
資料結構與演算法學習--雜湊
一、雜湊衝突的解放方法?
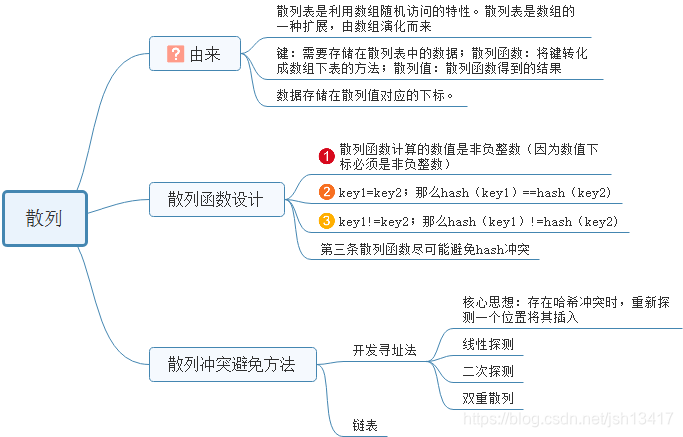
1.常用的雜湊衝突解決方法有2類:開放定址法(open addressing)和連結串列法(chaining)
2.開放定址法(參考連結)
①核心思想:如果出現雜湊衝突,就重新探測一個空閒位置,將其插入。
②線性探測法(Linear Probing):
插入資料:當我們往散列表中插入資料時,如果某個資料經過雜湊函式之後,儲存的位置已經被佔用了,我們就從當前位置開始,依次往後查詢,看是否有空閒位置,直到找到為止。
查詢資料:我們通過雜湊函式求出要查詢元素的鍵值對應的雜湊值,然後比較陣列中下標為雜湊值的元素和要查詢的元素是否相等,若相等,則說明就是我們要查詢的元素;否則,就順序往後依次查詢。如果遍歷到陣列的空閒位置還未找到,就說明要查詢的元素並沒有在散列表中。
刪除資料:為了不讓查詢演算法失效,可以將刪除的元素特殊標記為deleted,當線性探測查詢的時候,遇到標記為deleted的空間,並不是停下來,而是繼續往下探測。
結論:最壞時間複雜度為O(n)
③二次探測(Quadratic probing):線性探測每次探測的步長為1,即在陣列中一個一個探測,而二次探測的步長變為原來的平方。
④雙重雜湊(Double hashing):使用一組雜湊函式,直到找到空閒位置為止。
⑤線性探測法的效能描述:
用“裝載因子”來表示空位多少,公式:散列表裝載因子=填入表中的個數/散列表的長度。
裝載因子越大,說明空閒位置越少,衝突越多,散列表的效能會下降。
3.連結串列法(更常用)
插入資料:當插入的時候,我們需要通過雜湊函式計算出對應的雜湊槽位,將其插入到對應的連結串列中即可,所以插入的時間複雜度為O(1)。
查詢或刪除資料:當查詢、刪除一個元素時,通過雜湊函式計算對應的槽,然後遍歷連結串列查詢或刪除。對於雜湊比較均勻的雜湊函式,連結串列的節點個數k=n/m,其中n表示散列表中資料的個數,m表示散列表中槽的個數,所以是時間複雜度為O(k)。
程式碼實現可以參考github地址(參考linux核心hashtab實現):
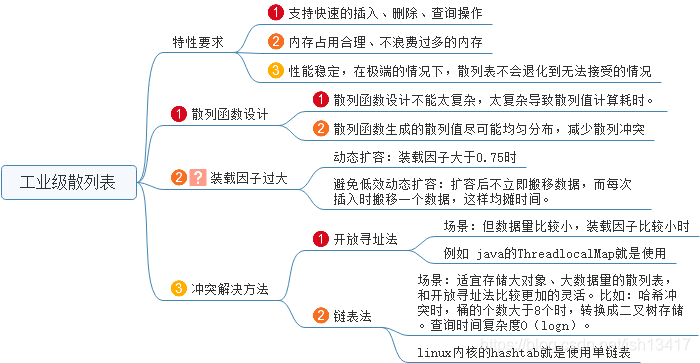
二、如何設計一個工業級的雜湊函式
如何設計一個可以應對各種異常的工業級別的散列表,來避免在雜湊衝突的情況下,散列表的效能急速下降。我們從以下幾個方面來考慮:
三、為什麼散列表和連結串列實現LRU快取淘汰演算法
我們可以利用散列表和雙向連結串列來實現LRU快取淘汰演算法,將時間複雜度降低0(1)。
下面是我用C語言實現Java LinkedHashMap的功能LRU快取淘汰演算法的功能。
雙向連結串列的實現可以直接使用核心的函式:linux核心原始碼雙向連結串列實現include/linux/list.h
具體結構體定義和實現可以參考檢視github程式碼
四 雜湊演算法的應用
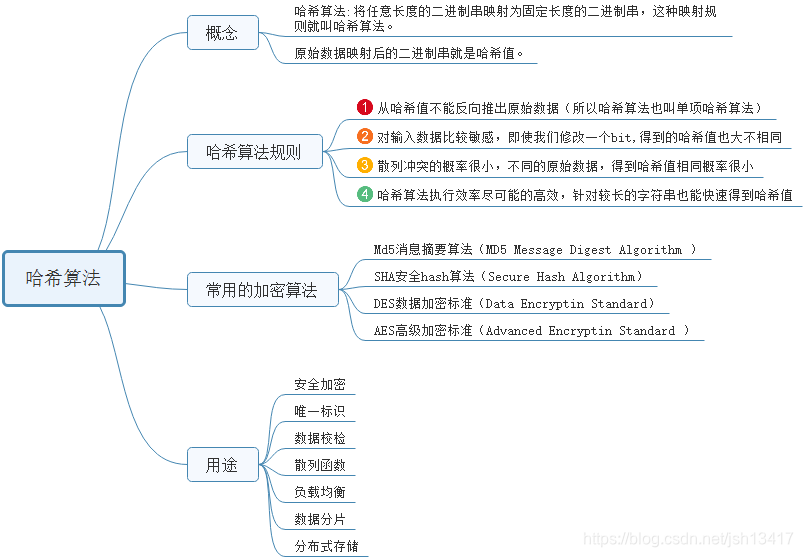
1、安全加密:
四、思考
1.Word文件中單詞拼寫檢查功能是如何實現的?
字串佔用記憶體大小為8位元組,20萬單詞佔用記憶體大小不超過20MB,所以用散列表儲存20萬英文詞典單詞,然後對每個編輯進文件的單詞進行查詢,若未找到,則提示拼寫錯誤。
2.假設我們有10萬條URL訪問日誌,如何按照訪問次數給URL排序?
字串佔用記憶體大小為8位元組,10萬條URL訪問日誌佔用記憶體不超過10MB,通過散列表統計url訪問次數,然後用TreeMap儲存散列表的元素值(作為key)和陣列下標值(作為value)
3.有兩個字串陣列,每個陣列大約有10萬條字串,如何快速找出兩個陣列中相同的字串?
分別將2個數組的字串通過雜湊函式對映到散列表,散列表中的元素值為次數。注意,先儲存的陣列中的相同元素值不進行次數累加。最後,統計散列表中元素值大於等於2的雜湊值對應的字串就是兩個陣列中相同的字串。
1、
2、開地址hash實現
參考文章:
[1] http://www.nowamagic.net/academy/detail/3008086
[2] http://blog.csdn.net/freetourw/article/details/53493616
[3] http://blog.chinaunix.net/uid-27213819-id-3794127.html
;