Spark調參優化
前幾節介紹了下常用的函式和常踩的坑以及如何打包程式,現在來說下如何調參優化。當我們開發完一個專案,測試完成後,就要提交到伺服器上執行,但在執行中老是丟擲如下異常,這就很納悶了呀,明明測試上沒問題,咋一到線上就出bug了呢!別急,我們來看下這bug到底怎麼回事~
一、錯誤分析
1、引數設定及異常資訊
18/10/08 16:23:51 WARN TransportChannelHandler: Exception in connection from /10.200.2.95:40888 java.io.IOException: Connection reset by peer at sun.nio.ch.FileDispatcherImpl.read0(Native Method) at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39) at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223) at sun.nio.ch.IOUtil.read(IOUtil.java:192) at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:380) at io.netty.buffer.PooledUnsafeDirectByteBuf.setBytes(PooledUnsafeDirectByteBuf.java:221) at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:899) at io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(NioSocketChannel.java:275) at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:119) at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:652) at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:575) at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:489) at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:451) at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:140) at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:144) at java.lang.Thread.run(Thread.java:745) 18/10/08 16:23:51 ERROR TransportResponseHandler: Still have 1 requests outstanding when connection from /10.200.2.95:40888 is closed
2、分析原因
執行的程式其實邏輯上比較簡單,只是從hive表裡讀取的資料量很大,差不多60+G,並且需要將某些hive表讀取到dirver節點上,用來獲取每個executor上某些資料的對映值,所以driver設定的資源較大。執行時丟擲的異常資訊,從網上查了下原因大致是伺服器的併發連線數超過了其承載量,伺服器會將其中一些連線Down掉,這也就是說在執行spark程式時,過多的申請資源併發執行。那應該怎樣去合理設定引數才能最大化提升併發的效能呢?這些引數又分別代表什麼?
二、常見引數及含義
| 常用引數 |
含義及建議 |
| spark.executor.memory (--executor-memory) |
含義:每個執行器程序分配的記憶體 建議:該設定需要和下面的executor-num數一起考慮,一般設定為4G~8G如果和其他人共用佇列,為防止獨佔資源建議memory*num <= 資源佇列最大總記憶體*(1/2~1/3) |
| spark.executor.num (--executor-num) |
含義:設定用來執行spark作業的執行器程序的個數 建議:一般設定為50~100個,設定太少會導致無法充分利用資源,太多又導致大部分任務分配不到充足的資源 |
| spark.executor.cores (--executor-cores) |
含義:每個執行器程序的cpu core數量,決定了執行器程序併發執行task執行緒的個數,一個core同一時間只能執行一個task執行緒。如果core數量越多,完成自己task越快。 建議:一般設定2~4個,需要和executor-num一起考慮,num*core<=佇列總core*(1/2~1/3) |
| spark.driver.memory (--driver-memory) |
含義:設定驅動程序的記憶體 建議:driver一般不設定,預設的就可以,不過如果你在程式中需要使用collect運算元拉取rdd到驅動節點上,那就得設定相應的記憶體大小(大於幾十k建議使用廣播變數) |
| spark.default.parallelism | 含義:設定每個stage的預設任務數量 建議:官方建議設定為 executor-num*executor-cores的2~3倍 |
| spark.storage.memoryFraction | 含義:預設Executor 60%的記憶體,可以用來儲存持久化的RDD資料 建議:spark作業中,如果有較多rdd需要持久化,該引數可適當提高一些,保證持久化的資料儲存在記憶體中,避免被寫入磁碟影響執行速度。如果shuffle類操作較多,可調低該引數。並且如果由於頻繁的垃圾回收導致執行緩慢,證明執行task的記憶體不夠用,建議調低該引數。 |
| spark.shuffle.memoryFraction | 含義:設定shuffle過程中一個task拉取到上個stage的task的輸出後,進行聚合操作時能夠使用的Executor記憶體的比例 建議:shuffle操作在進行聚合時,如果發現使用的記憶體超出了這個20%的限制,那麼多餘的資料就會溢寫到磁碟檔案中去,此時就會極大地降低效能。結合上一個引數調整。 |
| spark.speculation | 含義:設為true時開啟task預測執行機制。當出現較慢的任務時,這種機制會在另外的節點嘗試執行該任務的一個副本。 建議:true,開啟此選項會減少大規模叢集中個別較慢的任務帶來的影響。 |
| spark.storage.blockManagerTimeoutIntervalMs | 含義:內部通過超時機制追蹤執行器程序是否存活的閾值。 建議:對於會引發長時間垃圾回收(GC)暫停的作業,需要把這個值調到100秒(100000)以防止失敗。 |
| spark.sql.shuffle.partitions | 含義:配置join或者聚合操作shuffle資料時分割槽的數量,預設200 建議:同spark.default.parallelism |
三、實踐
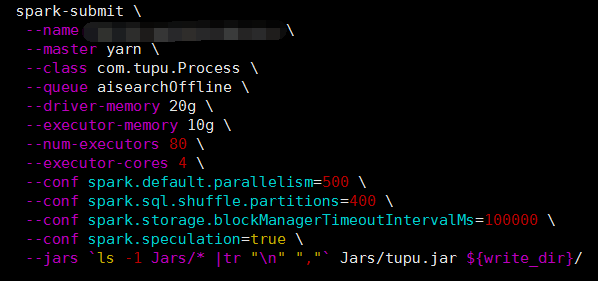
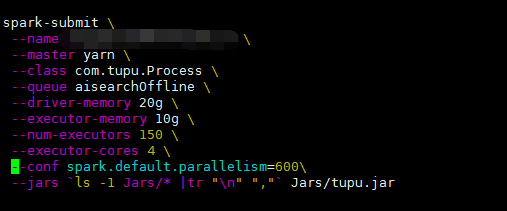
通過適當調整以上講到的幾個引數,降低spark.default.parallelism的同時又設定了spark.sql.shuffle.partitions、spark.speculation、spark.storage.blockManagerTimeoutIntervalMs三個引數。由於專案中頻繁的讀取hive表資料,並進行連線操作,所以在shuffle階段增大了partitions。對於woker傾斜,設定spark.speculation=true,把預測不樂觀的節點去掉來保證程式可穩定執行,通過這幾個引數的調整這樣並大大減少了執行時間。