
python實現併發爬蟲
在進行單個爬蟲抓取的時候,我們不可能按照一次抓取一個url的方式進行網頁抓取,這樣效率低,也浪費了cpu的資源。目前python上面進行併發抓取的實現方式主要有以下幾種:程序,執行緒,協程。程序不在的討論範圍之內,一般來說,程序是用來開啟多個spider,比如我們開啟了4程序,同時派發4個spider進行網路抓取,每個spider同時抓取4個url。
所以,我們今天討論的是,在單個爬蟲的情況下,儘可能的在同一個時間併發抓取,並且抓取的效率要高。
一.順序抓取
順序抓取是最最常見的抓取方式,一般初學爬蟲的朋友就是利用這種方式,下面是一個測試程式碼,順序抓取8個url,我們可以來測試一下抓取完成需要多少時間:
HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept-Encoding': 'gzip, deflate',}
URLS = ['http://www.cnblogs.com/moodlxs/p/3248890.html
我們直接採用內建的time.time()來計時,較為粗略,但可以反映大概的情況。下面是順序抓取的結果計時:

可以從圖片中看到,顯示的順序與urls的順序是一模一樣的,總共耗時為7.763269901275635秒,一共8個url,平均抓取一個大概需要0.97秒。總體來看,還可以接受。
二.多執行緒抓取
執行緒是python內的一種較為不錯的併發方式,我們也給出相應的程式碼,並且為每個url建立了一個執行緒,一共8執行緒併發抓取,下面的程式碼:
下面是我們執行8執行緒的測試程式碼:
HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept-Encoding': 'gzip, deflate',}
URLS = ['http://www.cnblogs.com/moodlxs/p/3248890.html',
'https://www.zhihu.com/topic/19804387/newest',
'http://blog.csdn.net/yueguanghaidao/article/details/24281751',
'https://my.oschina.net/visualgui823/blog/36987',
'http://blog.chinaunix.net/uid-9162199-id-4738168.html',
'http://www.tuicool.com/articles/u67Bz26',
'http://rfyiamcool.blog.51cto.com/1030776/1538367/',
'http://itindex.net/detail/26512-flask-tornado-gevent']
def thread():
from threading import Thread
import requests
import time
urls = URLS
headers = HEADERS
headers['user-agent'] = "Mozilla/5.0+(Windows+NT+6.2;+WOW64)+AppleWebKit/537.36+" \
"(KHTML,+like+Gecko)+Chrome/45.0.2454.101+Safari/537.36"
def get(url):
try:
r = requests.get(url, allow_redirects=False, timeout=2.0, headers=headers)
except:
pass
else:
print(r.status_code, r.url)
print(u'多執行緒抓取')
ts = [Thread(target=get, args=(url,)) for url in urls]
starttime= time.time()
for t in ts:
t.start()
for t in ts:
t.join()
endtime=time.time()
print(endtime-starttime)
thread()
多執行緒抓住的時間如下:
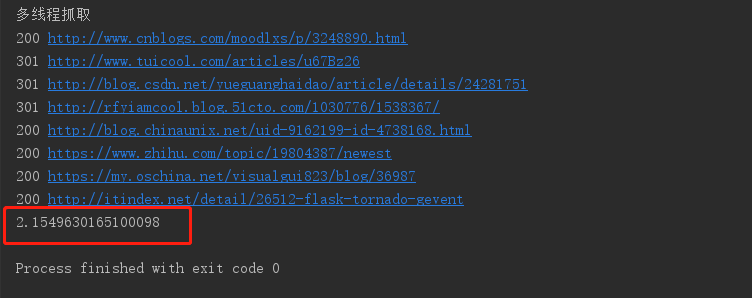
可以看到相較於順序抓取,8執行緒的抓取效率明顯上升了3倍多,全部完成只消耗了2.154秒。可以看到顯示的結果已經不是urls的順序了,說明每個url各自完成的時間都是不一樣的。執行緒就是在一個程序中不斷的切換,讓每個執行緒各自執行一會,這對於網路io來說,效能是非常高的。但是執行緒之間的切換是挺浪費資源的。
三.gevent併發抓取
gevent是一種輕量級的協程,可用它來代替執行緒,而且,他是在一個執行緒中執行,機器資源的損耗比執行緒低很多。如果遇到了網路io阻塞,會馬上切換到另一個程式中去執行,不斷的輪詢,來降低抓取的時間
下面是測試程式碼:
HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept-Encoding': 'gzip, deflate',}
URLS = ['http://www.cnblogs.com/moodlxs/p/3248890.html',
'https://www.zhihu.com/topic/19804387/newest',
'http://blog.csdn.net/yueguanghaidao/article/details/24281751',
'https://my.oschina.net/visualgui823/blog/36987',
'http://blog.chinaunix.net/uid-9162199-id-4738168.html',
'http://www.tuicool.com/articles/u67Bz26',
'http://rfyiamcool.blog.51cto.com/1030776/1538367/',
'http://itindex.net/detail/26512-flask-tornado-gevent']
def main():
"""
gevent併發抓取
"""
import requests
import gevent
import time
headers = HEADERS
headers['user-agent'] = "Mozilla/5.0+(Windows+NT+6.2;+WOW64)+AppleWebKit/537.36+" \
"(KHTML,+like+Gecko)+Chrome/45.0.2454.101+Safari/537.36"
urls = URLS
def get(url):
try:
r = requests.get(url, allow_redirects=False, timeout=2.0, headers=headers)
except:
pass
else:
print(r.status_code, r.url)
print(u'基於gevent的併發抓取')
starttime= time.time()
g = [gevent.spawn(get, url) for url in urls]
gevent.joinall(g)
endtime=time.time()
print(endtime - starttime)
main()
協程的抓取時間如下:

正常情況下,gevent的併發抓取與多執行緒的消耗時間差不了多少,但是可能是我網路的原因,或者機器的效能的原因,時間有點長......,請各位小主在自己電腦進行跑一下看執行時間
四.基於tornado的coroutine併發抓取
tornado中的coroutine是python中真正意義上的協程,與python3中的asyncio幾乎是完全一樣的,而且兩者之間的future是可以相互轉換的,tornado中有與asyncio相相容的介面。
下面是利用tornado中的coroutine進行併發抓取的程式碼:
利用coroutine編寫併發略顯複雜,但這是推薦的寫法,如果你使用的是python3,強烈建議你使用coroutine來編寫併發抓取。
下面是測試程式碼:
HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept-Encoding': 'gzip, deflate',}
URLS = ['http://www.cnblogs.com/moodlxs/p/3248890.html',
'https://www.zhihu.com/topic/19804387/newest',
'http://blog.csdn.net/yueguanghaidao/article/details/24281751',
'https://my.oschina.net/visualgui823/blog/36987',
'http://blog.chinaunix.net/uid-9162199-id-4738168.html',
'http://www.tuicool.com/articles/u67Bz26',
'http://rfyiamcool.blog.51cto.com/1030776/1538367/',
'http://itindex.net/detail/26512-flask-tornado-gevent']
import time
from tornado.gen import coroutine
from tornado.ioloop import IOLoop
from tornado.httpclient import AsyncHTTPClient, HTTPError
from tornado.httpclient import HTTPRequest
#urls與前面相同
class MyClass(object):
def __init__(self):
#AsyncHTTPClient.configure("tornado.curl_httpclient.CurlAsyncHTTPClient")
self.http = AsyncHTTPClient()
@coroutine
def get(self, url):
#tornado會自動在請求首部帶上host首部
request = HTTPRequest(url=url,
method='GET',
headers=HEADERS,
connect_timeout=2.0,
request_timeout=2.0,
follow_redirects=False,
max_redirects=False,
user_agent="Mozilla/5.0+(Windows+NT+6.2;+WOW64)+AppleWebKit/537.36+\
(KHTML,+like+Gecko)+Chrome/45.0.2454.101+Safari/537.36",)
yield self.http.fetch(request, callback=self.find, raise_error=False)
def find(self, response):
if response.error:
print(response.error)
print(response.code, response.effective_url, response.request_time)
class Download(object):
def __init__(self):
self.a = MyClass()
self.urls = URLS
@coroutine
def d(self):
print(u'基於tornado的併發抓取')
starttime = time.time()
yield [self.a.get(url) for url in self.urls]
endtime=time.time()
print(endtime-starttime)
if __name__ == '__main__':
dd = Download()
loop = IOLoop.current()
loop.run_sync(dd.d)
抓取的時間如下:

可以看到總共花費了128087秒,而這所花費的時間恰恰就是最後一個url抓取所需要的時間,tornado中自帶了檢視每個請求的相應時間。我們可以從圖中看到,最後一個url抓取總共花了1.28087秒,相較於其他時間大大的增加,這也是導致我們消耗時間過長的原因。那可以推斷出,前面的併發抓取,也在這個url上花費了較多的時間。
總結:
以上測試其實非常的不嚴謹,因為我們選取的url的數量太少了,完全不能反映每一種抓取方式的優劣。如果有一萬個不同的url同時抓取,那麼記下總抓取時間,是可以得出一個較為客觀的結果的。
並且,已經有人測試過,多執行緒抓取的效率是遠不如gevent的。所以,如果你使用的是python2,那麼我推薦你使用gevent進行併發抓取;如果你使用的是python3,我推薦你使用tornado的http客戶端結合coroutine進行併發抓取。從上面的結果來看,tornado的coroutine是高於gevent的輕量級的協程的。但具體結果怎樣,我沒測試過。