
keras學習筆記(三)
資料歸一化
通過上次對cifar10資料集分類的任務,我的分類精度在0.79,但是當我對輸入的資料做了歸一化後,精度達到了0.99,實現的語句如下:
X_train = X_train.astype('float32')/255
X_test = X_test.astype('float32')/255
Y_train =Y_train.reshape(Y_train.shape[0])/10
Y_test = Y_test.reshape(Y_test.shape[0])/10對輸入進行歸一化處理。對標籤也進行歸一化處理。是資料預處理的一種常見的手段。
資料歸一化與標準化存在一定區別,歸一化是資料標準化的一種典型做法,即將資料統一對映到[0,1]區間上. 資料的標準化是指將資料按照比例縮放,使之落入一個特定的區間.
歸一化最明顯的在神經網路中的影響有如下幾個方面:
1.有利於初始化的進行
2.避免給梯度數值的更新帶來數字的問題
3.有利於學習率的調整
4.加快尋找最優解的速度
上篇部落格說了上面那段是自己寫的,下面那段是網上別人寫的。我自己寫的進行了標準化前是0.79的精度,標準化後是0.99的精度,很顯然看出資料標準化對精度是有一定影響的。但是後面的那段我並沒有看到有資料歸一化,結果仍然能達到0.99.暫時還不清楚原因。可能是我選用了不同的損失函式的原因吧,可以自己進行更改驗證。
做了歸一化後可以使各個特徵都集中在固定的區間內,為什麼可以加快優化速度和學習率的調整呢?拿簡單的房價擬合問題來講,一個房子有很多個特徵,比如說面積,距離市中心的距離(km),臥室數量,樓層等等特徵。但是面積的數值較大(100-200),臥室數量一般為2-4,距離市中心距離(1-10),這麼多特徵,數值特別分散,如果使用統一的學習率,那麼每次如果距離減小一點點,可能相對於距離來說從3減到2.5變化很明顯,但是同樣的對於面積從200減到199.5變化速度太慢了。所以,將所有的正壓縮到同樣大小的空間中,這樣可以加快優化速度。
批量標準化(BatchNormalization)
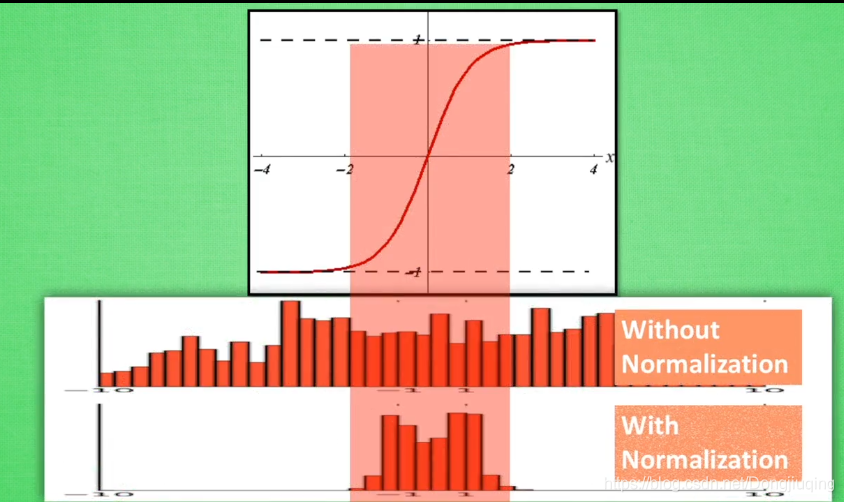
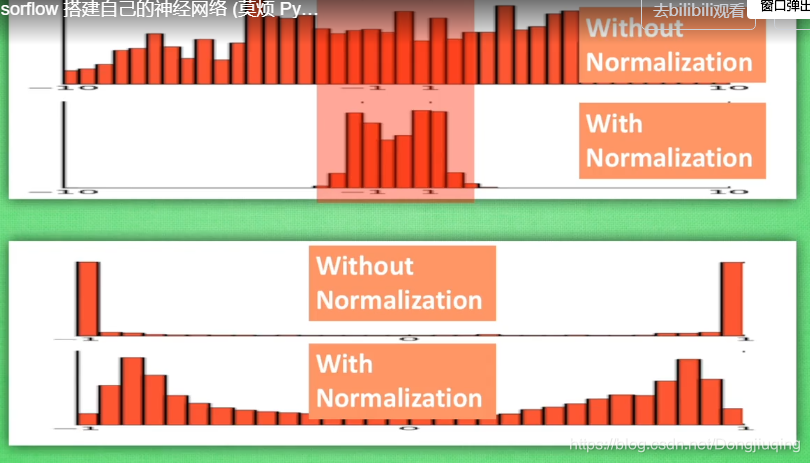
下面是批量標準化的兩張圖,這兩張圖說明了為什麼要進行批量標準化(BatchNormalization)。批量標準化可以用於隱藏層中。進行了標準化後可以讓特徵集中分佈在中央。然後經過一個sigmoid或者tanh的處理,這樣可以得到一個很好的值,想象一下,如果一個特徵值為3,一個特徵為30,經過tanh處理後,得到的值分別為0.96和0.99,這就相當於我的神經網路對輸入得資料缺少了感知能力。但是如果標準化到一定的區間內,比如把這個範圍縮小10倍,得到了0.3和3兩個特徵值,在經過啟用函式處理,那麼處理過後的結果可能就是0.2和0.96,這樣有利於更深層次的前向和反向傳播。網路搭的越深,往往後面梯度就消失了,因為特徵值太大了,因此加入BN層可以使網路得到更加有效的資料。
用keras寫一個GAN網路:
import keras
from keras import layers
import numpy as np
import os
from keras.preprocessing import image
pre_data=32
height = 32
width = 32
channels = 3
#獲取資料
(x_train,y_train),(x_test,y_test)=keras.datasets.cifar10.load_data()
x_train = x_train[y_train.flatten() == 5]
x_test = x_test [y_test.flatten() == 5]
#資料標準化
x_train=x_train.reshape((x_train.shape[0],)+(height,width,channels)).astype('float32')/255
x_test=x_test.reshape((x_test.shape[0],)+(height,width,channels)).astype('float32')/255
#構建生成器網路(從輸入到輸出的方式構建)generator_network
generator_input=keras.Input(shape=(pre_data,)) #generator_input.shape=(?, 32)
#用一個全連線層把相關特徵提出來,用16*16*128=32768個特徵。方便之後做卷積
x=layers.Dense(32768)(generator_input)#x.shape=(?, 32768)
x=layers.ReLU()(x)
x=layers.Reshape((16,16,128))(x)#x.shape=(?, 16, 16, 128)
#之後就可以做卷積了
x = layers.Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = layers.ReLU()(x)
x = layers.Conv2D(filters=256, kernel_size=5, padding='same')(x)
x = layers.ReLU()(x)
#上取樣,用Conv2DTranspose,從16*16跨達到32*32
x = layers.Conv2DTranspose(filters=256, kernel_size=4, strides=2, padding='same')(x)
x = layers.ReLU()(x)
x = layers.Conv2D(filters=256, kernel_size=5, padding='same')(x)
x = layers.ReLU()(x)
#生成32*32*3的圖片
x = layers.Conv2D(filters = 3, kernel_size=7, padding='same')(x)
x = layers.Activation('tanh')(x)
generator = keras.models.Model(generator_input, x)
generator.summary()#列印生成網路
#構建判別器網路discriminator_network
discriminator_input = layers.Input(shape=(height, width, channels))#輸入的是32*32*3的圖片
x = layers.Conv2D(filters=128, kernel_size=3 ,padding='same')(discriminator_input)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(filters=128, kernel_size=4 , strides=2,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(filters=128, kernel_size=4 , strides=2,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(filters=128, kernel_size=4 , strides=2,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.4)(x)#新增一個Dropout層
x = layers.Dense(1, activation = 'sigmoid')(x)#輸出一個一維的概率值
discriminator = keras.models.Model(discriminator_input, x)
discriminator.summary()#列印判別網路
#對判別器選用了優化器,損失函式
discriminator_optimizer = keras.optimizers.RMSprop(lr=0.0008, clipvalue=1.0, decay=1e-8)
discriminator.compile(optimizer=discriminator_optimizer, loss='binary_crossentropy')
#固定辨別器的引數,這樣可以去訓練生成器
discriminator.trainable = False
gan_input=generator_input
gan_output=discriminator(generator(gan_input))
gan=keras.models.Model(gan_input,gan_output)
#對整個模型選用優化器和損失函式
optimizer=keras.optimizers.RMSprop(lr=0.001,rho=0.9,epsilon=1e-8,decay=0.0)
gan.compile(loss='binary_crossentropy',optimizer=optimizer)
iterations = 1000 #迭代1000次
batch_size = 32 #每批送入32張圖片
save_dir = 'E://Desktop//gan_image//'#為生成器生成的圖片找一個目錄儲存
start=0
for step in range(iterations):
random_latent_vectors = np.random.normal(size=(batch_size, pre_data))
generated_images=generator.predict(random_latent_vectors)#對於輸入得樣本預測輸出
#每次放入一個batch_size的圖片,通過這種索引的方式放入
stop=start+batch_size
real_images=x_train[start:stop]
#聯合生成圖片與真實圖片,生成圖片的標籤設定為1,真實圖片的標籤為0
combined_images = np.concatenate([generated_images, real_images])
labels = np.concatenate([np.ones((batch_size, 1)) , np.zeros((batch_size, 1))])
#給標籤加一個很小的噪聲
labels += 0.05 * np.random.random(labels.shape)
#用正確的標籤去訓練判別器
d_loss = discriminator.train_on_batch(combined_images, labels)
#生成一組假的影象,然後將這組圖片的標籤設定為0(真),用於誤導判別器,讓判別器去判斷這個到底是不是真的。迭代訓練
random_latent_vectors = np.random.normal(size=(batch_size, pre_data))
mislead_targets = np.zeros((batch_size,1))
#訓練整個網路
a_loss = gan.train_on_batch(random_latent_vectors,mislead_targets)
#計數器每次累加一個batch
start += batch_size
#確保送入的圖片能夠被索引到,如果圖片的索引不存在,則會報錯
if start > len(x_train) - batch_size:
start = 0
#列印結果,總體損失和判別器損失
if step%100==0:
print('discriminator loss at step %s: %s' % (step, d_loss))
print('adversarial loss at step %s: %s' % (step, a_loss))
# 儲存生成的圖片
img = image.array_to_img(generated_images[0] * 255., scale=False)
img.save(os.path.join(save_dir, 'generated_dog' + str(step) + '.png'))
# 儲存訓練過程中輸入的真實的圖片,可以形成對比
img = image.array_to_img(real_images[0] * 255., scale=False)
img.save(os.path.join(save_dir, 'real_dog' + str(step) + '.png'))
之後打算用TensorFlow的框架寫一個GAN網路
資料歸一化參考部落格:https://blog.csdn.net/fontthrone/article/details/74067064
GAN網路參考了書籍:deep learning with python