數*/ 46 47 vPID->wd=0.10; /*微分加權係數*/ 48 49 }
初始化之後,我們就可以呼叫該物件進行單神經元PID調節了。前面我們已經描述過演算法,下面我們來實現它:
1 /* 神經網路引數自整定PID控制器,以增量型方式實現 */ 2 3 /* NEURALPID vPID,神經網路PID物件變數,實現資料交換與儲存 */ 4 5 /* float pv,過程測量值,物件響應的測量資料,用於控制反饋 */ 6 7 void NeuralPID(NEURALPID *vPID,float pv) 8 9 { 10 11 float x[3]; 12 13 float w[3]; 14 15 float sabs 16 17 float error; 18 19 float result; 20 21 float deltaResult; 22 23 24 25 error=vPID->setpoint-pv; 26 27 result=vPID->result; 28 29 if(fabs(error)>vPID->deadband) 30 31 { 32 33 x[0]=error; 34 35 x[1]=error-vPID->lasterror; 36 37 x[2]=error-vPID->lasterror*2+vPID->preerror; 38 39 40 41 sabs=fabs(vPID->wi)+fabs(vPID->wp)+fabs(vPID->wd); 42 43 w[0]=vPID->wi/sabs; 44 45 w[1]=vPID->wp/sabs; 46 47 w[2]=vPID->wd/sabs; 48 49 50 51 deltaResult=(w[0]*x[0]+w[1]*x[1]+w[2]*x[2])*vPID->kcoef; 52 53 } 54 55 else 56 57 { 58 59 deltaResult=0; 60 61 } 62 63 64 65 result=result+deltaResult; 66 67 if(result>vPID->maximum) 68 69 { 70 71 result=vPID->maximum; 72 73 } 74 75 if(result<vPID->minimum) 76 77 { 78 79 result=vPID->minimum; 80 81 } 82 83 vPID->result=result; 84 85 vPID->output=(vPID->result-vPID->minimum)*100/(vPID->maximum-vPID->minimum); 86 87 88 89 //單神經元學習 90 91 NeureLearningRules(vPID,error,result,x); 92 93 94 95 vPID->preerror=vPID->lasterror; 96 97 vPID->lasterror=error; 98 99 }
前面的演算法分析中,我們就是將增量型PID演算法的表示式轉化為單神經元PID公式的。二者最根本的區別在於單神經元的學習規則演算法,我們採用了有監督Hebb學習規則來實現。
1 /*單神經元學習規則函式*/ 2 3 static void NeureLearningRules(NEURALPID *vPID,float zk,float uk,float *xi) 4 5 { 6 7 vPID->wi=vPID->wi+vPID->ki*zk*uk*xi[0]; 8 9 vPID->wp=vPID->wp+vPID->kp*zk*uk*xi[1]; 10 11 vPID->wd=vPID->wd+vPID->kd*zk*uk*xi[2]; 12 13 }
至此,單神經元PID演算法就實現了,當然有很多進一步優化的方式,都是對學習規則演算法的改進,因為改進了學習規則,自然就改進了單神經元PID演算法。
4、單神經元PID總結
前面我們已經分析並實現了單神經元PID控制器,在本節我們來對它做一個簡單的總結。
與普通的PID控制器一樣,引數的選擇對調節的效果有很大影響。對單神經元PID控制器來說,主要是4個引數:K、ηp、ηi、ηd,我們總結一下相關引數選取的一般規律。
(1)對連線強度(權重ω)初始值的選擇並無特殊要求。
(2)對階躍輸入,若輸出有大的超調,且多次出現正弦衰減現象,應減少增益係數K,維持學習速率ηp、ηi、ηd不變。若上升時間長,而且無超調,應增大增益係數K以及學習速率ηp、ηi、ηd。
(3)對階躍輸入,若被控物件產生多次正弦衰減現象,應減少比例學習速率ηp,而其它引數保持不變。
(4)若被控物件響應特性出現上升時間短,有過大超調,應減少積分學習速率ηi,而其它引數保持不變。
(5)若被控物件上升時間長,增大積分學習速率ηi又會導致超調過大,可適當增加比例學習速率ηp,而其它引數保持不變。
(6)在開始調整時,微分學習速率ηd應選擇較小值,在調整比例學習速率ηp、積分學習速率ηi和增益係數K使被控物件達到較好特性後,再逐漸增加微分學習速率ηd,而其它引數保持不變。
(7)K是系統最敏感的引數,K值的變化相當於P、I、D三項同時變化。應在開始時首先調整K,然後再根據需要調整學習速率。
在單神經元PID控制器中,上述這些引數對調節效果的影響如何呢?一般情況下具有如下規律。
(1)在積分學習率、微分學習率不變的情況下,比例係數學習率越大則超調量越小,但是響應速度也會越慢;
(2)在比例學習率、微分學習率不變的情況下,積分系數學習率越大則響應會越快,但是超調量也會越大。
(3)在比例學習率、積分學習率不變的情況下,微分學習率對單神經元PID控制器的控制效果影響不大。
最後我們需要明白,單神經元PID演算法是利用單神經元的學習特性,來智慧的調整PID控制過程。單神經元可以實現自學習,這正好可以彌補傳統PID演算法的不足。正如前面所說,學習是它的最大特點,那麼不同的學習演算法對其效能的影響會很大,所以改進學習規則演算法對提高效能有很大幫助。
歡迎關注:
