
基於資訊熵的無字典分詞演算法
一、概念介紹
1、詞語分片
設一個文件集 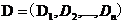 。其中,
。其中,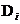 為一個文字,
為一個文字,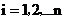 。
。
設  為文件
為文件 的分片集合。其中,
的分片集合。其中,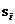 為文件的一個詞語分片,分片就是按step步長對文件進行分割的詞語單位。這裡說的詞語分片可以是一個字、一個詞或者一個長詞。
為文件的一個詞語分片,分片就是按step步長對文件進行分割的詞語單位。這裡說的詞語分片可以是一個字、一個詞或者一個長詞。
譬如:中國隊,
按step=1進行切分 S={中,國,隊}
按step=2進行切分 S={中,國,隊,中國,國隊}
按step=3進行切分 S={中,國,隊,中國,國隊,中國隊}。
當然,這個定義可以推廣到有字典的情況:
譬如 字典 {中國}
"中國國家隊"的詞語分片為{中國,國,家,隊,中國國,國家,家隊,中國國家,國家隊,中國國家隊}。
這樣來看,一個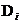
 。
。
2、分片屬性
為了解決上面的問題,對於分片S我們從分片概率、分片頻度、自由度、凝固程度等屬性去考慮。這些屬性都是概率變數。
這樣,一個分片s用6個屬性去進行描述 
引數說明
f: 文件唯一標識
w: 分片的頻度,表示分片在一種切分過程中出現的次數
s: 分片
co: 分片的凝固度
fr: 分片的自由度
st: 分片的概率
3、詞語分片的概率
分片的概率,如果一個字串S長度為L,按stepN進行切分,切分出來的集合為M,為每個分片的頻度。那麼每一個分片的概率可以用下面公式表示:
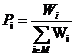 ----------------------------------------------------------(1)
----------------------------------------------------------(1)
S="中國國家的中國隊",長度N = 8 按step=2進行切分,切分為
M={中,國,家,的,隊,中國,國國,國家,家的,的中,國隊}。
| 分片 |
中 |
國 |
家 |
的 |
隊 |
中國 |
國國 |
國家 |
家的 |
的中 |
國隊 |
總計 |
| 頻次 |
2 |
3 |
1 |
1 |
1 |
2 |
1 |
1 |
1 |
1 |
1 |
15 |
| P |
2/15 |
3/15 |
1/15 |
1/15 |
1/15 |
2/15 |
1/15 |
1/15 |
1/15 |
1/15 |
1/15 |
100% |
4、分片的凝固度
要想從一段文字中抽出詞來,我們的第一個問題就是,怎樣的文字片段才算一個詞?大家想到的第一個標準或許是,看這個文字片段出現的次數是否足夠多。我們可以把所有出現頻數超過某個閾值的片段提取出來,作為該語料中的詞彙輸出。不過,光是出現頻數高還不夠,一個經常出現的文字片段有可能不是一個詞,而是多個詞構成的片語。通過我們的資料分析,"的電影"出現了 389 次,"電影院"只出現了 175 次,然而我們卻更傾向於把"電影院"當作一個詞,因為直覺上看,"電影"和"院"凝固得更緊一些。
為了描述這個屬性,我們用一下公式:
 ---------------------------------(2)
---------------------------------(2)
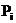 為分片的概率,
為分片的概率, 分片對應的子分片的概率。
分片對應的子分片的概率。
分片"電影院"的概率P(電影院)=0.0005 電影院對應的子分片 {電影,院} 和{電,影院},
"的電影"的凝合程度則是 p(的電影) 分別除以 p(的) · p(電影) 和 p(的電) · p(影) 所得的商的較小值。
光看文字片段內部的凝合程度還不夠,我們還需要從整體來看它在外部的表現。考慮"被子"和"輩子"這兩個片段。我們可以說"買被子"、"蓋被子"、"進被子"、"好被子"、"這被子"等等,在"被子"前面加各種字;但"輩子"的用法卻非常固定,除了"一輩子"、"這輩子"、"上輩子"、"下輩子",基本上"輩子"前面不能加別的字了。"輩子"這個文字片段左邊可以出現的字太有限,以至於直覺上我們可能會認為,"輩子"並不單獨成詞,真正成詞的其實是"一輩子"、"這輩子"之類的整體。可見,文字片段的自由運用程度也是判斷它是否成詞的重要標準。如果一個文字片段能夠算作一個詞的話,它應該能夠靈活地出現在各種不同的環境中,具有非常豐富的左鄰字集合和右鄰字集合。
二、資訊熵和自由度
"資訊熵"是一個非常神奇的概念,它能夠反映知道一個事件的結果後平均會給你帶來多大的資訊量。如果某個結果的發生概率為 p ,當你知道它確實發生了,你得到的資訊量就被定義為 - log(p) 。 p 越小,你得到的資訊量就越大。
設U1…Ui…Un,對應概率為:P1…Pi…Pn,且各種符號的出現彼此獨立。這時,信源的平均不確定性應當為單個符號不確定性-logPi的統計平均值(E),可稱為資訊熵,即
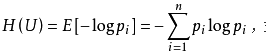 ----------------------------------------------(3)
----------------------------------------------(3)
式中對數一般取2為底,單位為位元。
我們用資訊熵來衡量一個文字片段的左鄰字集合和右鄰字集合有多隨機。考慮這麼一句話"吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮","葡萄"一詞出現了四次,其中左鄰字分別為 {吃, 吐, 吃, 吐} ,右鄰字分別為 {不, 皮, 倒, 皮} 。根據公式,"葡萄"一詞的左鄰字的資訊熵為 - (1/2) · log(1/2) - (1/2) · log(1/2) ≈ 0.693 ,它的右鄰字的資訊熵則為 - (1/2) · log(1/2) - (1/4) · log(1/4) - (1/4) · log(1/4) ≈ 1.04 。可見,在這個句子中,"葡萄"一詞的右鄰字更加豐富一些。
我們不妨就把一個文字片段的自由運用程度定義為它的左鄰字資訊熵和右鄰字資訊熵中的較小值。
 ------------------------------------------(4)
------------------------------------------(4)
通過資訊熵演算法,可以很好的區分一些專有名詞像玫瑰、蝙蝠等,一些地名像紐西蘭、倫敦等,這些自由度較低的詞彙的。
三、演算法的構建
在實際運用中你會發現,文字片段的凝固程度和自由程度,兩種判斷標準缺一不可。只看凝固程度的話,程式會找出"巧克"、"俄羅"、"顏六色"、"柴可夫"等實際上是"半個詞"的片段;只看自由程度的話,程式則會把"吃了一頓"、"看了一遍"、"睡了一晚"、"去了一趟"中的"了一"提取出來,因為它的左右鄰字都太豐富了。
無詞典分詞法的基本步驟:
1. 輸入閥值引數 出現頻數w、凝固程度co、自由程度fr和最大切片stepN,詞典集合的大小N;
2. 對文件集進行預處理,包括:編碼轉換、全半形 處理、字元轉換,再將停用詞、英文字母、數學運算子等其它非漢字字元用佔位符替代;
3. 從文件集裡取一個文件D,按1,2,...,stepN進行切片形成切片集合S;
4. 通過公式(1)計算切片集合S的每一個切片的頻數W和概率P,通過給定頻數閥值過濾;
5. 結果4 中的長度>1的詞語切片,通過公式(2)計算凝固程度,並通過給定的閥值引數過濾。
6. 結果5 中的詞語切片,通過公式(3)計算左鄰右鄰的資訊熵,通過公式(4),得出詞語切片的自由度,並通過給定的閥值引數過濾。
7. 對於結果6,按照分片的頻數倒排序,取前N個,就產生了我們需要的詞典。
四、參考
《基於SNS的文字資料探勘》http://www.matrix67.com/blog/archives/5044