
[置頂]搜尋引擎-一種提示詞推薦演算法
公司最近在開發某行業的垂直搜尋引擎,我作為該專案組的核心成員主要是負責核心演算法的研究工作。我也是剛開始接觸這個行業,目前還處於摸索階段,還有很長的路要走。
言歸正傳,先談一下這個專案的背景。這個專案是一個行業性質的垂直搜尋引擎。使用者分為兩大類:普通使用者、專業使用者。整個專案分為:爬蟲技術組,引擎組,大資料分析組和演算法組。引擎的爬蟲、詞庫的建立和引擎的選型都不是本文的重點,就一筆帶過,重點在於推薦演算法的設計。
一、網路爬蟲
系統的資料,需要從幾個專業網站進行抓取。嘗試了幾個爬蟲,最後選取heritrix最為我們的爬蟲框架,選取它的原因主要是感覺配置項雖然多,但是比較靈活,特別適合我們的要求。當然,爬從技術組也自己嘗試實現了一個爬蟲,主要是爬取
二、詞庫的建立
詞庫初步分為專業主題詞、行業普通詞庫、一般通用詞庫、廢詞庫、還有用於感情分析的詞庫。
專業詞庫的實現前期是採取人工的方式來處理的,並製作了若干的輔助工具,供專業人員來挑選、合併、刪除主題詞的操作。
後面幾種詞庫的實現,是先選用了搜狗等幾種輸入法的詞庫庫為基礎,在這些詞庫的基礎上對爬蟲爬出來的文件進行向量化。
三、引擎的搭建
通過對採集的資料進行去噪、分段、特徵提取,然後把相應的資料匯入到solr裡。
四、推薦演算法
當用戶輸入關鍵詞查詢的時候,如何讓使用者查詢更準確呢?我們設想,針對使用者的輸入,我們如果能給出若干個和使用者輸入的關鍵詞相似度很近的詞,以這些作為查詢條件,如果我們的演算法足夠好,搜尋出來的結果會大大增加檢索的準確度。下面給出具體的演算法思路:
從向量化的角度來看,每一篇文件都對應一個向量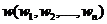 ,其中
,其中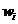 表示特徵項i.
表示特徵項i.
是一個向量由詞、詞的位置、TF等義項來確定的。對於版本1,我們只取了詞、詞的位置。我們先用分類規則,把文件分成若干類,基於每一類進行如下計算:
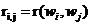 表示兩個特徵項的相似度。
表示兩個特徵項的相似度。
我們定義一下距離公式
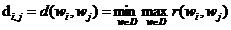
我們對於每個文件的特徵項,兩兩求出特徵項的相似度。通過這個距離公式
我們可以得出,對於每一個分類,以這些特徵項為頂點,以相似度距離為邊,就構
成了如下的無向圖。
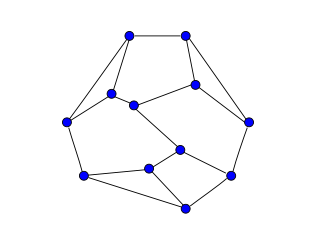
(lawnet)
類比於wordnet和知網的hownet,我們稱這個無向圖,為lawnet。
那我們的設想問題就轉化為:選取任意一個頂點,找出若干個(譬如10個)由這些頂點組成的最小生成樹或者邊權之和最小的最小子圖。這是一個區域性最優的隨機問題。也就是說,我們只需要滿足使用者認可的體驗程度即可,如果概率為90%,也就是說,當用戶輸入10000次,我們能成功給出9000次的提示詞就行了。
目前的解法我嘗試了兩種:
一種PRIM演算法。
第二種演算法:先通過floyd演算法,算出任意兩點的最短距離,作為一個邊;這些邊就組合成一個集合。然後給任意的頂點,從這個邊集合裡找出包含這個頂點的前N個最小邊。