
編譯原理實驗四 語法分析程式
實驗四 語法分析程式
(一)學習經典的語法分析器(1學時)
一、實驗目的
學習已有編譯器的經典語法分析源程式。
二、實驗任務
閱讀已有編譯器的經典語法分析源程式,並測試語法分析器的輸出。
三、實驗內容
(1)選擇一個編譯器,如:TINY,其它編譯器也可(需自備原始碼)。
(2)閱讀語法分析源程式,加上你自己的理解。尤其要求對相關函式與重要變數的作用與功能進行稍微詳細的描述。若能加上學習心得則更好。TINY語言請參考《編譯原理及實踐》第3.7節。對TINY語言要特別注意抽象語法樹的定義與應用。
(3)測試語法分析器。對TINY語言要求輸出測試程式的字元形式的抽象語法樹。(手工或程式設計)畫出圖形形式的抽象語法樹。
TINY語言:
測試用例一:sample.tny。
(二)實現一門語言的語法分析器(3學時)
一、實驗目的
通過本次實驗,加深對語法分析的理解,學會編制語法分析器。
二、實驗任務
用C或C++語言編寫一門語言的語法分析器。
三、實驗內容
(1)語言確定:C-語言,其定義在《編譯原理及實踐》附錄A中。也可選擇其它語言,不過要有該語言的詳細定義(可仿照C-語言)。一旦選定,不能更改,因為要在以後繼續實現編譯器的其它部分。鼓勵自己定義一門語言。也可選擇TINY語言,但需要使用與TINY現有語法分析程式碼不同的分析演算法實現,並在實驗報告中寫清原理。
(2)完成C-語言的BNF文法到EBNF文法的轉換。通過這一轉換,消除左遞迴,提取左公因子,將文法改寫為LL(1)文法,以適用於自頂向下的語法分析。規劃需要將哪些非終結符寫成遞迴下降函式。
(3)為每一個將要寫成遞迴下降函式的非終結符,如:變數宣告、函式宣告、語句序列、語句、表示式等,定義其抽象語法子樹的形式結構,然後定義C-語言的語法樹的資料結構。
(4)仿照前面學習的語法分析器,編寫選定語言的語法分析器。可以自行選擇使用遞迴下降、LL(0)、LR(0)、SLR、LR(1)中的任意一種方法實現。
(5)準備2~3個測試用例,測試並解釋程式的執行結果。
實驗過程
學習tiny語言的語法分析器
TINY有兩種基本的結構型別:語句和表示式。語句共有5類:(if語句、repeat語句、assign語句、read語句和read語句),表示式共有3類(算符標的是、常量表達式和識別符號表示式)。因此,語法樹節點首先安裝它是語句還是表示式來進行分類,接著根據語句或表示式的種類進行再次分類。
樹節點最大可有3個孩子的結構(僅在帶有else部分的if
語句才用到)。語句通過同屬域而不是子域來排序,即由父親到他的孩子的唯一物理連線是到最左孩子的。孩子則在一個標準連線表中自左向右連線到一起,這種連線稱作同屬連線,用於區別父子連線。
設計流程:
-
建立一個樹節點的結構體
-
使用遞迴下降演算法,將每一個文法產生式轉變成遞迴函式中的一個子句
-
用前看符號指導產生式規則的選擇
-
建立一個match函式,對前看符號進行匹配,如果不匹配,呼叫syntaxError函式對錯誤語法進行報錯。
-
創一個printTree函式,將一個語法樹打印出來。
實現C-語言的語法分析器
- 完成C-語言的BNF文法到EBNF文法的轉換。通過這一轉換,消除左遞迴,提取左公因子,將文法改寫為LL(1)文法,以適用於自頂向下的語法分析。規劃需要將哪些非終結符寫成遞迴下降函式。
C-語言BNF語法:
EBNF語法:
a) program→declaration-list
b) declaration_list → declaration{ declaration }
c) declaration→var-declaration|fun-declaration
d) var_declaration →type-specifier ID; | type-specifier ID [NUM];
e) type - specifier → int | void
f) fun-declatation→type-specifier ID (params) compound-stmt
g) params→param_list | void
h) param_list→param{, param}
i) param→ type-specifier ID{[ ]}
j) compound-stmt→{ local-declaration statement-list}
k) local-declarations → empty {var- declaration}
l) statement-list→{statement}
m) statement→expression-stmt | compound-stmt | selection-stmt | iteration-stmt | return-stmt
n) expression-stmt→ [expression];
o) selection-stmt→if (expression) statement [else statement]
p) iteration-stmt→while (expression)statement
q) return-stmt→return [expression];
r) expression→ var = expression | simple-expression
s) relop → < = | < | > | > = | = = | ! =
t) var→ID | ID [expression]
u) simple-expression>additive-expression{ relop additive-expression }
v) additive-expression→term{addop term }
w) addop → + | -
x) term→factor{mulop factor }
y) mulop →* | /
z) factor→(expression) | var | call | NUM
aa) call→ID( args )
bb) args→arg-list | empty
cc) arg-list→ expression{, expression}
2. 建立一個樹節點,treeNode定義 包括子節點、兄弟節點、所處行號、節點型別、屬性、表示式返回型別
3. 定義各類所需的資料型別,有些資料型別在詞法分析器中已經完成,可以直接使用。
4. 使用遞迴下降演算法,將每一個文法產生式轉變成遞迴函式中的一個子句
- 建立一個match函式,對前看符號進行匹配,如果不匹配,呼叫syntaxError函式對錯誤語法進行報錯。
- 創一個printTree函式,將一個語法樹打印出來。
- 其他一些非主要函式,繼承了上次詞法分析器的程式碼。如字元讀取等。而且整個實驗是建立在詞法分析得基礎上的。詞法分析的結果對於語法分析是必不可少的
實驗結果:

C-語言:
測試樣例一:

測試結果:
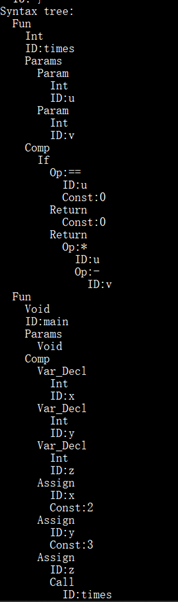
原始碼太長了,就不貼上來了。大家需要的可以去下載。
C-語言語法分析程式